Clear Sky Science · pl
CGDFNet: sieć do semantycznej segmentacji w czasie rzeczywistym z dwoma gałęziami i kontekstowo prowadzonym łączeniem detali
Nauczanie samochodów widzenia całej ulicy
Nowoczesne samochody i roboty coraz częściej polegają na kamerach, by rozumieć otoczenie — rozpoznawać drogi, chodniki, ludzi, pojazdy i znaki w czasie rzeczywistym. W artykule przedstawiono CGDFNet, nowy system widzenia komputerowego zaprojektowany do wykonywania takiego „rozumienia sceny” szybciej i dokładniej, zwłaszcza na zatłoczonych ulicach miejskich. Uczący się równocześnie zachowywać zarówno drobne detale (np. słupki sygnalizacji albo koła roweru), jak i układ całościowy (np. drogi i budynki), CGDFNet ma na celu zwiększenie bezpieczeństwa i niezawodności automatyzacji jazdy oraz innych zadań wizyjnych pracujących w czasie rzeczywistym.
Dlaczego widzenie na poziomie pikseli jest tak wymagające
W semantycznej segmentacji system przypisuje kategorię do każdego piksela obrazu: droga, samochód, pies, niebo itd. To znacznie trudniejsze niż narysowanie prostokąta wokół samochodu, ponieważ system musi precyzyjnie odwzorować granice obiektów i drobne kształty. Istnieje wiele metod o wysokiej dokładności, ale zwykle są wolne i energochłonne, co jest nieoptymalne dla systemów działających w czasie rzeczywistym w samochodach, dronach czy urządzeniach noszonych. Z drugiej strony, lekkie metody działające szybko często kosztem tracą szczegóły lub kontekst, mając problemy z małymi obiektami, cienkimi strukturami czy zatłoczonymi scenami miejskimi.
Dwie ścieżki: jedna dla detalu, druga dla kontekstu
CGDFNet rozwiązuje ten dylemat za pomocą konstrukcji z dwiema gałęziami: jedna gałąź koncentruje się na ostrych detalach, a druga przechwytuje szeroki kontekst. W oparciu o wydajny backbone, niższe warstwy przekazują informacje do „gałęzi detali”, która utrzymuje wyższą rozdzielczość, by zachować krawędzie i tekstury. Głębsze warstwy zasilają „gałąź kontekstu”, która ogląda scenę w bardziej skompresowanej formie, dobrej do zrozumienia ogólnej struktury i relacji między obiektami. W przeciwieństwie do wcześniejszych projektów z dwiema gałęziami, które w dużej mierze utrzymywały strumienie osobno i łączyły je dopiero na końcu w prosty sposób, CGDFNet zachęca do komunikacji między nimi już w trakcie przetwarzania, tak aby drobne detale były stale sprawdzane względem wiedzy sieci o całej scenie.
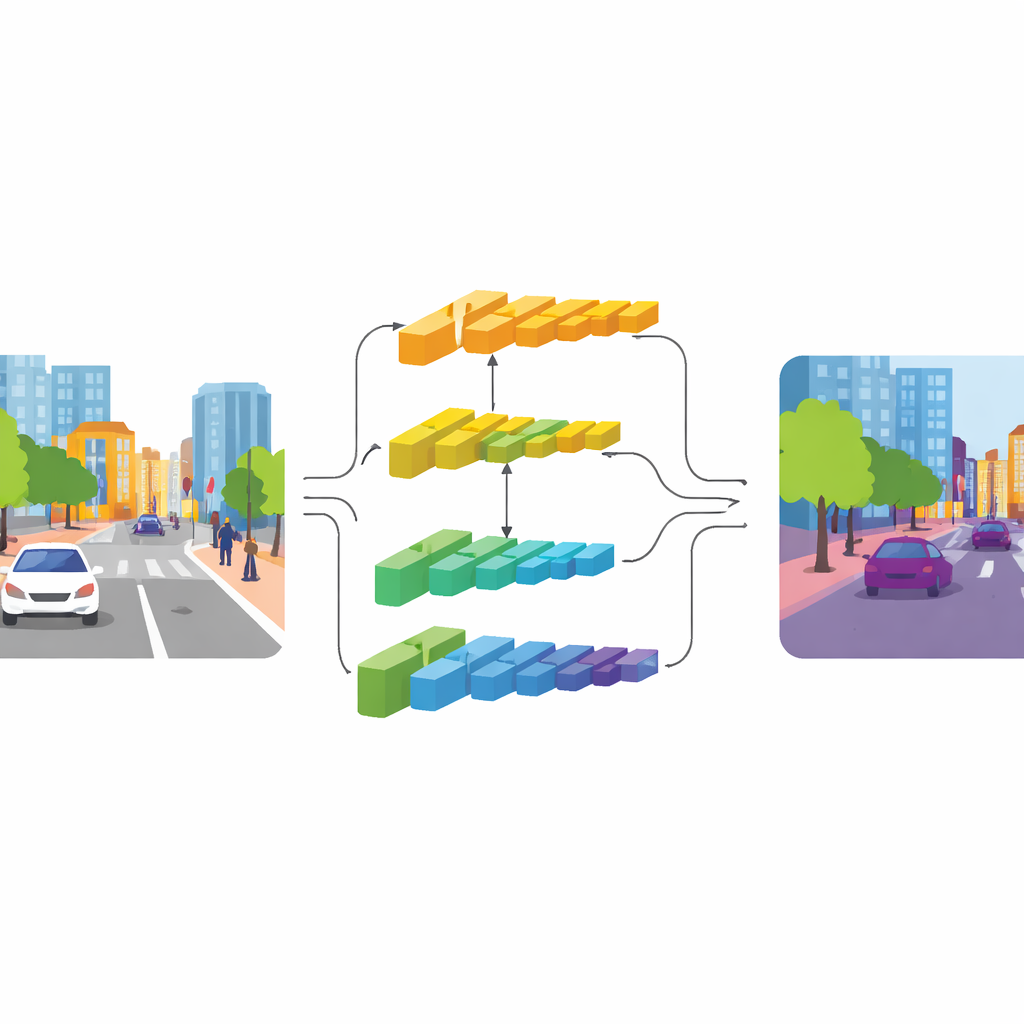
Prowadzenie detali przez znaczenie
Dwa kluczowe komponenty wzmacniają tę interakcję. W gałęzi kontekstu moduł Semantic Refinement Module uczy się wyróżniać najbardziej informacyjne regiony i kanały w swoich mapach cech. Robi to, łącząc lokalne sygnały (jakie części sceny są aktywne w swoim sąsiedztwie) z sygnałami globalnymi (co sieć widzi w całym obrazie), dzięki czemu reprezentacja zawiera zarówno szczegóły sąsiedztwa, jak i znaczenie na poziomie sceny. W gałęzi detali moduł Context‑Guided Detail Module wykorzystuje te informacje semantyczne, aby kierować uwagę na krawędzie i drobne struktury istotne, takie jak kontur autobusu czy rama roweru. Opiera się na specjalnym rodzaju splotu bardziej czułym na zmiany między sąsiednimi pikselami, co naturalnie uwypukla kontury i małe obiekty bez dodawania wielu dodatkowych parametrów.
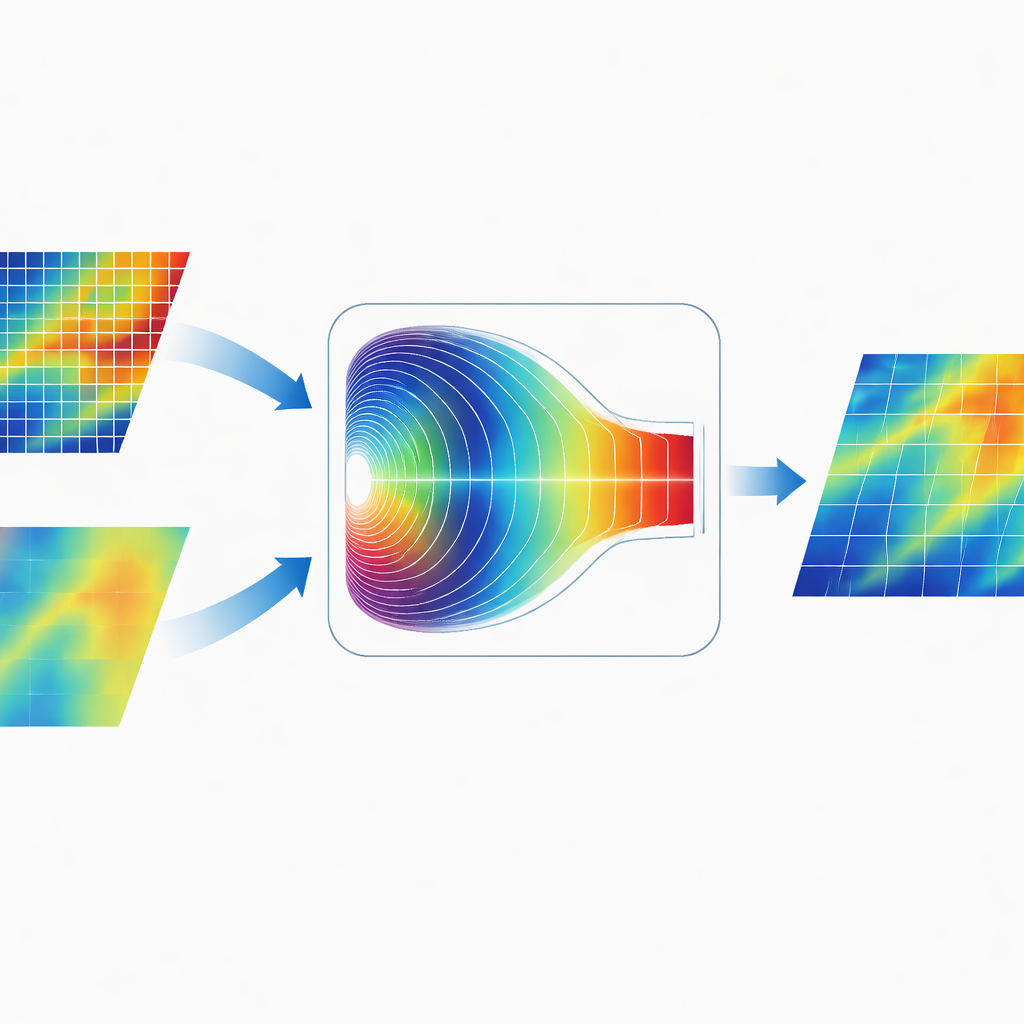
Mieszanie informacji w świecie częstotliwości
Charakterystyczną cechą CGDFNet jest sposób łączenia obu gałęzi. Zamiast po prostu dodawać ich mapy w przestrzeni obrazu, autorzy zaprojektowali Fourier‑Domain Adaptive Fusion Module. Moduł ten tymczasowo przekształca połączone cechy do domeny częstotliwości, gdzie wzorce są reprezentowane jako wolne, szerokie zmiany oraz szybkie, ostre skoki. Adaptacyjny mechanizm bramek uczy się wtedy, które składowe częstotliwości podkreślać z gałęzi detali, a które z gałęzi kontekstu. Po takim ważeniu cechy są transformowane z powrotem, co daje reprezentację łącącą ostre krawędzie ze spójną strukturą globalną skuteczniej niż tradycyjne fuzje ograniczone do przestrzeni obrazowej.
Wyniki na prawdziwych ulicach
Zespół przetestował CGDFNet na dwóch powszechnie używanych benchmarkach scen miejskich: Cityscapes, zbiorze z europejskich miast, oraz CamVid, zarejestrowanym z perspektywy kierowcy w Wielkiej Brytanii. CGDFNet przetwarzał duże obrazy w czasie rzeczywistym — około 88 klatek na sekundę na Cityscapes i około 129 klatek na sekundę na CamVid — osiągając dokładność segmentacji porównywalną lub przewyższającą wiele systemów z czołówki. Szczególnie dobrze radził sobie z kategoriami, które zwykle trudno segmentować, takimi jak ogrodzenia, znaki drogowe, autobusy i rowery, gdzie zachowanie precyzyjnych granic i drobnych struktur jest kluczowe.
Co to oznacza dla codziennej technologii
W praktyce CGDFNet pokazuje, że możliwe jest zbudowanie systemów wizyjnych jednocześnie wystarczająco szybkich do pracy w czasie rzeczywistym i na tyle skrupulatnych, by odtwarzać małe, krytyczne dla bezpieczeństwa detale w złożonych scenach miejskich. Łącząc gałąź skupioną na detalach, gałąź skupioną na kontekście oraz inteligentny etap fuzji w domenie częstotliwości, sieć utrzymuje zrównoważony obraz ulicy: wie, gdzie wszystko się znajduje i gdzie zaczyna się i kończy każdy obiekt. Chociaż wyzwania pozostają — na przykład sceny z gęsto zgromadzonymi tłumami czy złe warunki pogodowe — podejście to daje obiecujący wzorzec dla przyszłego widzenia realizowanego na urządzeniu, od samochodów autonomicznych po inteligentne kamery drogowe i roboty asystujące.
Cytowanie: Zhao, S., Fu, W., Gao, J. et al. CGDFNet: a dual-branch real-time semantic segmentation network with context-guided detail fusion. Sci Rep 16, 9191 (2026). https://doi.org/10.1038/s41598-026-39370-1
Słowa kluczowe: semantyczna segmentacja w czasie rzeczywistym, wizja dla autonomicznej jazdy, sieć neuronowa z dwiema gałęziami, fuzja cech w domenie Fouriera, rozumienie scen miejskich