Clear Sky Science · pl
End-to-end konwolucyjna sieć neuronowa do bezpiecznego przesyłania obrazów poprzez łączną szyfrowanie i steganografię
Dlaczego ukrywanie obrazów w obrazach ma znaczenie
Codziennie szpitale, banki i zwykli ludzie przesyłają przez internet ogromne liczby zdjęć — od skanów medycznych po dowody tożsamości i rodzinne fotografie. Zachowanie prywatności tych obrazów zwykle oznacza zaszyfrowanie ich, co sprawia, że wyglądają jak losowy szum, lub ukrycie ich w innych obrazach, trik nazywany steganografią. Każde z podejść ma słabość: zaszyfrowane obrazy przyciągają uwagę, a ukryte obrazy mogą zostać ujawnione przez inteligentną analizę. W artykule przedstawiono nowy system oparty na uczeniu głębokim, który łączy oba pomysły, dążąc do wysyłania tajnych obrazów w sposób naturalny dla oka ludzkiego, a jednocześnie trudny do złamania przez atakujących.
Problem z dzisiejszymi metodami ochrony
Tradycyjne narzędzia szyfrujące, takie jak AES i DES, są matematycznie silne, lecz zamieniają zdjęcie w blok wizualnego szumu, co jasno sygnalizuje: „tutaj ukryto coś ważnego”. Klasyczna steganografia robi odwrotnie: chowa informacje w drobnych detalach obrazu o normalnym wyglądzie, ale często bez solidnej ochrony kryptograficznej. Jeśli atakujący wykryje sztuczkę, ukrytą wiadomość można łatwo wydobyć. Nowe metody oparte na uczeniu głębokim poprawiły albo szyfrowanie, albo ukrywanie, jednak większość traktuje te zadania jako dwa oddzielne kroki. To rozdzielenie marnuje zasoby obliczeniowe i może powodować, że błędy z jednej fazy wpływają na drugą. Autorzy twierdzą, że brakuje jednego systemu, który uczy się end-to-end, jak jednocześnie zamaskować i zabezpieczyć obrazy.
Jeden „mózg”, który miesza i ukrywa
Naukowcy zaprojektowali end-to-end konwolucyjną sieć neuronową — w praktyce trenowalny potok przetwarzania obrazu — która przyjmuje dwa obrazy: zwykłe „okładkowe” (cover) zdjęcie oraz „sekretny” obraz do ochrony. Najpierw specjalny moduł zwany KeyMixer przekształca obraz sekretu za pomocą trenowalnych kluczy numerycznych. W przeciwieństwie do stałych, ręcznie zaprojektowanych szyfrów, mixer uczy się zmian zależnych od zawartości, uwzględniając tekstury i kształty w obrazie, wprowadzając subtelne, nieoczywiste zniekształcenia. Następnie sieć Encoder delikatnie miesza przekształcony sekret z okładką, tworząc obraz „kontenera”, który wciąż powinien wyglądać naturalnie. Po stronie odbiorczej dopasowana sieć Decoder korzysta tylko z obrazu kontenera, aby odtworzyć ukryty sekret, bez potrzeby dodatkowych kluczy czy informacji towarzyszących w fazie odzyskiwania.
Nauczanie sieci równowagi między tajnością a wyglądem
Trenowanie systemu polega na jednoczesnym dążeniu do dwóch celów: utrzymaniu obrazu kontenera wizualnie zbliżonego do oryginalnej okładki oraz jak najdokładniejszym odtworzeniu obrazu sekretu. Autorzy realizują to za pomocą strategii z podwójną funkcją kosztu, która karze zarówno widoczne zmiany w okładce, jak i błędy w rekonstruowanym sekrecie. Wykorzystują popularny zbiór zdjęć naturalnych, zestaw STL‑10, oraz standardowe techniki augmentacji danych, takie jak odbicia i niewielkie obroty, by sieć widziała zróżnicowane sceny. W trakcie treningu model stopniowo się poprawia, aż oba cele się stabilizują, co pokazuje, że potrafi znaleźć praktyczny kompromis między niewidocznością a wiernym odzyskiem.
Jak dobrze ukryte obrazy przetrwają
Aby ocenić jakość, zespół mierzy podobieństwo obrazów kontenera do okładek oraz zgodność odtworzonych sekretów z oryginałami, używając standardowych miar jakości obrazu. Na obrazach testowych metoda osiąga wysoką strukturalną podobieństwo (SSIM) zarówno dla okładki, jak i sekretu, z wartościami powyżej 0,90, co oznacza, że kształty i detale są w dużej mierze zachowane. Obrazy sekretu w szczególności osiągają bardzo wysokie podobieństwo, wskazując na niemal perfekcyjne percepcyjne odtworzenie. W porównaniu z kilkoma nowoczesnymi systemami steganografii opartymi na uczeniu głębokim i hybrydowymi potokami, nowy model end-to-end daje najlepsze rekonstrukcje obrazów sekretu, nawet jeśli niektórzy rywale nieznacznie lepiej zachowują okładkę. Testy statystyczne rozkładów pikseli, losowości i wrażliwości na zmiany sugerują, że kontenery nie ujawniają oczywistych wskazówek, iż coś jest ukryte.
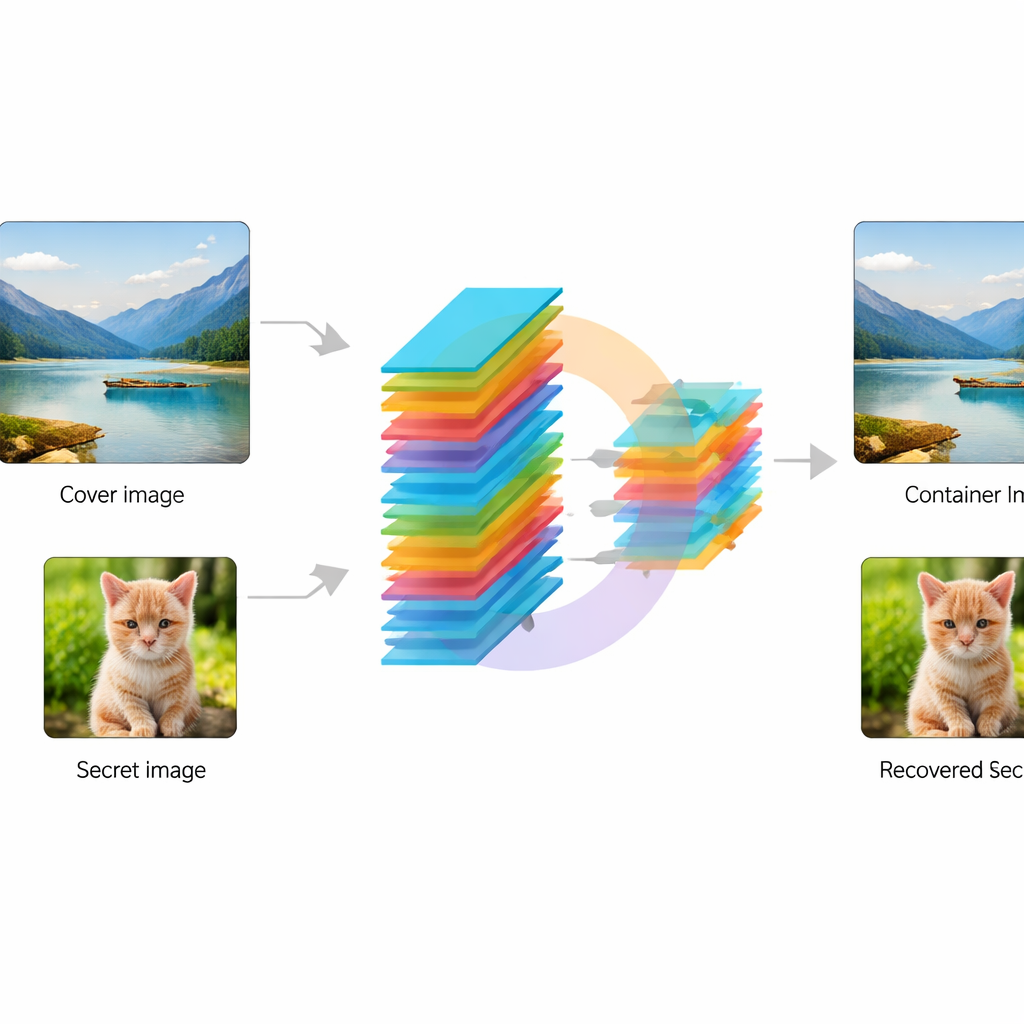
Co to może znaczyć dla prywatności na co dzień
Mówiąc prościej, praca pokazuje, że pojedynczy model uczenia głębokiego może nauczyć się jednocześnie maskować i chronić obrazy tak, że ukryty obraz można odzyskać z dużą przejrzystością, podczas gdy udostępniony obraz nadal wygląda zwyczajnie. Zamiast łączyć szyfrowanie i steganografię w nieporęcznym łańcuchu, system uczy się płynnego kompromisu między subtelnością wizualną a bezpieczeństwem. Chociaż obecnie wymaga wydajnego sprzętu i dalszych testów przeciw zaawansowanym atakom, podejście to wskazuje drogę do przyszłych narzędzi, które mogłyby dyskretnie zabezpieczać skany medyczne, zdjęcia osobiste lub inne wrażliwe obrazy w rutynowej komunikacji online, nie zdradzając przy tym, że cokolwiek jest ukryte.
Cytowanie: Iqbal, A., Sattar, H., Shafi, U.F. et al. An end-to-end convolutional neural network for secure image transmission via joint encryption and steganography. Sci Rep 16, 8228 (2026). https://doi.org/10.1038/s41598-026-39351-4
Słowa kluczowe: bezpieczeństwo obrazów, steganografia, uczenie głębokie, szyfrowanie neuronowe, ochrona prywatności