Clear Sky Science · pl
Parsowanie adresów pacjentów za pomocą kontrastowego uczenia z uwzględnieniem grafu wiedzy i ograniczonego wnioskowania LLM na miejscu
Dlaczego uporządkowane adresy pacjentów mają znaczenie
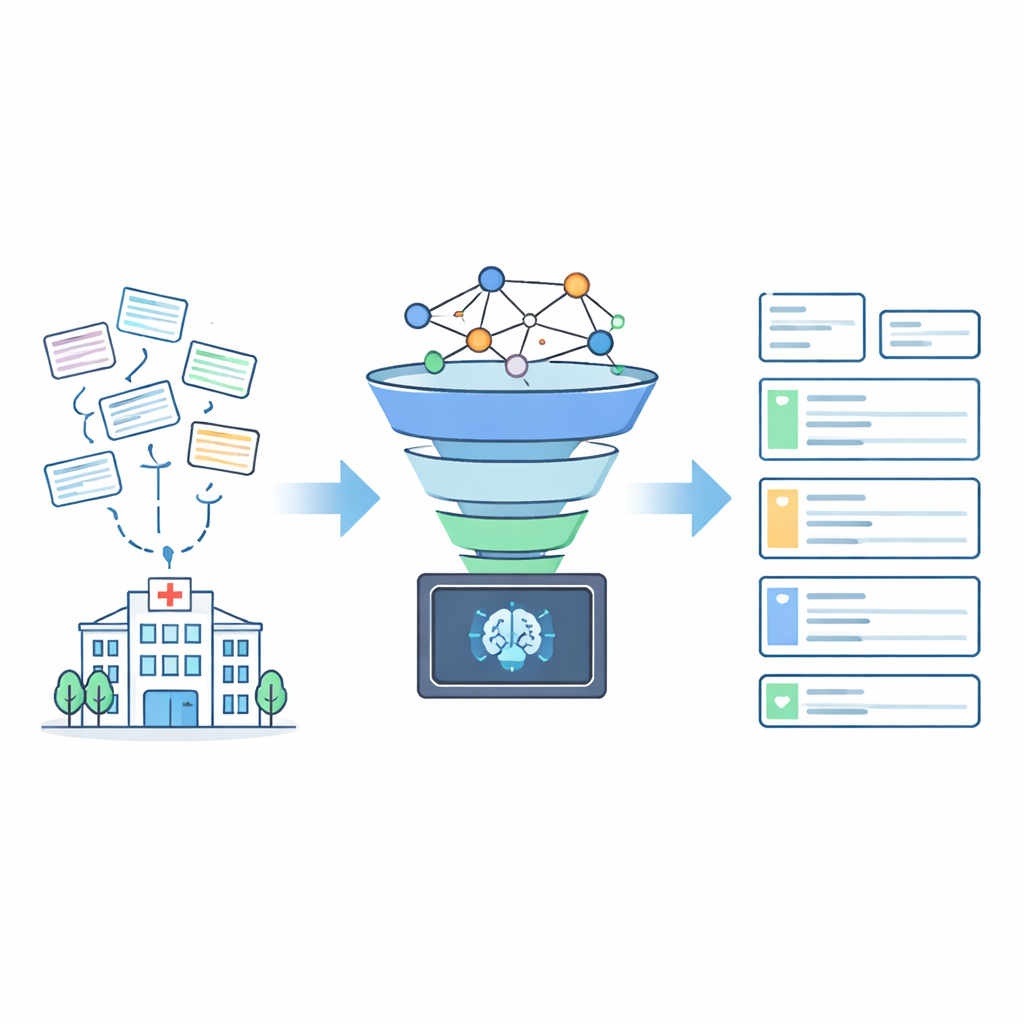
Za każdą wizytą w szpitalu kryje się skromna linia tekstu: adres domowy pacjenta. To nie tylko kwestia biurokracji — adresy te napędzają mapowanie chorób, planowanie działań ratunkowych oraz decyzje o lokalizacji przychodni i karetek. W wielu systemach dokumentacji medycznej adresy są jednak przechowywane jako nieuporządkowany, niespójny tekst pełen skrótów, literówek i brakujących elementów. W artykule przedstawiono AddrKG‑LLM, nową metodę, która zamienia taki nieporządny tekst adresowy w czyste, wiarygodne rekordy, jednocześnie zachowując prywatność wrażliwych danych.
Problem z nieuporządkowanymi adresami domowymi
Gdy adresy są wpisywane swobodnie, osoby pomijają dzielnice, zamieniają kolejność słów albo używają lokalnych nazw, których oficjalne mapy nie rozpoznają. Starsze metody komputerowe porównują łańcuchy znaków znak po znaku lub traktują je jako proste listy słów, co działa jedynie wtedy, gdy dane wejściowe są już uporządkowane i kompletne. Nowsze systemy głębokiego uczenia lepiej rozumieją kontekst, ale nadal mogą się potknąć na nietypowych sformułowaniach i wymagają dużej mocy obliczeniowej. Ostatnio duże modele językowe wykazały imponujące umiejętności rozumienia i generowania tekstu. Jednak gdy mogą odpowiadać swobodnie, często „halucynują” szczegóły, które nie występują w danych — co jest niedopuszczalnym ryzykiem w opiece zdrowotnej, gdzie dokumentacja musi być precyzyjna i audytowalna.
Dwustopniowa ścieżka od chaosu do porządku
Naukowcy zaprojektowali AddrKG‑LLM jako dwustopniowy proces, który dodaje strukturę i zabezpieczenia wokół modelu językowego, zamiast pozwalać mu działać samodzielnie. Najpierw przychodzące adresy pacjentów są oczyszczane w celu usunięcia silnie identyfikujących detali, takich jak numery budynków i pokoi czy numery telefonów, co pomaga chronić prywatność. Pozostały tekst jest konwertowany na gęstą reprezentację numeryczną, która uchwyca jego znaczenie. Równolegle zespół buduje graf wiedzy — sieć przypominającą mapę, która koduje oficjalne relacje między miastami, dzielnicami, ulicami i osiedlami. Dzięki technice zwanej uczeniem kontrastowym trenują system tak, aby adresy odnoszące się do tej samej rzeczywistej lokalizacji były blisko siebie w tej wspólnej przestrzeni, a niepowiązane miejsca — od siebie oddalone. To pozwala systemowi szybko pobierać krótką listę prawdopodobnych kandydatów adresowych dla każdego nowego rekordu pacjenta.
Trzymanie AI na krótkiej smyczy
W drugim etapie duży model językowy działa w starannie odgrodzonej przestrzeni wyszukiwania. Zamiast wymyślać adres od podstaw, model otrzymuje oryginalny oczyszczony tekst oraz niewielki zestaw kandydatów społeczności zasugerowanych przez graf wiedzy. Polecenie wyraźnie instruuje model, by wybierał wyłącznie spośród tych kandydatów i zwracał wyniki w ustalonej strukturze JSON z oddzielnymi polami dla miasta, dzielnicy, ulicy lub gminy oraz osiedla. Jeśli żaden z kandydatów nie pasuje — na przykład gdy prawdziwa społeczność nie została pobrana — model ma zwrócić puste wartości zamiast zgadywać. Takie zachowanie „najpierw odrzucaj” znacząco zmniejsza ryzyko wprowadzenia do akt szpitalnych wiarygodnie brzmiących, lecz błędnych wpisów.
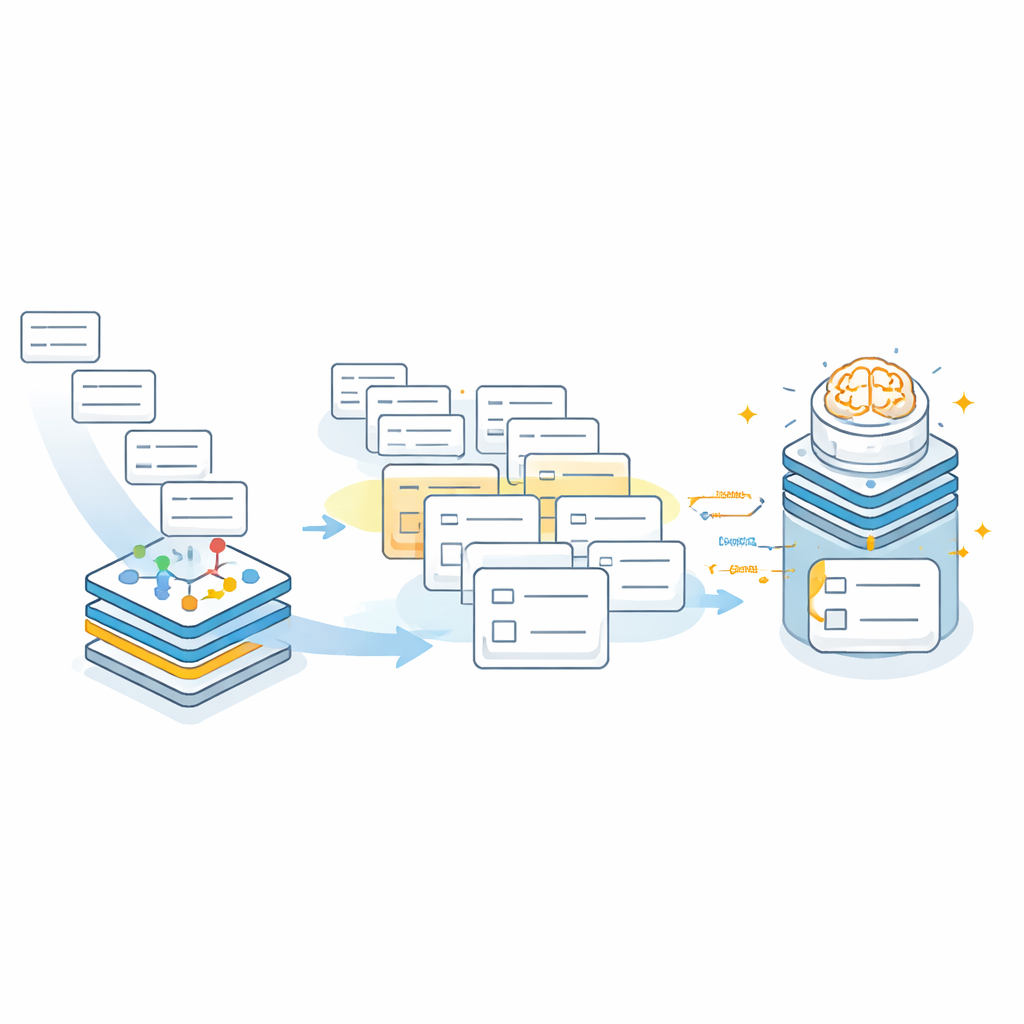
Jak działa to w praktyce?
Zespół przetestował AddrKG‑LLM na dziesięciu tysiącach zanonimizowanych rzeczywistych adresów szpitalnych, które odzwierciedlają prawdziwy szum: skróty, brakujące dzielnice, warianty pisowni, a nawet całkowicie nieprawidłowe wpisy. Porównali swój system z klasycznymi narzędziami do dopasowywania łańcuchów, modelami sekwencyjnego oznaczania opartego na głębokim uczeniu, ogólnego przeznaczenia modelami językowymi używanymi w trybie dowolnym oraz komercyjną usługą standaryzacji adresów. W rygorystycznych miarach wymagających jednoczesnej poprawności wszystkich pól adresu AddrKG‑LLM przewyższył wszystkie te rozwiązania, zwiększając ogólną dokładność o ponad dwanaście punktów procentowych w porównaniu z silnym modelem opartym na BERT. Korzyści były szczególnie widoczne przy adresach ze skrótami i brakującymi elementami, gdzie wbudowana hierarchia grafu wiedzy pomaga uzupełniać luki. Autorzy zbadali także, jak wydajność zmienia się wraz z różnymi rozmiarami modelu językowego i różną liczbą pobranych kandydatów, pokazując, jak szpitale mogą wyważyć prędkość i dokładność w zależności od swoich potrzeb.
Co to oznacza dla codziennej opieki
Dla osób spoza specjalizacji kluczowy wniosek jest taki, że AddrKG‑LLM oferuje sposób oczyszczania istotnych, lecz nieuporządkowanych danych adresowych pacjentów, jednocześnie zachowując kontrolę w rękach ludzi. Łącząc mapopodobny graf wiedzy z ograniczonym modelem językowym uruchamianym w całości na serwerach szpitala, ramy te dostarczają dokładniejsze, spójne adresy bez wysyłania wrażliwych danych do zewnętrznych chmur czy pozwalania AI na improwizację. Efekt to praktyczne narzędzie, które może wzmocnić nadzór nad chorobami, poprawić planowanie zasobów i wspierać bezpieczniejsze oraz bardziej efektywne działania szpitali — po prostu poprzez zapewnienie, że każdy pacjent jest niezawodnie umieszczony na mapie.
Cytowanie: Li, J., Pan, X. & Jia, Y. Patient address parsing via KG-aware contrastive learning and constrained on-prem LLM inference. Sci Rep 16, 8003 (2026). https://doi.org/10.1038/s41598-026-39348-z
Słowa kluczowe: parsowanie adresów pacjentów, jakość danych zdrowotnych, graf wiedzy, duży model językowy, informatyka medyczna