Clear Sky Science · pl
Topologia ruchu szkieletu z maskowaniem predykcji i uczenie kontrastowe do samoucącego się rozpoznawania czynności człowieka
Nauczanie komputerów czytania mowy ciała
Od wideodomofonów po inteligentne narzędzia rehabilitacyjne — wiele współczesnych systemów musi rozumieć, co ludzie robią, obserwując jedynie ich ruchy. Jednak trenowanie komputerów do rozpoznawania czynności zwykle wymaga ogromnych, starannie oznakowanych zbiorów danych, gdzie każdy gest, kopnięcie czy uścisk dłoni jest opisywany ręcznie. W tym badaniu przedstawiono metodę, która pozwala maszynom uczyć się wyłącznie z surowych danych ruchu, operując tylko na poruszającym się szkielecie ciała — bez etykiet, twarzy czy pełnokolorowego wideo — co czyni rozpoznawanie czynności dokładniejszym, bardziej prywatnym i znacznie mniej zależnym od kosztownej ręcznej anotacji.
Dlaczego wystarczy sam szkielet
Zamiast analizować pełne klatki wideo, metoda operuje na danych szkieletowych 3D: współrzędnych kluczowych stawów, takich jak ramiona, łokcie, biodra czy kolana w kolejnych chwilach czasu. Takie ascetyczne ujęcie ciała ma kilka zalet. W dużej mierze omija problemy prywatności, ponieważ twarze i ubrania są usunięte, a przy tym jest dovoljno kompaktowe, by przetwarzać je efektywnie nawet dla długich nagrań. Szkielety są też odporne na zagracone tło i zmiany oświetlenia, które mogą dezorientować standardowe systemy wideo. Jednak większość istniejących podejść opartych na szkielecie wciąż silnie polega na przykładach z etykietami i ma trudności z pełnym uchwyceniem współruchu stawów w złożonych, skoordynowanych czynnościach.
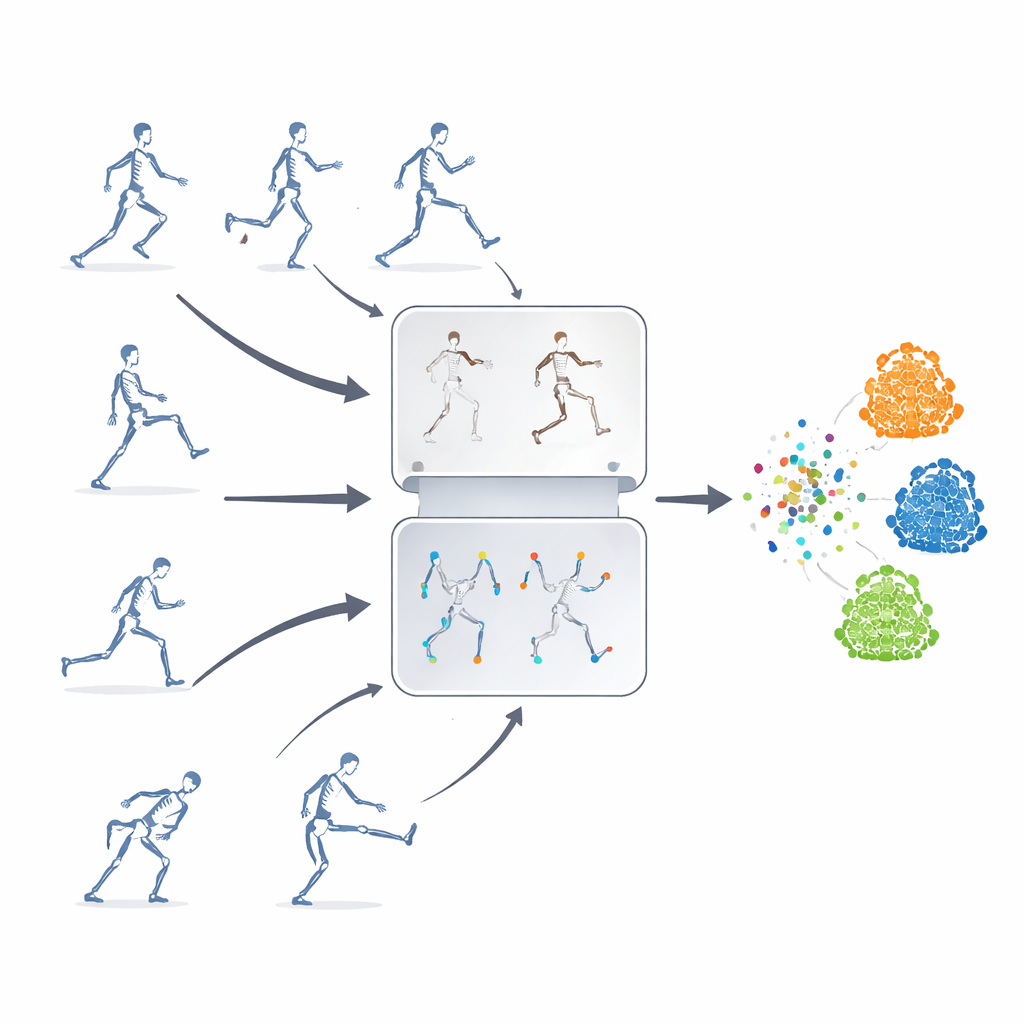
Nauka bez etykiet
Autorzy proponują ramy uczenia samonadzorowanego, co oznacza, że system uczy się z nieoznakowanych sekwencji szkieletu. Ich kluczowy pomysł polega na połączeniu dwóch potężnych strategii zwykle stosowanych osobno. Jedna to „maskowana predykcja”, gdzie fragmenty danych szkieletowych są celowo ukrywane, aby model musiał odgadnąć brakujący ruch na podstawie pozostałego kontekstu. Druga to „uczenie kontrastowe”, które pokazuje modelowi wiele zmienionych wersji tej samej czynności i uczy go rozpoznawać, że te warianty nadal reprezentują jedną, podstawową sekwencję ruchu. Dzięki połączeniu tych podejść system uczy się zarówno drobnych szczegółów ruchu stawów, jak i ogólnego znaczenia czynności.
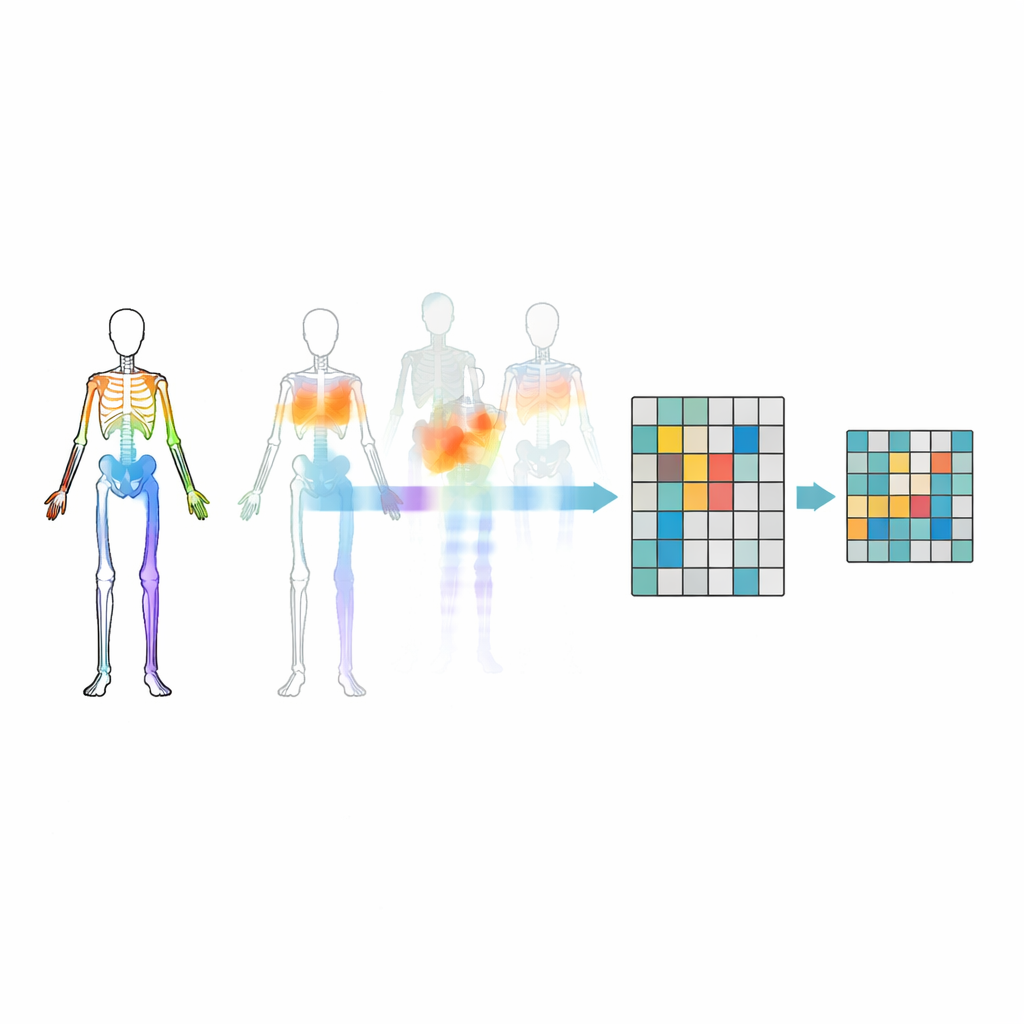
Ukrywanie właściwych stawów
Proste maskowanie losowych stawów to za mało — model może zignorować istotne relacje między częściami ciała albo skupiać się na najbardziej oczywistych ruchach. Aby temu zapobiec, badacze wprowadzają strategię maskowania opartą na topologii ruchu. Grupują stawy w sensowne regiony ciała, takie jak ramiona, nogi czy tułów, a następnie mierzą, jak silnie każdy region porusza się w czasie. Decyzje o maskowaniu kierowane są zarówno strukturą ciała, jak i intensywnością ruchu danego regionu, tak że czasem ukrywane są fragmenty szczególnie aktywne, zmuszając model do ich wnioskowania na podstawie reszty ciała. To celowe ukrywanie pomaga systemowi nauczyć się, jak stawy współdziałają podczas czynności, zamiast jedynie zapamiętywać kilka efektownych ruchów.
Rozciąganie czynności na wiele sposobów
Aby trenować część kontrastową systemu, ta sama oryginalna sekwencja szkieletu jest przekształcana w wiele różnych „widoków”. Niektóre zmiany są łagodne, takie jak przycinanie okna czasowego czy lekkie zniekształcenie trajektorii, podczas gdy inne są bardziej ekstremalne, włączając odbicia, rotacje i silniejszy szum. Te wielopoziomowe augmentacje eksponują model na bogatą gamę wzorców ruchu, zachęcając go do skupienia się na podstawowej strukturze czynności zamiast powierzchownych szczegółów. Równocześnie moduł usuwania cech kierowany trasą śledzi, na których cechach ruchu model polega najbardziej i celowo je tłumi podczas treningu. Tymczasowo usuwając swoje ulubione wskazówki, system jest zmuszany do odnalezienia alternatywnych sygnałów i nauczenia się bardziej ogólnych, przenośnych reprezentacji.
Jak dobrze to działa?
Ramę przetestowano na trzech dużych publicznych benchmarkach działań człowieka 3D, obejmujących zachowania codzienne, ruchy związane z medycyną oraz interakcje międzyludzkie. Mimo że wykorzystuje jedynie dane stawów szkieletowych i stosunkowo lekki rekurencyjny sieciowy model, metoda dorównuje lub przewyższa wiele systemów z najnowszego stanu wiedzy, które opierają się na bardziej złożonych wejściach czy architekturach. Jest szczególnie silna, gdy anotacji jest mało lub gdy niektóre części ciała są zasłonięte — warunki często spotykane w środowiskach rzeczywistych. Choć jej zdolność do przenoszenia wiedzy między bardzo różnymi zbiorami danych nadal można ulepszyć, podejście znacząco zmniejsza dystans między treningiem z etykietami a bez etykiet w rozpoznawaniu czynności.
Co to oznacza dla systemów w realnym świecie
Dla osoby niebędącej specjalistą główne przesłanie jest takie, że praca ta pokazuje, jak komputery mogą znacznie lepiej czytać mowę ciała człowieka bez konieczności jawnego oznaczania, co każdy ruch oznacza. Poprzez inteligentne ukrywanie i zniekształcanie danych szkieletowych podczas treningu model uczy się odpornych wzorców ruchu, które działają w złym oświetleniu, przy wizualnym zanieczyszczeniu czy brakujących stawach, i to przy znacznie mniejszej liczbie etykiet dostarczanych przez ludzi. Otwiera to drzwi do bardziej prywatnych, skalowalnych i adaptowalnych systemów rozpoznawania czynności zastosowań od monitoringu domowego i treningu sportowego po rehabilitację medyczną i interakcję człowiek–robot.
Cytowanie: Hui, Y., Li, F., Hu, X. et al. Skeleton motion topology-masked prediction and contrastive learning for self-supervised human action recognition. Sci Rep 16, 8100 (2026). https://doi.org/10.1038/s41598-026-39330-9
Słowa kluczowe: rozpoznawanie czynności człowieka, dane szkieletowe 3D, uczenie samonadzorowane, uczenie kontrastowe, analiza ruchu