Clear Sky Science · pl
Wykorzystanie dużego modelu językowego do poprawy rozumowania innego dużego modelu językowego poprzez nagradzane zaktualizowane GRPO
Nauczanie maszyn myślenia krok po kroku
Wiele współczesnych modeli językowych potrafi rozmawiać, tłumaczyć i odpowiadać na pytania, lecz wciąż mają problemy z przedstawianiem rozumowania w sposób, w jaki zrobiłby to dobry uczeń matematyki czy uważny analityk. Artykuł bada, jak jeden system sztucznej inteligencji może poprawiać umiejętności rozumowania innego oraz jak osiągnąć to bez ręcznego tworzenia olbrzymich, wyspecjalizowanych zbiorów danych. Dla czytelników zainteresowanych większą niezawodnością AI w dziedzinach takich jak finanse, medycyna czy badania naukowe, praca oferuje praktyczny przepis na to, jak sprawić, by modele wyjaśniały swoje odpowiedzi jaśniej i konsekwentniej.
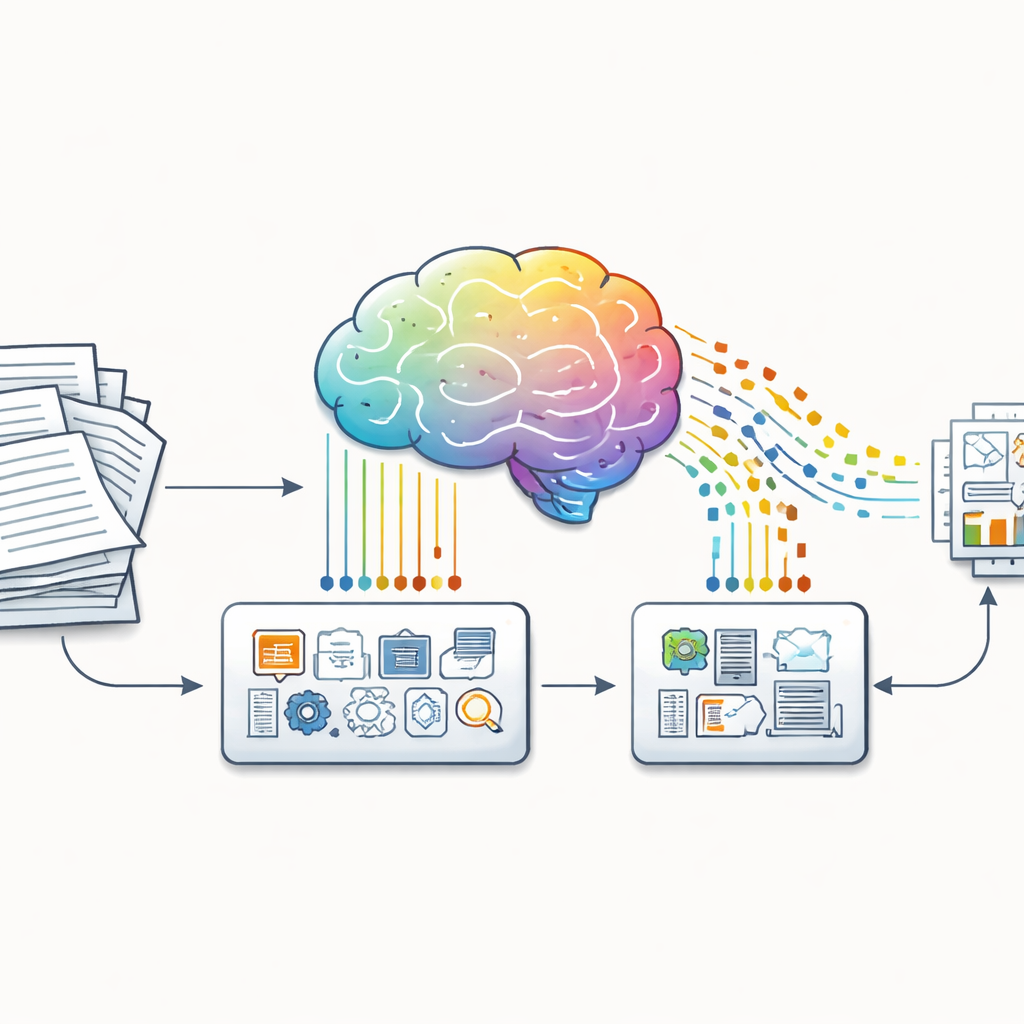
Od surowych dokumentów do uczących przykładów
Autorzy wychodzą od prostego spostrzeżenia: większość informacji w świecie rzeczywistym występuje w nieuporządkowanych formach, takich jak raporty, listy do akcjonariuszy czy strony internetowe, a nie w schludnym formacie pytanie–odpowiedź. Aby pokonać tę lukę, przedstawiają dwa narzędzia programowe: Huggify-Data i Generator Danych CoT. Narzędzia te zamieniają nieuporządkowany tekst w pary pytanie–odpowiedź, a następnie proszą potężny model językowy o dostarczenie brakujących kroków rozumowania pomiędzy nimi. Efektem jest ustrukturyzowana trójka dla każdego przykładu: pytanie, ciąg rozumowania i odpowiedź. Co istotne, ten pipeline można skierować niemal na dowolną domenę, od matematyki szkolnej po finanse korporacyjne, co umożliwia tworzenie danych treningowych skoncentrowanych na rozumowaniu bez armii ludzkich adnotatorów.
Jak jeden model trenuje drugi
Gdy trójki pytanie–rozumowanie–odpowiedź zostaną wygenerowane, służą one do szkolenia mniejszego modelu „ucznia”, aby myślał w tej samej ustrukturyzowanej formie. Uczeń proszony jest nie tylko o podanie ostatecznej odpowiedzi, ale o wygenerowanie wyraźnie oddzielonego wyjaśnienia, a następnie wniosku. Trenowanie jest prowadzone metodą nazwaną Group Relative Policy Optimization, która porównuje kilka kandydackich odpowiedzi na to samo pytanie i skłania model w kierunku lepszych. Artykuł uzupełnia tę metodę o dodatkowy składnik nagrody, który sprawdza, czy wyjście modelu ma pożądany format, aż po zgodność ze starannie sformułowanym przykładem referencyjnym. Ta nagroda delikatnie karze pomieszane lub niekompletne wyjaśnienia, skłaniając model do uporządkowanych, interpretowalnych odpowiedzi.
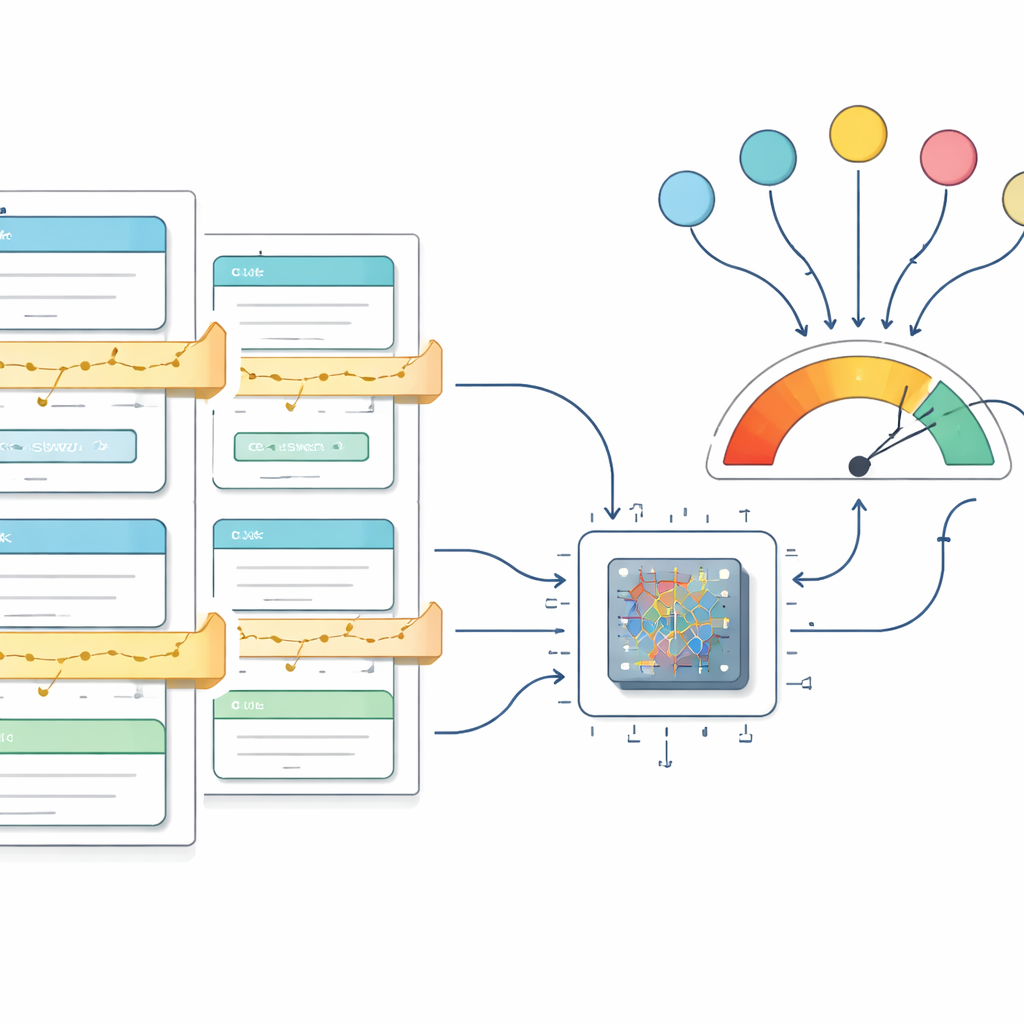
Testowanie podejścia
Aby sprawdzić, czy ramy działają w praktyce, autorzy stosują je do dwóch bardzo różnych zbiorów danych. Pierwszy, GSM8K, składa się z zadań tekstowych na poziomie szkoły podstawowej wymagających wieloetapowego rozumowania arytmetycznego. Drugi zbudowano z corocznych listów Warrena Buffetta do akcjonariuszy, gdzie celem jest uchwycenie długiej formy rozumowania o inwestowaniu i decyzjach korporacyjnych. W obu przypadkach pipeline przekształca surowy tekst w ustrukturyzowane dane treningowe i dostraja model średniej wielkości o nazwie Qwen 2.5. Podczas treningu prostą regułą punktacji nagradzane są poprawne, dobrze sformatowane odpowiedzi; w miarę postępów uczenia się średnia nagroda systematycznie rośnie i stabilizuje się na swoim teoretycznym maksimum, co pokazuje, że model w dużej mierze opanował pożądane zachowanie na danych treningowych.
Jak dobrze działa ulepszony model
Wydajność mierzona jest przy użyciu „średniej dokładności tokenów”, co w przybliżeniu pyta, jaka część małych fragmentów tekstu (tokenów) w wyjściach modelu odpowiada oczekiwanym. Choć różni się to od zwykłego zeru-jedynkowego oceniania odpowiedzi testowych, dobrze nadaje się do oceny, czy wyjaśnienia i odpowiedzi mają właściwą strukturę. W zadaniach GSM8K najlepszy model osiąga 98,2 proc. dokładności tokenów, a w listach Buffetta — 98,5 proc. Wyniki te są wyższe niż te zgłaszane dla powszechnie znanych systemów, takich jak GPT‑4 i Claude 3.5 Sonnet według tej samej miary, przy czym użyto zaledwie modelu o 3 miliardach parametrów, który można wytrenować w mniej niż dwa dni na wynajętym sprzęcie. Autorzy dzielą się również szczegółami dotyczącymi kosztów obliczeniowych i konfiguracji sprzętowych oraz udostępniają cały kod, modele i zbiory danych, aby inni mogli je zbadać i rozwijać.
Co to oznacza dla codziennego użycia AI
Dla osób niebędących specjalistami główny wniosek jest taki, że systemów AI można nauczyć nie tylko odpowiadać, lecz odpowiadać w zdyscyplinowany, łatwy do śledzenia sposób, wykorzystując dane automatycznie wyekstrahowane z zwykłych dokumentów. Łącząc bogaty w rozumowanie model-nauczyciel, elastyczny pipeline danych i schemat nagród, który ceni zarówno poprawność, jak i przejrzystość, autorzy pokazują, jak kształtować mniejsze modele w bardziej niezawodnych rozwiązywaczy problemów. Choć zauważają ograniczenia — takie jak potrzeba mocniejszych testów rzeczywistego rozumienia i bezpieczeństwa — ramy te wskazują przyszłość, w której organizacje mogą przekształcać swoje archiwa tekstowe w dostosowane, przejrzyste asystenty AI dla edukacji, finansów i innych dziedzin.
Cytowanie: Yin, Y. Use large language model to enhance reasoning of another large language model through reward updated GRPO. Sci Rep 16, 8360 (2026). https://doi.org/10.1038/s41598-026-39296-8
Słowa kluczowe: duże modele językowe, rozumowanie łańcuchowe (chain-of-thought), optymalizacja nagrody, kuracja danych, specjalistyczna sztuczna inteligencja