Clear Sky Science · pl
Rama syjamska CNN-RNN z wielopoziomową agregacją do identyfikacji osób wideo
Dlaczego śledzenie osób między kamerami ma znaczenie
Nowoczesne miasta są pokryte kamerami, lecz rzadko ze sobą „rozmawiają”. Gdy osoba przechodzi z rogu ulicy do stacji kolejowej, różne kamery rejestrują ją pod innymi kątami, w zmiennym oświetleniu i często w tłumie. Automatyczne rozpoznanie, że to ta sama osoba w różnych klipach wideo — zwane identyfikacją osób opartą na wideo — może pomóc śledczym odtworzyć przebieg zdarzeń, wesprzeć poszukiwania zaginionych lub napędzać analitykę w zatłoczonych miejscach publicznych. Dokładne i wydajne przeprowadzenie tego zadania, szczególnie na skromnym sprzęcie, stanowi jednak poważne wyzwanie techniczne.
Prostszy „mózg” do rozpoznawania poruszających się osób
W badaniu przedstawiono kompaktowy system sztucznej inteligencji zaprojektowany do ustalania, czy dwa krótkie klipy wideo przedstawiają tę samą osobę. Zamiast podążać za współczesnym trendem bardzo głębokich lub opartych na transformatorach sieci, autorzy oparli się na bardziej oszczędnej konstrukcji łączącej dwa klasyczne składniki: sieć konwolucyjną analizującą każdą klatkę oraz bramkowaną jednostkę rekurencyjną (GRU), która śledzi, jak wygląd zmienia się w czasie. Obie gałęzie są ułożone w układ syjamski — de facto bliźniacze kopie tej samej sieci dzielące wszystkie ustawienia wewnętrzne. Każda kopia przetwarza jedną sekwencję wideo, a system uczy się generować podobne wewnętrzne sygnatury dla klipów tej samej osoby i wyraźnie różne sygnatury dla różnych osób.
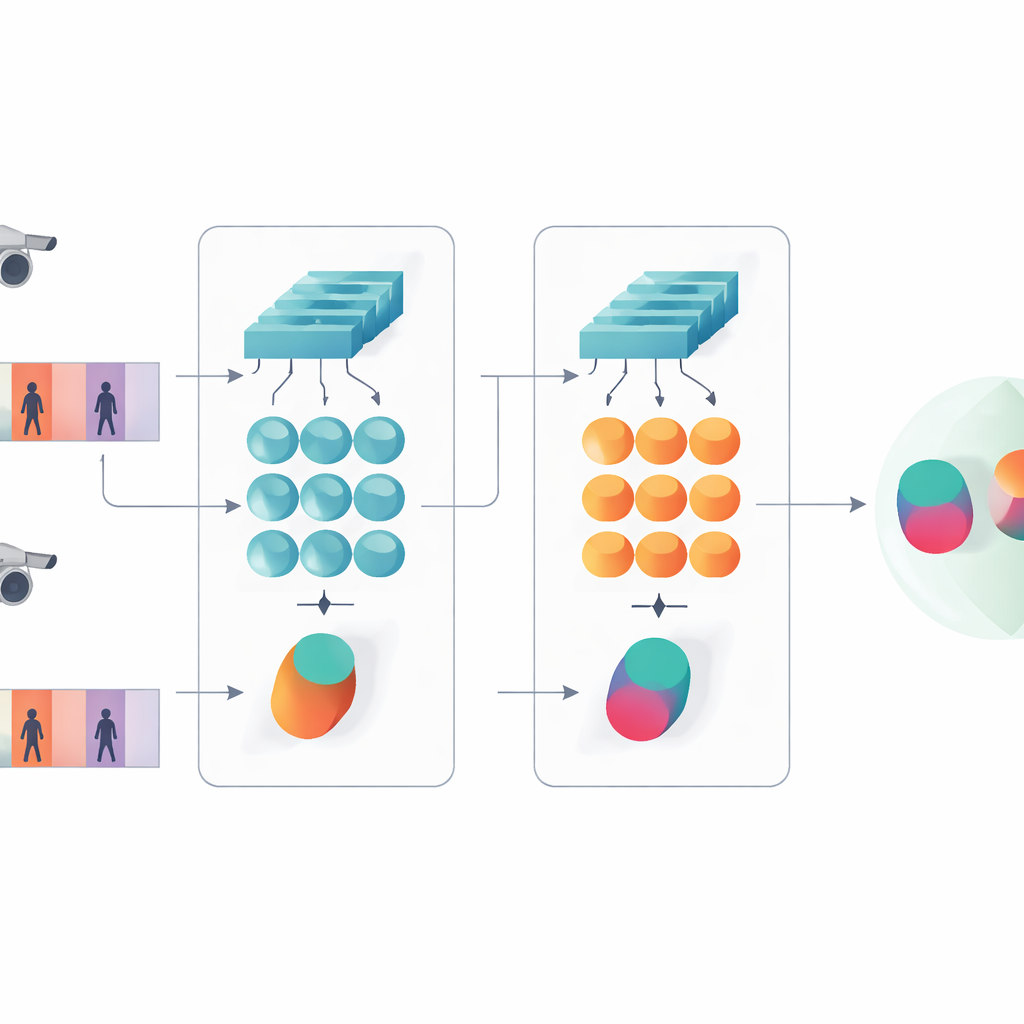
Widzieć zarówno detale, jak i wzorce w czasie
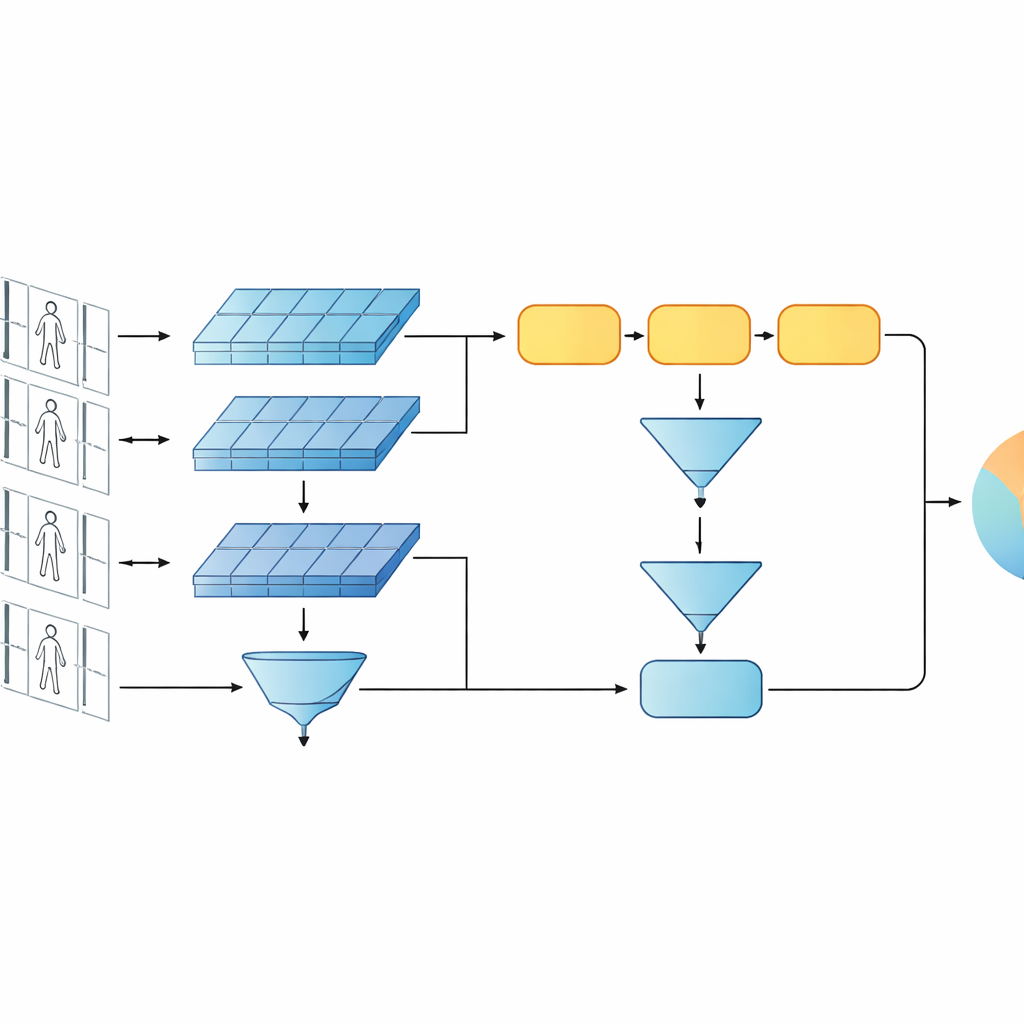
Kluczową ideą pracy jest przekonanie, że rozpoznawanie nie powinno opierać się wyłącznie na najgłębszych, najbardziej abstrakcyjnych cechach sieci. Wcześniejsze warstwy wciąż zawierają ostre detale wizualne, takie jak splot kurtki, paski na spodniach czy kontur plecaka — wskazówki, które często przetrwają zmianę kąta kamery. Proponowany model utrzymuje więc dwa poziomy opisu. Jedna gałąź agreguje cechy z wczesnych warstw ze wszystkich klatek, podsumowując drobne tekstury i lokalne wzory. Druga gałąź przekazuje późniejsze cechy do GRU, które podąża za sekwencją klatka po klatce, a następnie uśrednia swoje stany wewnętrzne w czasie. Ten krok uśredniania zapobiega nadmiernemu faworyzowaniu ostatnich klatek i zamiast tego uchwyca konsensusowy obraz tego, jak osoba wygląda i porusza się w całym klipie.
Trenowanie bliźniaczych sieci, by się zgadzały i klasyfikowały
Aby nauczyć system, co jest istotne, autorzy łączą dwa cele treningowe. Po pierwsze, cel weryfikacyjny zachęca gałęzie bliźniacze do generowania podobnych sygnatur dla wideo tej samej osoby i odległych sygnatur dla różnych osób. Po drugie, cel klasyfikacyjny prosi sieć o przypisanie każdego klipu treningowego do konkretnej tożsamości. Optymalizując oba jednocześnie, i robiąc to na niskim i wysokim poziomie cech, model uczy się wewnętrznych opisów, które nie tylko różnicują osoby, ale są też odporne na szum, zasłonięcia i sporadycznie słabe klatki. Projekt pozostaje płytki pod względem warstw i parametrów, co pomaga uniknąć przeuczenia na stosunkowo niewielkich zbiorach wideo.
Testy na rzeczywistych nagraniach w stylu dozoru
Ramę oceniono na dwóch szeroko używanych benchmarkach wideo, PRID-2011 i iLIDS-VID, które zawierają krótkie sekwencje spacerowe setek osób rejestrowane z par rozłącznych kamer. Badanie starannie bada różne wybory projektowe: zamianę GRU na inne jednostki rekurencyjne, zmianę liczby warstw rekurencyjnych, modyfikację sposobu agregacji cech w czasie oraz włączanie i wyłączanie gałęzi niskiego lub wysokiego poziomu. W tych testach jednolita warstwa GRU z uśrednianiem (mean pooling) i pełnym wielopoziomowym układem konsekwentnie dostarcza najlepszą dokładność. Model dorównuje lub przewyższa wiele bardziej złożonych systemów rekurencyjnych i syjamskich oraz konkuruje z niektórymi konstrukcjami opartymi na mechanizmach uwagi, przy znacznie mniejszej liczbie parametrów i mniejszym koszcie obliczeniowym.
Wydajność dla wdrożeń w świecie rzeczywistym
Poza dokładnością, praca kładzie nacisk na praktyczność. Cała sieć ma jedynie około jednego do dwóch milionów trenowalnych parametrów — rzędy wielkości mniej niż popularne głębokie sieci resztkowe czy modele oparte na transformerach — i wymaga ułamka ich kosztu obliczeniowego na klatkę. To sprawia, że jest bardziej odpowiednia do wdrożeń na urządzeniach o ograniczonej pamięci i mocy obliczeniowej, takich jak serwery brzegowe przy kamerach. Eksperymenty pokazują też, że dłuższe sekwencje w galerii, gdy system widzi więcej klatek przechowywanej osoby, znacząco poprawiają rozpoznawanie, choć przy liniowym wzroście kosztów przetwarzania. Autorzy argumentują, że takie kompaktowe, starannie zaprojektowane architektury mogą dostarczyć niezawodnej identyfikacji osób bez wysokiej ceny największych współczesnych modeli.
Co to oznacza dla codziennych systemów monitoringu
Mówiąc prosto, artykuł pokazuje, że przemyślany projekt może przewyższyć samą skalę: łącząc płytką analizę obrazu, lekkie modelowanie sekwencji i dwupoziomowe spojrzenie na podobieństwo wizualne, można śledzić, kto jest kim między kamerami z wysoką niezawodnością, przy zachowaniu niewielkiego i szybkiego modelu. Dla przyszłych systemów, które muszą działać na wielu kamerach, często z ograniczonym sprzętem i budżetem energetycznym, takie efektywne, wielopoziomowe podejście może pomóc wprowadzić bardziej zaawansowaną i odpowiedzialną analitykę wideo do zastosowań rzeczywistych.
Cytowanie: Wang, YK., Pan, TM. & Sun, CP. A CNN-RNN Siamese framework with multi-level aggregation for video-based person re-identification. Sci Rep 16, 8224 (2026). https://doi.org/10.1038/s41598-026-39277-x
Słowa kluczowe: identyfikacja osób, monitoring wideo, sieci neuronowe syjamskie, modelowanie czasowe, efektywne uczenie głębokie