Clear Sky Science · pl
Solidne ramy konwersji tekstu w języku naturalnym na SQL z dynamicznymi strategiami opartymi na LLM
Przekształcanie codziennych pytań w odpowiedzi z bazy danych
Współczesne organizacje toną w danych, ale większość ludzi nie włada językiem technicznym potrzebnym do ich zapytania. W artykule przedstawiono TriSQL — system, który pozwala użytkownikom zadawać pytania prostym językiem i automatycznie przekształca je w precyzyjne polecenia do bazy danych. Dzięki starannemu zarządzaniu sposobem, w jaki duże modele językowe radzą sobie ze złożonością, ramy te mają na celu uczynienie dostępu do danych zarówno bardziej dokładnym, jak i bardziej niezawodnym, nawet w przypadku najtrudniejszych pytań.
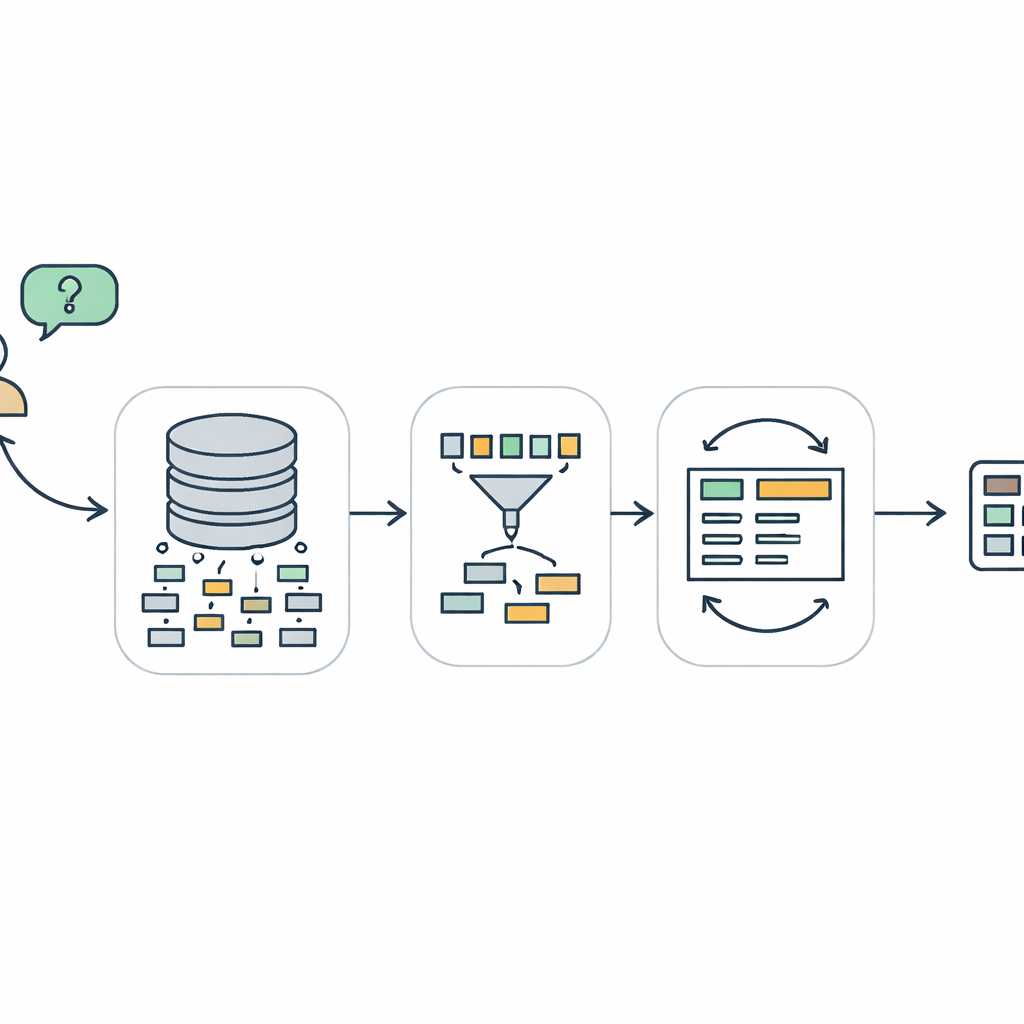
Dlaczego rozmowa z bazami danych jest tak trudna
Kiedy ktoś wpisuje pytanie typu „Którzy klienci kupili więcej niż pięć produktów w zeszłym miesiącu?”, komputer musi przetłumaczyć to na SQL — specjalistyczny język używany w większości baz danych. Zadanie to, zwane text-to-SQL, wydaje się proste, ale w praktyce jest zaskakująco trudne. System musi zrozumieć intencję użytkownika, odnaleźć odpowiednie tabele i kolumny w niekiedy ogromnej i chaotycznej bazie danych, a następnie skonstruować zapytanie, które będzie zarówno strukturalnie poprawne, jak i wierne oryginalnemu zamiarowi. Poprzednie systemy, w tym te oparte na dużych modelach językowych, często zawodzą, gdy pytania obejmują wiele tabel, zagnieżdżoną logikę lub subtelne warunki. Mogą generować zapytania wyglądające podobnie do poprawnych, które jednak nie wykonują się lub zwracają błędne wyniki po uruchomieniu.
Trzystopniowa ścieżka od pytania do zapytania
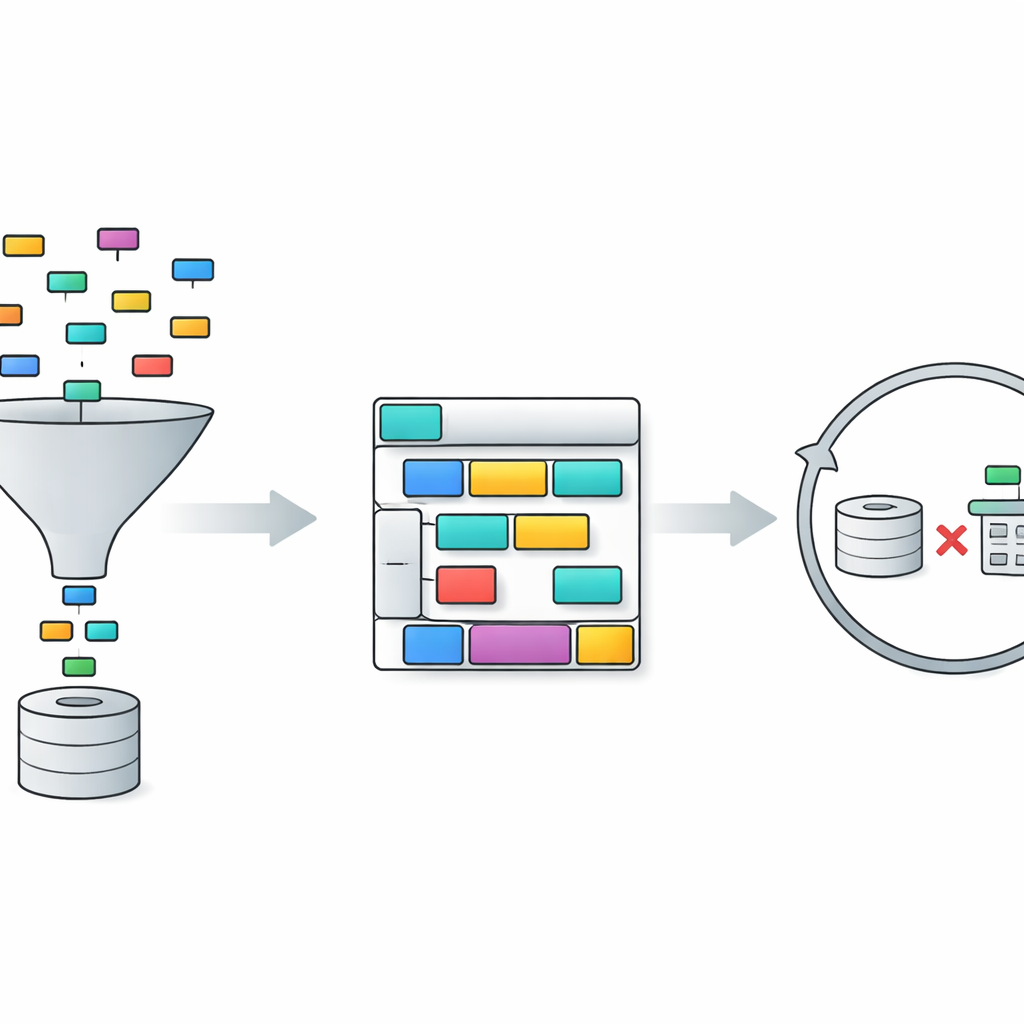
TriSQL rozwiązuje te problemy za pomocą trzyetapowego potoku. Najpierw selektor kierowany pytaniem analizuje słowa użytkownika oraz pełną strukturę bazy danych i decyduje, które tabele i kolumny są naprawdę istotne. Zamiast bezmyślnie eksponować model językowy na cały schemat, zawęża widok do tych fragmentów, które mają znaczenie. Po drugie, generator świadomy struktury planuje kształt zapytania SQL przed wypełnieniem szczegółów. Najpierw szkicuje wysokopoziomowy szkielet — jakie klauzule są potrzebne i jak się ze sobą łączą — a następnie wstawia konkretne tabele, połączenia i warunki. Podejście „najpierw struktura, potem treść” pomaga zachować rygorystyczną gramatykę SQL, zwłaszcza przy długich i złożonych zapytaniach. Na koniec, rafineria świadoma złożoności sprawdza i ulepsza początkowe zapytanie, stosując różne strategie w zależności od tego, jak trudne wydaje się pytanie.
Dopasowanie wysiłku do trudności pytania
Etap ulepszania to miejsce, gdzie TriSQL w szczególny sposób wykorzystuje duże modele językowe. System ocenia, jak złożone są dane pytanie i wstępne zapytanie, biorąc pod uwagę takie czynniki, jak liczba łączonych tabel, głębokość zagnieżdżeń oraz rodzaje użytych ograniczeń. W prostych przypadkach stosuje jedynie lekkie korekty, takie jak poprawki drobnych błędów składniowych. W przypadkach średnich reorganizuje klauzule i zapewnia, że zapytanie zgadza się z wybranym schematem. W przypadku najbardziej wymagających pytań uruchamia model językowy do głębszego rozumowania, czasami dekomponując problem na podzadania i uruchamiając alternatywne zapytania. Kluczowe jest to, że TriSQL następnie wykonuje zarówno oryginalne, jak i poprawione zapytania przeciwko bazie danych i wykorzystuje ich zachowanie — czy się wykonują, ile trwają i co zwracają — do zdecydowania, którą wersję zachować lub czy spróbować kolejnej rundy ulepszeń.
Testowanie systemu
Aby sprawdzić skuteczność TriSQL, autorzy testują go na szeroko używanym benchmarku o nazwie Spider, wraz z kilkoma trudniejszymi wariantami wprowadzającymi wiedzę dziedzinową, nietypowe wzorce zdań i bardziej realistyczne struktury zapytań. Mierzą dwa wskaźniki: exact match — sprawdzający, czy wygenerowany ciąg SQL jest identyczny z referencyjnym zapisem napisanym przez człowieka — oraz execution accuracy — sprawdzający, czy zapytanie faktycznie zwraca poprawną odpowiedź po uruchomieniu. W tych zbiorach danych TriSQL osiąga dotychczas najwyższą zgłaszaną dokładność wykonania, jednocześnie utrzymując exact match na poziomie konkurencyjnym z najlepszymi dotychczasowymi systemami. Jest też bardziej odporny: wraz z przechodzeniem pytań od łatwych do ekstremalnie trudnych, wydajność TriSQL spada znacznie łagodniej niż metody konkurencyjne. Dodatkowe eksperymenty na rzeczywistym zbiorze danych dotyczących zarządzania siecią energetyczną pokazują, że ta sama architektura radzi sobie nie tylko z pobieraniem danych, ale także z poleceniami insert, update, delete i tworzeniem tabel. Wstępne adaptacje do baz grafowych (Cypher) i potoków MongoDB sugerują, że trzystopniowy projekt może rozszerzać się poza klasyczny SQL.
Co to oznacza dla codziennego korzystania z danych
Mówiąc prosto, praca ta przybliża nas do świata, w którym ludzie mogą rozmawiać ze złożonymi bazami danych tak łatwo, jak dziś rozmawiają z wyszukiwarkami. Dzięki ostrożnemu wyborowi, które części bazy danych rozważać, planowaniu struktury zapytania przed wypełnieniem szczegółów oraz dostosowywaniu wykorzystania dużych modeli językowych do trudności każdego pytania, TriSQL generuje zapytania, które z większym prawdopodobieństwem wykona się poprawnie i zwrócą zamierzone wyniki. Chociaż wyzwania pozostają — na przykład radzenie sobie z niejednoznacznymi pytaniami i niewidzianymi schematami baz danych — badanie pokazuje, że przemyślana, etapowa konstrukcja może uczynić interfejsy języka naturalnego do danych zarówno potężniejszymi, jak i bardziej przewidywalnymi dla codziennych użytkowników.
Cytowanie: Su, X., Gu, Y., Wang, P. et al. A robust natural language text-to-SQL generation framework with dynamic strategies based on LLMs. Sci Rep 16, 7892 (2026). https://doi.org/10.1038/s41598-026-39128-9
Słowa kluczowe: text-to-SQL, interfejsy w języku naturalnym, zapytania do baz danych, duże modele językowe, odporność zapytań