Clear Sky Science · pl
Metoda radzenia sobie z niezrównoważonymi zbiorami danych przy użyciu przesuwania granicy
Dlaczego rzadkie przypadki mają znaczenie w codziennych danych
Od oszustw bankowych i diagnoz medycznych po przewidywanie odpływu klientów — wiele decyzji, które powierzamy komputerom, zależy od wykrywania rzadkich, lecz kluczowych zdarzeń. W większości rzeczywistych zbiorów danych te ważne przypadki są znacznie mniej liczne niż zwykłe przykłady. Model, który widzi głównie „biznes jak zwykle”, może stać się ślepy na sytuacje, na których najbardziej nam zależy. Artykuł przedstawia nowy sposób zrównoważenia tak skośnych danych, aby algorytmy uczące się poświęcały należytą uwagę rzadkim, o dużym wpływie przypadkom.
Ukryta pułapka jednostronnych danych
Gdy jeden typ przykładów znacznie przeważa drugi, standardowe metody uczenia maszynowego mają tendencję do skupiania się na większości i cichego zaniedbywania mniejszości. System przewidujący odpływ klientów może na przykład oznaczać prawie wszystkich jako lojalnych klientów i nadal osiągać wysoką dokładność, po prostu dlatego, że prawdziwych odchodzących jest bardzo mało. Podobne problemy występują w wykrywaniu wypadków, monitorowaniu oszustw i badaniach przesiewowych w medycynie, gdzie przypadki pozytywne są rzadkie, lecz ich przeoczenie kosztowne. Tradycyjne metody naprawy dzielą się na dwie grupy: modyfikowanie algorytmu uczącego, by „zwracał więcej uwagi” na mniejszość, albo przekształcanie danych przez usuwanie niektórych przykładów większości (undersampling) lub tworzenie dodatkowych przykładów mniejszości (oversampling). Popularne narzędzia oversamplingu, takie jak SMOTE, generują syntetyczne przykłady mniejszości, ale mogą niezamierzenie zaśmiecać delikatny obszar graniczny, gdzie spotykają się obie klasy.
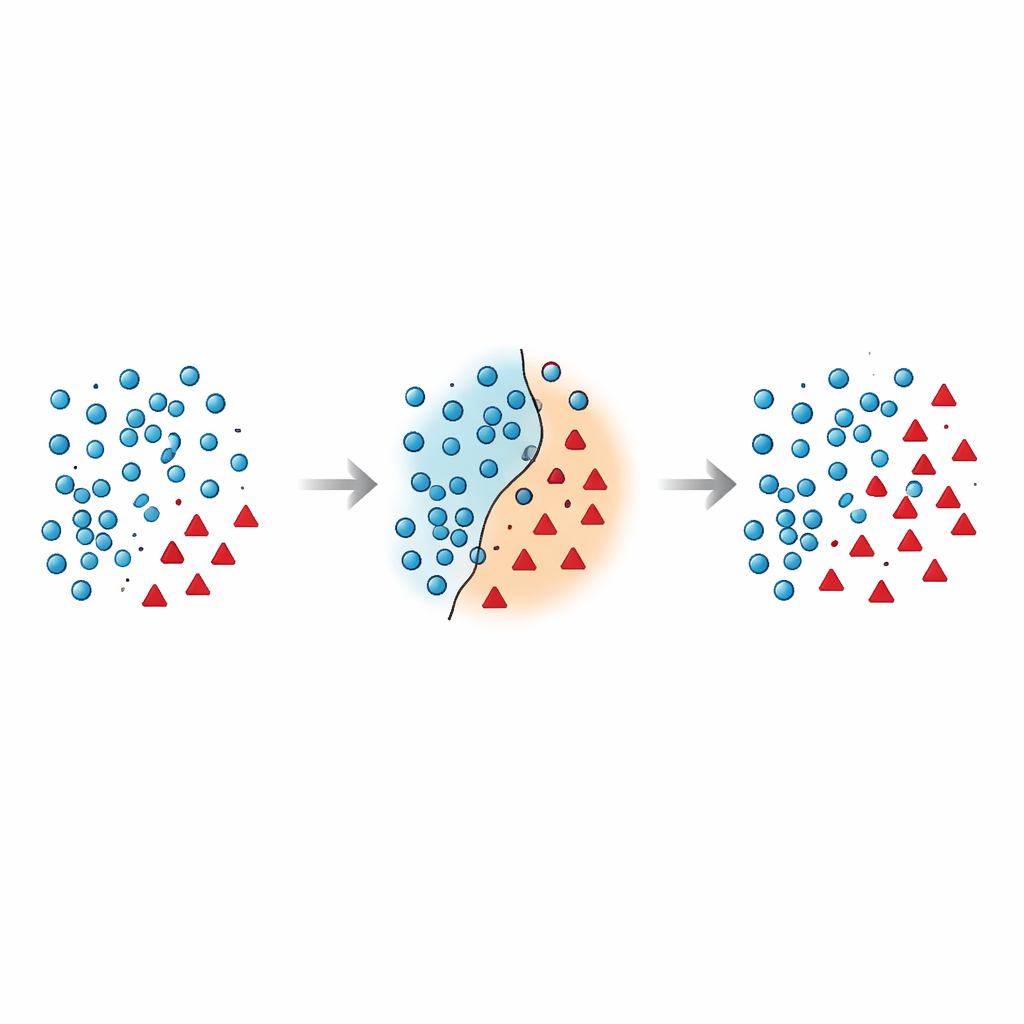
Dlaczego granica między grupami jest tak krucha
Autorzy twierdzą, że najniebezpieczniejsze błędy zdarzają się w pobliżu granicy decyzyjnej — strefy, gdzie przypadki większości i mniejszości nakładają się w przestrzeni cech. Wiele istniejących technik albo dodaje syntetyczne punkty w tym ryzykownym regionie bez wcześniejszego jego oczyszczenia, albo agresywnie usuwa dane i przypadkowo pozbawia się informatywnych przykładów. Nowsze badania próbowały opanować ten problem, stosując ograniczenia geometryczne, lokalne estymaty gęstości czy filtry szumu, jednak większość metod nadal traktuje punkty mniejszości w miejscu i rzadko ponownie rozważa, jak należy postępować z punktami większości znajdującymi się blisko granicy. Pozostawia to uporczywy problem: nakładające się i zaszumione próbki, które mylą klasyfikator i prowadzą do niestabilnych przewidywań, szczególnie na nowych danych.
Dwufazowy sposób oczyszczania granicy
Artykuł wprowadza Borderline Shifting Oversampling (BSO), dwufazową metodę przekształcania danych, która wprost celuje w problematyczny obszar graniczny. Najpierw analizuje sąsiedztwo każdego przykładu większości, aby zdecydować, czy leży on w bezpiecznej strefie, na granicy, czy w wyraźnie błędnym miejscu (szum). Punkty większości otoczone sąsiadami z mniejszości są albo przeklasyfikowywane w kierunku mniejszości, albo oznaczane jako szum i usuwane, co efektywnie czyści i przesuwa granicę, aby lepiej odzwierciedlała rzeczywisty wzorzec. W drugiej fazie metoda generuje nowe syntetyczne punkty mniejszości przy użyciu interpolacji podobnej do SMOTE, lecz tylko wokół próbek mniejszości znajdujących się w sąsiedztwie ulepszonej granicy. Koncentrując nowe dane tam, gdzie są najbardziej informatywne, i unikając oczywistych zaszumionych miejsc, BSO tworzy zestaw treningowy zarówno bardziej zrównoważony pod względem liczebności, jak i czystszy strukturalnie.
Ocena metody w praktyce
Aby sprawdzić skuteczność w praktyce, badacze ocenili BSO na 30 zestawach testowych o różnym stopniu nierównowagi i nakładania się klas. Porównali ją z siedmioma powszechnie stosowanymi alternatywami, w tym losowym oversamplingiem i undersamplingiem, SMOTE, Borderline‑SMOTE, NearMiss oraz dwiema hybrydowymi metodami łączącymi oversampling z oczyszczaniem szumu (SMOTE‑Tomek i SMOTE‑ENN). Trzy popularne klasyfikatory — maszyny wektorów nośnych (SVM), Naiwny Bayes i Lasy losowe — były trenowane na każdym przekształconym zbiorze danych. Zamiast polegać na surowej dokładności, badanie użyło miar bardziej informacyjnych przy nierównowadze, takich jak F1‑score, G‑mean, recall, precision oraz pole pod krzywą ROC (AUC). W niemal wszystkich zestawach danych i dla większości klasyfikatorów BSO osiągało wyniki wyższe lub porównywalne przy mniejszej wariancji, co oznacza, że korzyści były spójne, a nie zależne od konkretnego modelu czy ustawień.
Co to znaczy dla decyzji w świecie rzeczywistym
W praktycznym ujęciu podejście Borderline Shifting działa jak ostrożny redaktor danych: oczyszcza mylące przykłady w pobliżu linii podziału między klasami, a następnie dodaje tyle realistycznych przykładów mniejszości, ile trzeba, we właściwych miejscach. W efekcie algorytmy uczące się lepiej rozpoznają rzadkie, lecz ważne zdarzenia, bez wpadania w pułapkę zaszumionych nakładających się próbek. Dla zastosowań takich jak wykrywanie oszustw, przewidywanie wypadków czy triage medyczny — gdzie przeoczenie przypadku mniejszości może być kosztowne — metoda ta oferuje praktyczny sposób na uczynienie modeli sprawiedliwszymi, bardziej czułymi i bardziej niezawodnymi, przy jednoczesnym umiarkowanym narzucie obliczeniowym.
Cytowanie: Malhat, M.G., Elsobky, A.M., Keshk, A.E. et al. An approach for handling imbalanced datasets using borderline shifting. Sci Rep 16, 8264 (2026). https://doi.org/10.1038/s41598-026-39118-x
Słowa kluczowe: nierównowaga klas, oversampling, granica decyzyjna, wykrywanie anomalii, odporność uczenia maszynowego