Clear Sky Science · pl
RFGLNet do uogólnionej na domenę segmentacji semantycznej w trudnych warunkach pogodowych z wzmocnieniem niskiej rangi częstotliwości
Widzenie drogi, gdy pogoda się psuje
Autonomiczne samochody i roboty dostawcze obiecują bezpieczniejsze, bardziej efektywne ulice — pod warunkiem że potrafią niezawodnie „widzieć” otoczenie. Deszcz, mgła, śnieg i ciemne noce znacząco utrudniają to widzenie: zacierają kontrast, dodają szumy i rozmywają krawędzie ludzi, samochodów i krawężników. W artykule przedstawiono RFGLNet, nowy system widzenia komputerowego zaprojektowany tak, by utrzymać ostre rozumienie drogi nawet w najtrudniejszych warunkach pogodowych.

Dlaczego zła pogoda oślepia maszyny
Dzisiejsze systemy autonomiczne często opierają się na procesie zwanym segmentacją semantyczną, w którym algorytm przypisuje każdemu pikselowi klasy takie jak droga, samochód, pieszy czy budynek. W jasnym świetle dziennym współczesne sieci neuronowe radzą sobie z tym zadaniem wyjątkowo dobrze. W czasie ulewy lub gęstej mgły jednak obrazy tracą jasność, pojawiają się szumy, a granice między obiektami stają się rozmyte. Zbieranie i oznaczanie ogromnych zbiorów danych dla każdej niekorzystnej pogody jest nieopłacalne, dlatego większość systemów trenuje się głównie na normalnych, słonecznych obrazach. Gdy napotkają nieznane burze czy śnieg, wydajność gwałtownie spada. Wcześniejsze rozwiązania albo najpierw oczyszczały obrazy, a potem je segmentowały, albo adaptowały modele do konkretnych warunków docelowych. Oba podejścia bywają kruche, powolne lub zbyt zależne od oznaczonych danych w złej pogodzie.
Nowa sieć zaprojektowana na trudne warunki
RFGLNet podchodzi do problemu inaczej: uczy się wyłącznie na standardowych, miejskich scenach w ciągu dnia, a mimo to uogólnia do szerokiego spektrum surowych warunków. Autorzy zaczynają od DINOv2, dużego, wstępnie wytrenowanego modelu wizualnego znanego z uchwycenia bogatej struktury sceny. Zamiast trenować ten ciężki backbone od zera, zamrażają jego parametry i dodają lekką warstwę modułów na wierzchu. Moduły te działają jak sprytne adaptery, przekształcając wewnętrzne reprezentacje backbone’a tak, by mniej myliły się na skutek wizualnego bałaganu powodowanego płatkami śniegu, kroplami deszczu czy mrokiem. Efektem jest system wykorzystujący tylko 4,32 miliona uczonych parametrów — niewiele w porównaniu z typowymi modelami wizji — a jednocześnie uczący się radzić sobie z pogodą, której nigdy nie widział podczas treningu.
Jak sieć uczy się filtrować pogodę
Pierwszą innowacją RFGLNet jest moduł niskiej rangi, który podłącza się do każdej warstwy zamrożonego backbone’a. Przed treningiem moduł ten wykonuje procedurę matematyczną znaną jako rozkład wartości osobliwych (SVD) na symulowanej macierzy cech. Dostarcza to zestaw zwartej reprezentacji składowych, które w przybliżeniu odpowiadają strukturze wewnętrznych cech DINOv2 od samego początku, zamiast zaczynać od losowego szumu. Podczas treningu te składowe są dostrajane, co pozwala modułowi delikatnie korygować cechy backbone’a do nowego zadania, nie naruszając jego podstawowej wiedzy. Następnie sieć stosuje blok uwagi oparty na transformacie Fouriera, który przenosi cechy do dziedziny częstotliwości. Tam szerokie, powoli zmieniające się struktury zwykle reprezentują znaczące obiekty, podczas gdy ostre, nieregularne wzory odpowiadają często szumom pogodowym. Tłumiąc wysokoczęstotliwościowy bałagan i wzmacniając gładsze składniki, system wzmacnia globalne rozumienie sceny przy jednoczesnym tłumieniu zakłóceń.
Wyostrzanie detali bez rozpraszania uwagi
Nawet przy czystszych cechach globalnych drobne detale, takie jak oznakowanie pasów, poręcze ogrodzeń czy sylwetka odległego pieszego, pozostają podatne na rozmycie w złej pogodzie. Aby temu zaradzić, autorzy wprowadzają grupowany moduł uwagi przestrzennej w części dekodera sieci. Zamiast traktować wszystkie kanały cech razem, dzieli je na grupy i uczy oddzielnych map wag przestrzennych dla każdej grupy. Kanały niosące istotną strukturę, jak krawędzie, mogą być wówczas uwydatnione, podczas gdy kanały zdominowane przez szum zostaną stłumione. Te mapy specyficzne dla grup są następnie łączone w globalne ważenie przestrzenne, które wzmacnia drobne detale i wyostrza granice obiektów na wielu rozdzielczościach. W praktyce RFGLNet uczy się, gdzie patrzeć uważnie, a gdzie ignorować rozpraszające plamki mgły czy deszczu.
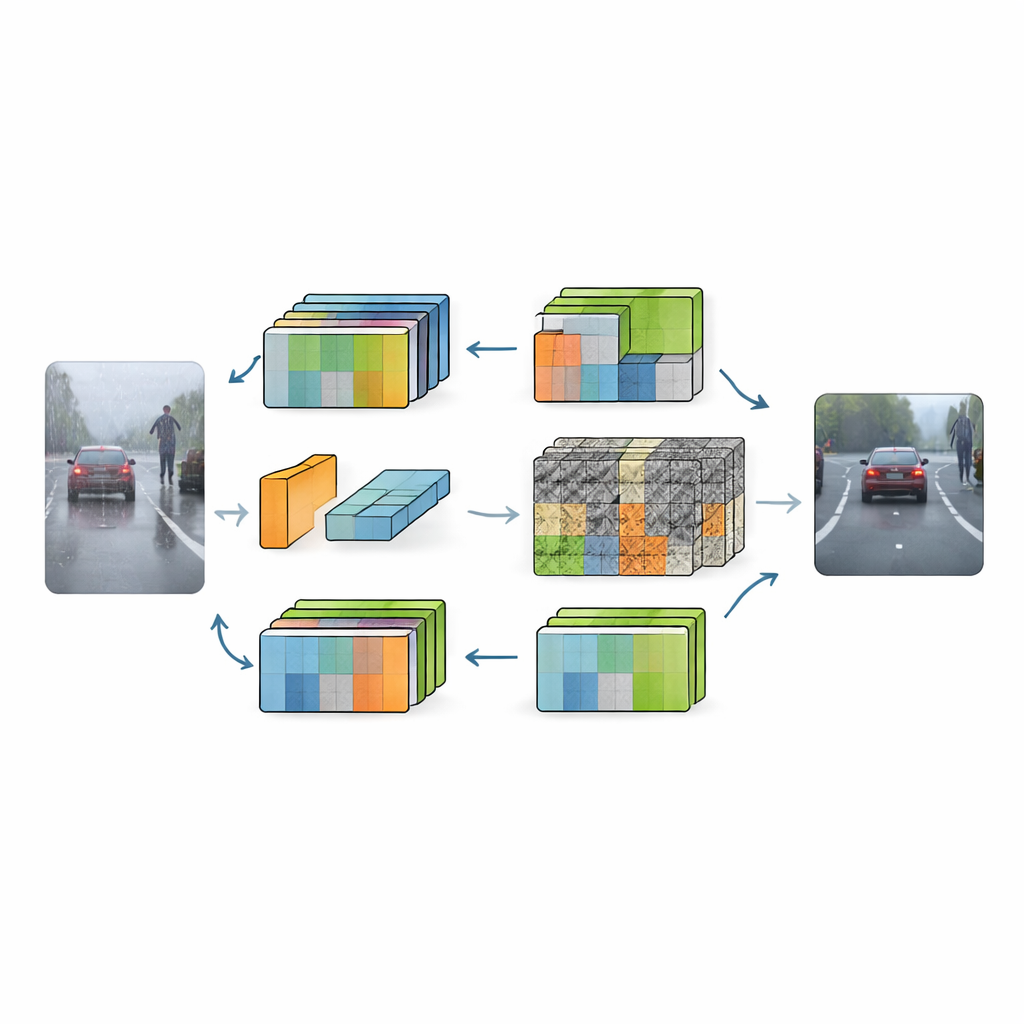
Korzyści w rzeczywistych, trudnych scenach drogowych
Aby przetestować swoje podejście, badacze trenowali RFGLNet na dobrze znanym zbiorze Cityscapes z jasnymi miejskimi scenami w ciągu dnia, a następnie ocenili go na zbiorze ACDC, który koncentruje się na jeździe w deszczu, śniegu, mgle i nocą. Nie widząc nigdy etykiet ACDC podczas treningu, RFGLNet osiągnął średni współczynnik IoU (intersection over union) na poziomie 78,3 procent — przewyższając kilka wiodących metod uogólniania domenowego i adaptacji, z których wiele jest większych i bardziej zasobożernych obliczeniowo. Szczególnie dobrze radził sobie z segmentacją trudnych klas, takich jak ściany i ogrodzenia, których krawędzie łatwo giną w złych warunkach pogodowych. Jednocześnie model działał wydajnie na pojedynczym typowym GPU konsumenckim, przetwarzając dziesiątki obrazów na sekundę, co jest kluczowym wymaganiem dla systemów jazdy w czasie rzeczywistym.
Jaśniejsza wizja dla bezpieczniejszej autonomii
Dla osób nietechnicznych wniosek jest taki, że RFGLNet pokazuje, jak ulepszyć istniejące backbones wizji dla bezpieczniejszej autonomii bez konieczności ciągłego trenowania na każdej możliwej burzy. Poprzez połączenie zwartego strojenia niskiej rangi, filtrowania szumów w dziedzinie częstotliwości oraz grupowanej uwagi przestrzennej system uczy się zachowywać istotną strukturę sceny, jednocześnie odsuwając pogodowy bałagan na bok. W miarę dojrzewania tych metod i treningu na szerszych zbiorach rzeczywistych warunków, mogą one pomóc autonomicznym samochodom i robotom utrzymać niezawodną świadomość sytuacyjną, gdy niebo przyciemnieje, a droga przed nimi nie będzie jasna.
Cytowanie: Ye, X., Shi, X. & Li, Y. RFGLNet for adverse weather domain-generalized semantic segmentation with frequency low-rank enhancement. Sci Rep 16, 8253 (2026). https://doi.org/10.1038/s41598-026-39052-y
Słowa kluczowe: autonomiczne prowadzenie, percepcja w trudnych warunkach pogodowych, segmentacja semantyczna, odporność widzenia komputerowego, uogólnianie domenowe