Clear Sky Science · pl
Duże modele językowe wykazują efekty podobne do Dunninga-Krugera w wielojęzycznym weryfikowaniu faktów
Dlaczego inteligentna weryfikacja faktów ma znaczenie dla wszystkich
Dezinformacja rozprzestrzenia się dziś szybciej niż kiedykolwiek, kształtując przekonania ludzi na temat zdrowia, polityki, nauki i życia codziennego. Wiele platform i redakcji zaczyna polegać na sztucznej inteligencji — zwłaszcza na dużych modelach językowych (LLM) — by pomagać sprawdzać, czy popularne twierdzenia są prawdziwe czy fałszywe. To badanie stawia pozornie proste, lecz kluczowe pytanie: kiedy pozwalamy tym systemom oceniać fakty, jak często mają rację, jak pewnie się wypowiadają i czy to się zmienia w zależności od języka i regionu świata?
Jak badacze testowali AI na prawdziwych plotkach
Zamiast wymyślać sztuczne przykłady, autorzy oparli testy na 5 000 autentycznych twierdzeń, które profesjonalne organizacje weryfikujące fakty na całym świecie już zbadały. Twierdzenia obejmowały 47 języków i pochodziły zarówno z Północy, jak i Południa Globalnego, odzwierciedlając nieuporządkowaną, wielokulturową rzeczywistość internetowych plotek. Uwzględniono tylko te stwierdzenia, którym wielokrotne organizacje weryfikujące przypisały jednoznaczne werdykty „prawda” lub „fałsz”, tworząc mocne dane porównawcze.
Następnie uruchomiono dziewięć powszechnie używanych modeli językowych — od mniejszych otwartoźródłowych systemów po zaawansowane komercyjne — na każdym twierdzeniu. Aby odzwierciedlić sposób, w jaki ludzie rozmawiają z chatbotami, większość promptów miała prostą formę pytań typu „Czy to prawda?” lub „Czy to fałsz?”, zapisanych w tym samym języku co twierdzenie. Czwarta, bardziej profesjonalna konfiguracja używała szczegółowej instrukcji po angielsku, która przekształcała model w wirtualnego weryfikatora faktów i prosiła o uporządkowane odpowiedzi. Ludzie-annotatorzy uważnie czytali odpowiedzi modeli i oznaczali je jako stwierdzające, że twierdzenie jest prawdziwe, fałszywe, albo odmawiające jednoznacznego werdyktu.
Pomiary nie tylko prawda czy fałsz, lecz także kiedy powiedzieć „nie wiem”
Zespół zrobił więcej niż tylko zliczanie trafień i pomyłek. Użyto trzech kluczowych miar, aby uchwycić zachowanie modeli. Po pierwsze, „wybieralna trafność” sprawdzała, jak często model ma rację, gdy rzeczywiście zajmował stanowisko i ogłaszał twierdzenie prawdziwym lub fałszywym. Po drugie, „trafność sprzyjająca powstrzymaniu” traktowała jako akceptowalne — a nawet pożądane — przyznanie niepewności zamiast zgadywania, co jest istotne w wrażliwych obszarach jak medycyna czy wybory. Po trzecie, „wskaźnik stanowczości” śledził, jak często model w ogóle udzielał zdecydowanej odpowiedzi, służąc jako przybliżenie zachowania pewności siebie.
Profesjonalnie sformułowany prompt, z instrukcjami krok po kroku, konsekwentnie zwiększał trafność we wszystkich modelach. Jednocześnie ujawniał kompromis: mniejsze modele często stawały się bardziej zdecydowane bez wzrostu wiarygodności, podczas gdy większe modele dzięki strukturze udzielały mniej, lecz lepszych odpowiedzi. Zwykłe, czatopodobne prompty wywoływały ostrożniejsze zachowanie, zwłaszcza w słabszych modelach, ale też nieco obniżały ich trafność.
Kiedy mniej zdolne systemy zachowują się pewniej niż są
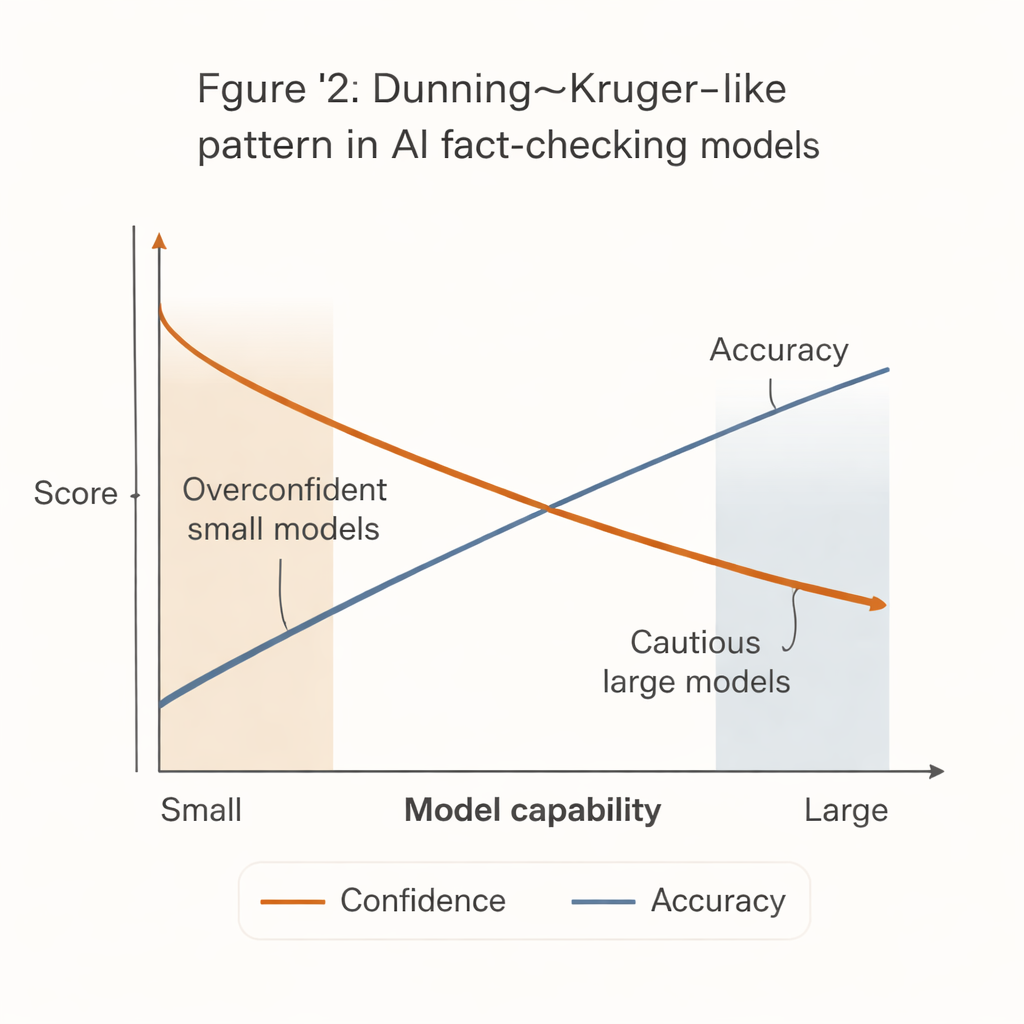
Pojawił się uderzający wzorzec przypominający dobrze znany efekt Dunninga–Krugera w psychologii: najmniej zdolne systemy zachowywały się najbardziej pewnie. Małe, tanie modele miały tendencję do wydawania stanowczych werdyktów dla dużej większości twierdzeń, lecz z zauważalnie niższą trafnością. W przeciwieństwie do nich najsilniejsze modele — takie jak zaawansowane wersje GPT — były znacznie dokładniejsze, gdy się wypowiadały, ale znacznie częściej się powstrzymywały, szczególnie wobec trudnych lub niejednoznacznych stwierdzeń.
Ta „przepaść między pewnością a kompetencją” ma konsekwencje w świecie rzeczywistym. Wiele redakcji, organizacji społeczeństwa obywatelskiego i lokalnych zespołów weryfikujących faktów, które dysponują ograniczonymi środkami, nie może pozwolić sobie na najpotężniejsze systemy AI. Częściej będą sięgać po mniejsze, tańsze modele, które wydają się zdecydowane, ale częściej się mylą. Jeśli takie narzędzia zostaną włączone do procesów pracy lub systemów moderacji społeczności bez ostrożnych zabezpieczeń, mogą w rzeczywistości wzmacniać dezinformację, generując pewne, lecz błędne weryfikacje faktów.
Nierówna wydajność w zależności od języka i regionu
Badanie pokazuje także, że te systemy nie działają równie dobrze dla wszystkich. W kilku głównych językach modele generalnie radziły sobie najlepiej na treściach anglojęzycznych i nieco gorzej na portugalskich i hindi. Większe modele miały tendencję do bardziej ostrożnych odpowiedzi w językach innych niż angielski, ale mimo to przewyższały mniejsze modele pod względem trafności. Porównanie twierdzeń związanych z Północą i Południem Globalnym wykazało, że większość modeli miała większe trudności z tymi z regionu Globalnego Południa. Mniejsze systemy często pozostawały pewne siebie przy spadku trafności, podczas gdy duże modele wykazywały większy spadek stanowczości, ale mniejszy spadek poprawności, co sugeruje, że wyczuwały własną niepewność i wstrzymywały się.
Co to oznacza dla przyszłości wiarygodnych narzędzi AI
Dla osoby niebędącej specjalistą główne przesłanie jest jasne: dzisiejsze AI do weryfikacji faktów są dalekie od równości, a te najbardziej dostępne mogą być najbardziej mylące. Potężne modele mogą być ostrożne i dokładne, lecz są kosztowne i czasem nadmiernie wstrzemięźliwe. Słabsze modele są śmiałe, ale bardziej skłonne do błędu, zwłaszcza poza językiem angielskim i w relacjach z Globalnego Południa. Autorzy argumentują, że AI powinna wspierać, a nie zastępować, ludzkich weryfikatorów faktów, a decyzje polityczne i projektowe muszą dążyć do lepszej kalibracji — czyli uczenia systemów, kiedy milczeć — oraz do sprawiedliwszego dostępu do wysokiej jakości narzędzi. W przeciwnym razie ta sama technologia, która ma zwalczać dezinformację, może pogłębić nierówności informacyjne, które ma rozwiązać.
Cytowanie: Qazi, I.A., Khan, Z., Ghani, A. et al. Large language models show Dunning-Kruger-like effects in multilingual fact-checking. Sci Rep 16, 7594 (2026). https://doi.org/10.1038/s41598-026-39046-w
Słowa kluczowe: dezinformacja, weryfikacja faktów, duże modele językowe, pewność AI, wielojęzyczne uprzedzenia