Clear Sky Science · pl
Hybrydowa ramowa sieć LSTM-GRU do klasyfikacji raka płuca z użyciem algorytmu GWO-WOA do strojenia hiperparametrów i BPSO do selekcji cech
Dlaczego to ma znaczenie dla codziennego zdrowia
Wczesne wykrycie raka płuca może ratować życie, lecz wiele osób nie przechodzi zaawansowanych badań aż do momentu, gdy jest za późno. Badanie to sprawdza, czy proste kontrolne kwestionariusze — dotyczące wieku, palenia, objawów i codziennych zwyczajów — można połączyć z nowoczesną sztuczną inteligencją, aby wykrywać osoby wysokiego ryzyka na długo przed pojawieniem się ciężkiej choroby. Dzięki maksymalnemu wykorzystaniu tanich ankiet i inteligentnych modeli komputerowych, praca wskazuje drogę do szybszych, bardziej dostępnych narzędzi przesiewowych, które w przyszłości mogłyby wspierać lekarzy i programy zdrowia publicznego na całym świecie.
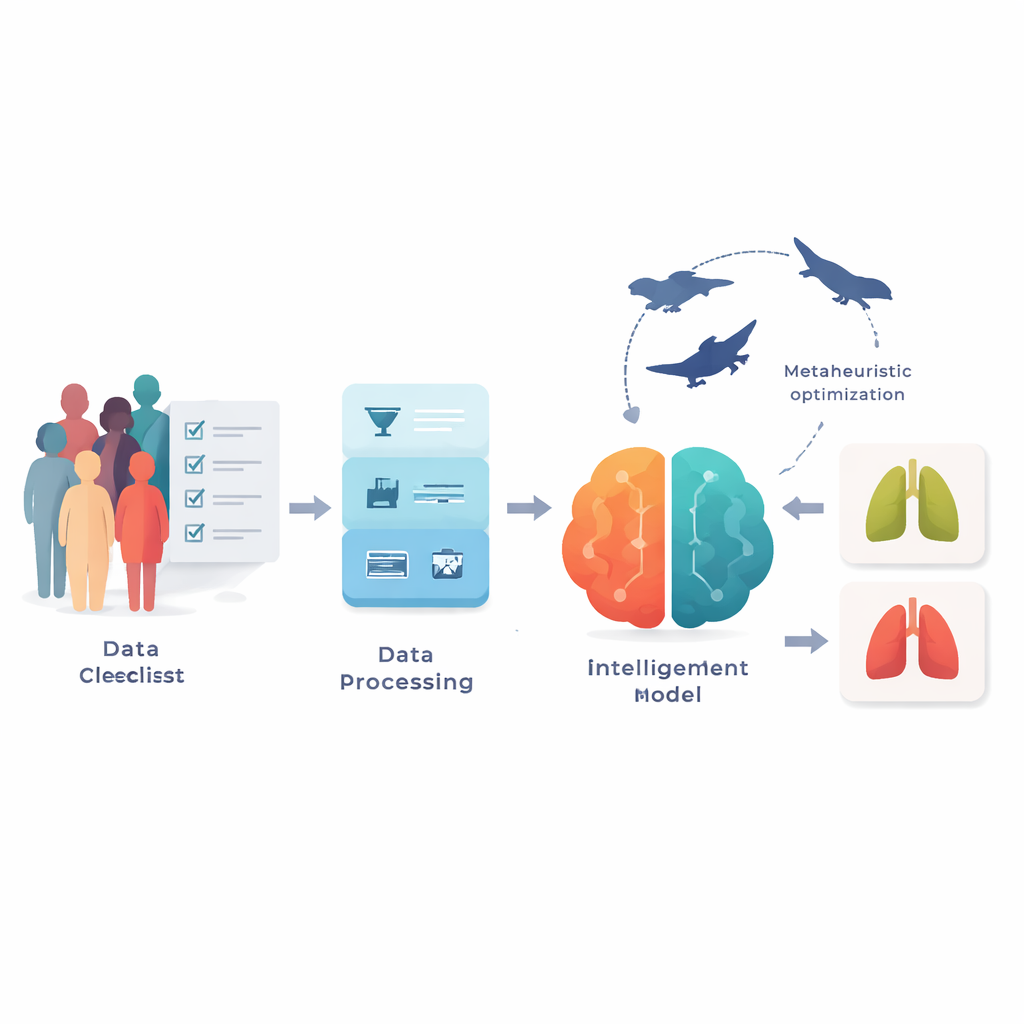
Przekształcanie prostych pytań w użyteczne sygnały
Badacze pracowali z dwoma publicznymi zestawami danych ze strony Kaggle, obejmującymi łącznie ponad 3 300 osób. Zamiast obrazów medycznych każdy rekord zawiera 15 pozycji, które można spotkać na formularzu klinicznym: wiek, płeć, status palenia, zażółcenie palców, kaszel, duszność, ból w klatce piersiowej oraz podobne czynniki ryzyka i objawy, a także etykietę wskazującą, czy stwierdzono raka płuca. Ponieważ dane ankietowe z rzeczywistego świata są nieuporządkowane, zespół najpierw oczyścił informacje, uzupełniając brakujące wpisy, usuwając duplikaty i ujednolicając sposób kodowania odpowiedzi w obu zestawach. Dostosowano też wartości, tak aby wszystkie cechy miały podobną skalę, oraz zastosowano metodę wyrównania klas, aby skorygować silne przesunięcie w stronę przypadków raka w mniejszym zbiorze danych, co pomogło modelowi uniknąć uprzedzeń polegających na przewidywaniu wyłącznie klasy dominującej.
Pozwolenie komputerowi wybrać najbardziej istotne pytania
Niekóre pytania w formularzu nie są równie pomocne w wykrywaniu choroby, a użycie zbyt wielu może model jedynie zdezorientować. Aby skupić się na tym, co najistotniejsze, autorzy zastosowali strategię poszukiwania inspirowaną rojem — Binary Particle Swarm Optimization. Mówiąc prościej, równolegle testuje się wiele kandydackich „zbiorów pytań”, które poruszają się w przestrzeni rozwiązań, kopiując i udoskonalając najlepsze rozwiązania. Z czasem proces ten wyselekcjonował zwięzłe zestawy obejmujące około siedmiu kluczowych pytań, wielokrotnie wyróżniając cechy takie jak palenie, zażółcenie palców, kaszel, ból w klatce piersiowej, świszczący oddech, duszność i choroby przewlekłe. Takie ukierunkowane zestawy poprawiły dokładność o kilka punktów procentowych w porównaniu z użyciem wszystkich 15 pytań, a jednocześnie uczyniły ostateczny model łatwiejszym do interpretacji i szybszym w działaniu.

Mądrzejszy silnik do wyłuskiwania wzorców z odpowiedzi
Aby przekształcić odpowiedzi z kwestionariusza w przewidywanie tak/nie dotyczące raka, zespół zbudował model hybrydowy łączący dwie pokrewne jednostki uczenia głębokiego często stosowane do sekwencji: Long Short-Term Memory (LSTM) oraz Gated Recurrent Unit (GRU). Choć odpowiedzi w ankietach nie są szeregiem czasowym jak mowa czy wideo, grupy objawów i nawyków tworzą wzorce, które można potraktować jako krótkie sekwencje. Model najpierw przekazuje wybrane pytania przez warstwy LSTM, które potrafią selektywnie przechowywać i zapominać informacje, a następnie przez warstwy GRU, które dopracowują te wzorce przy mniejszej liczbie wewnętrznych kroków i niższym koszcie obliczeniowym. Aby uniknąć projektowania metodą prób i błędów, autorzy dostroili istotne ustawienia — takie jak współczynnik uczenia, liczba jednostek ukrytych, rozmiar partii i dropout — przy użyciu drugiej warstwy poszukiwań inspirowanych naturą, łączącej szerokie eksploracje „szarych wilków” z precyzyjnymi korektami „wielorybów”. Ten złożony optymalizator wyszukuje kombinacje hiperparametrów, które konsekwentnie dają wysoką dokładność w trakcie walidacji krzyżowej.
Jak dobrze system działał
Po treningu model hybrydowy LSTM–GRU porównano z kilkoma mocnymi punktami odniesienia, w tym z samodzielnymi sieciami LSTM i GRU, siecią konwolucyjną, klasycznymi maszynami wektorów nośnych oraz metodami drzewiastymi takimi jak lasy losowe i gradient boosting. W mniejszym zbiorze danych dla 309 osób zaproponowany system poprawnie sklasyfikował każdy przypadek w wydzielonym teście, osiągając 100% dokładności, precyzji, czułości i F1-score. W większym zbiorze około 3 000 osób utrzymał niemal doskonałe wyniki, z około 99,3% dokładnością i podobnie wysokimi wartościami innych miar, przewyższając wszystkie rywalizujące modele zarówno głębokie, jak i klasyczne. Autorzy wykazali również, że ich dwuetapowa strategia — najpierw selekcja pytań za pomocą poszukiwań typu rojowego, a następnie strojenie hybrydowej sieci za pomocą optymalizatora wilków i wielorybów — dała bardziej stabilne wyniki w powtarzanych przebiegach walidacji krzyżowej niż prostsze konfiguracje.
Co to oznacza dla przyszłych badań przesiewowych płuc
W praktycznych słowach praca pokazuje, że starannie zaprojektowany system AI może odczytywać zwykłe odpowiedzi z kwestionariuszy i bardzo dokładnie rozróżniać osoby z rakiem płuca i bez niego na bazowych zestawach danych. Nie zastępuje to badań obrazowych, lekarzy ani badań klinicznych, a autorzy podkreślają, że ich dane są ograniczone i nie są jeszcze gotowe do bezpośredniego zastosowania w szpitalach. Mimo to podejście demonstruje, że połączenie inteligentnej selekcji pytań z precyzyjnie dostrojonymi silnikami uczenia głębokiego może przekształcić niskokosztowe formularze w potężne narzędzia wczesnego ostrzegania. Przy dalszych testach na większych, klinicznie skuratowanych populacjach oraz lepszych metodach wyjaśniania, dlaczego model oznacza daną osobę jako wysokiego ryzyka, podobne systemy mogłyby kiedyś pomagać w decydowaniu, kogo skierować na bardziej szczegółowe badania obrazowe, wspierając wcześniejszą diagnozę przy jednoczesnym zachowaniu opłacalności i nienaruszalności przesiewów.
Cytowanie: Amrir, M.M.S., Ayid, Y.M., Elshewey, A.M. et al. A hybrid LSTM-GRU framework for lung cancer classification using GWO-WOA algorithm for hyperparameter tuning and BPSO for feature selection. Sci Rep 16, 8600 (2026). https://doi.org/10.1038/s41598-026-39020-6
Słowa kluczowe: badania przesiewowe raka płuca, dane z kwestionariuszy, uczenie głębokie, selekcja cech, medyczna sztuczna inteligencja