Clear Sky Science · pl
Strategia sterowania humanoidalnego oparta na głębokim uczeniu ze wzmocnieniem dla zwiększenia komfortu w robotach rehabilitacji kończyn dolnych
Roboty, które pomagają ludziom znów chodzić
Kiedy ktoś ma trudności z chodzeniem po udarze lub urazie rdzenia kręgowego, terapia może być powolna, męcząca i niekomfortowa. Roboty rehabilitacji kończyn dolnych są zaprojektowane tak, by podtrzymywać i prowadzić nogi pacjenta podczas ćwiczeń, ale współczesne maszyny często sprawiają wrażenie sztywnych i „robotycznych”. W tym badaniu analizuje się, jak wyposażenie tych robotów w bardziej ludzki sposób „myślenia” — przy użyciu zaawansowanych algorytmów uczenia — może uczynić trening łagodniejszym, bardziej naturalnym i ostatecznie skuteczniejszym dla pacjentów.
Dlaczego ćwiczenia chodzenia muszą być naturalne
W miarę starzenia się społeczeństw coraz więcej osób boryka się z poważnymi problemami chodzenia i wiele z nich korzysta z rehabilitacji wspomaganej robotycznie. Tradycyjne roboty realizują zaprogramowane trajektorie kończyn i stosują proste reguły sterowania stawami. Choć są niezawodne, te metody mają problem z nieporządkiem rzeczywistego ruchu ludzkiego: chód każdej osoby jest nieco inny, a sztywny robot może pociągać lub popychać w sposób, który wydaje się niezręczny, a nawet bolesny. Autorzy argumentują, że aby rehabilitacja była skuteczna, robot musi nie tylko utrzymywać pacjenta w pozycji i wprawiać go w ruch, lecz także dostosowywać się do naturalnych wzorców chodu i minimalizować siły oddziałujące na ciało.
Nauka na podstawie prawdziwych kroków
Aby nauczyć robota, jak naprawdę chodzą ludzie, badacze najpierw zbudowali uproszczony model matematyczny nóg i tułowia. Następnie zarejestrowali dane chodu od pięciu zdrowych ochotników, używając precyzyjnego systemu analizy ruchu 3D i płyt siłowych w podłodze. Odbijające się markery na biodrach, kolanach, kostkach i tułowiu pozwoliły obliczyć, jak każdy staw poruszał się w trakcie pełnego kroku, podczas gdy czujniki pod stopami mierzyły, z jaką siłą każda noga naciskała podłoże. Z tych pomiarów utworzono gładkie krzywe odniesienia dla kątów bioder i kolan oraz śledzono, jak zmieniały się siły w stawach w czasie, uchwytując zarówno kształt, jak i rytm normalnego chodu.
Sprytniejszy regulator, który nadal działa bezpiecznie
Rdzeniem artykułu jest nowa humanoidalna strategia sterowania łącząca głębokie uczenie ze wzmocnieniem (DRL) z klasycznym regulatorem proporcjonalno-różniczkującym (PD). DRL to rodzaj sztucznej inteligencji, w którym wirtualny agent próbuje działań, obserwuje rezultaty i stopniowo odkrywa, co działa najlepiej, maksymalizując sygnał nagrody. W tym przypadku agent działa ponad warstwą PD: obserwuje kąty i prędkości stawów robota i decyduje, jakie momenty przyłożyć, podczas gdy warstwa PD zapewnia, że stawy nie odbiegają zbyt daleko od bezpiecznych, przypominających ludzkie kątów docelowych. Funkcja nagrody została starannie zaprojektowana, by promować stabilne ruchy w przód, jednocześnie karząc wszystko, co mogłoby być nieprzyjemne dla pacjenta — takie jak szarpane ruchy, duże siły w stawach czy niebezpieczne postawy, np. nadmierne pochylenie lub niskie unoszenie stopy.
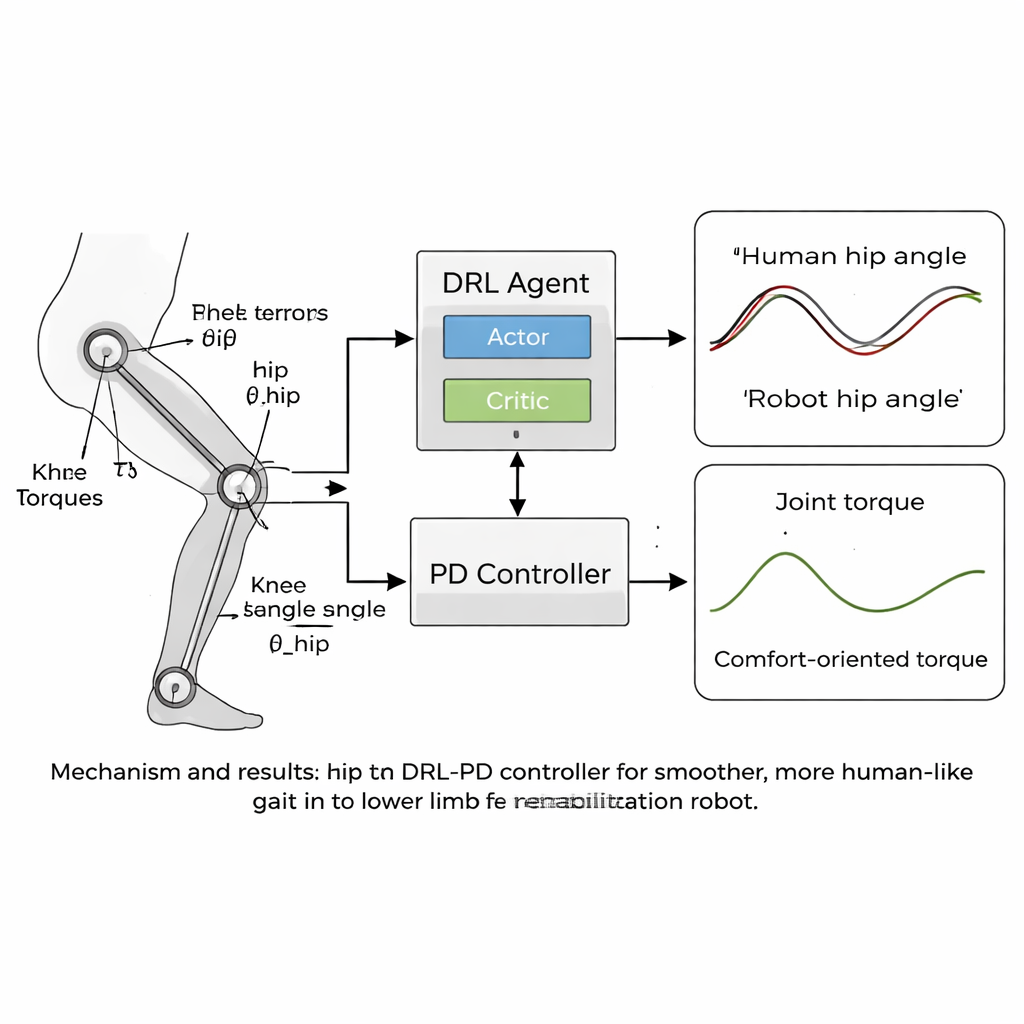
Płynniejszy ruch, bliższy ludzkiemu chodu
Zespół przetestował swoje podejście w symulacjach komputerowych, używając modelu robota rehabilitacyjnego kończyn dolnych z biodrami i kolanami dopasowanymi do danych chodu. W trakcie tysięcy epizodów treningowych regulator DRL-PD nauczył się wytwarzać powtarzalny cykl chodu, w którym kąty stawów ściśle śledziły wzorce referencyjne ludzi. Biodra i kolana robota poruszały się w regularnych, stabilnych pętlach, co świadczy o niezawodnym, powtarzalnym chodu. Co istotne, momenty potrzebne do napędzania stawów stały się gładsze i mniejsze w porównaniu ze standardowym regulatorem PD. Pomiary ilościowe wykazały, że błędy śledzenia spadły do zaledwie kilku setnych radiana, a tempo zmian momentów stawowych — będące wskaźnikiem „szarpania”, jakie pacjent odczuwałby — zmniejszyło się o ponad połowę. Regulator pozostał też stabilny, nawet gdy masy nóg modelu zmieniały się o kilka procent, co sugeruje, że może tolerować różnice między rzeczywistymi użytkownikami.
Co to oznacza dla przyszłych robotów rehabilitacyjnych
Dla osób niebędących specjalistami główne przesłanie jest proste: pozwalając robotowi nauczyć się rytmów i ograniczeń ludzkiego chodu na podstawie danych empirycznych oraz nagradzając go za płynność i delikatność, możemy projektować maszyny, które pomagają ćwiczyć chód w sposób bardziej naturalny i mniej stresujący. Pacjenci mogą chcieć uczestniczyć w dłuższych i częstszych sesjach, jeśli robot porusza się z nimi, a nie przeciwko nim. Chociaż obecne wyniki pochodzą z symulacji i wymagają dużej mocy obliczeniowej do treningu, po zakończeniu uczenia się regulator może działać efektywnie na rzeczywistych urządzeniach. Autorzy postrzegają tę pracę jako krok w kierunku spersonalizowanych, adaptacyjnych robotów rehabilitacyjnych, które dostosowują się do unikalnego chodu i potrzeb komfortu każdego pacjenta, co potencjalnie poprawi zarówno rekonwalescencję, jak i jakość życia.
Cytowanie: Jin, Y., Zhang, J., Li, W. et al. A humanoid control strategy based on deep reinforcement learning for enhanced comfort in lower limb rehabilitation robots. Sci Rep 16, 7370 (2026). https://doi.org/10.1038/s41598-026-39011-7
Słowa kluczowe: roboty rehabilitacyjne, trening chodu, głębokie uczenie ze wzmocnieniem, egzoszkielet, komfort pacjenta