Clear Sky Science · pl
Porównawcza ocena modeli uczenia maszynowego do prognozowania dobowego przepływu wód w subtropikalnym dorzeczu monsunowym
Dlaczego prognozy rzek mają znaczenie dla codziennego życia
Rzeki w regionach monsunowych mogą w kilka godzin przejść ze stanu ciszy do katastrofy, zagrażając życiu, domom i źródłom wody. Dokładne przewidywanie, ile wody przepłynie rzeką każdego dnia, leży u podstaw ostrzeżeń powodziowych, zarządzania zbiornikami i dostaw wody do miast. W tym badaniu przeanalizowano subtropikalny system rzeczny w południowych Chinach i postawiono praktyczne pytanie o globalnym znaczeniu: które z popularnych dziś narzędzi uczenia maszynowego rzeczywiście najlepiej prognozują dzienny przepływ rzeki, szczególnie podczas niebezpiecznych wezbrań?
Rzeka podatna na burze pod presją
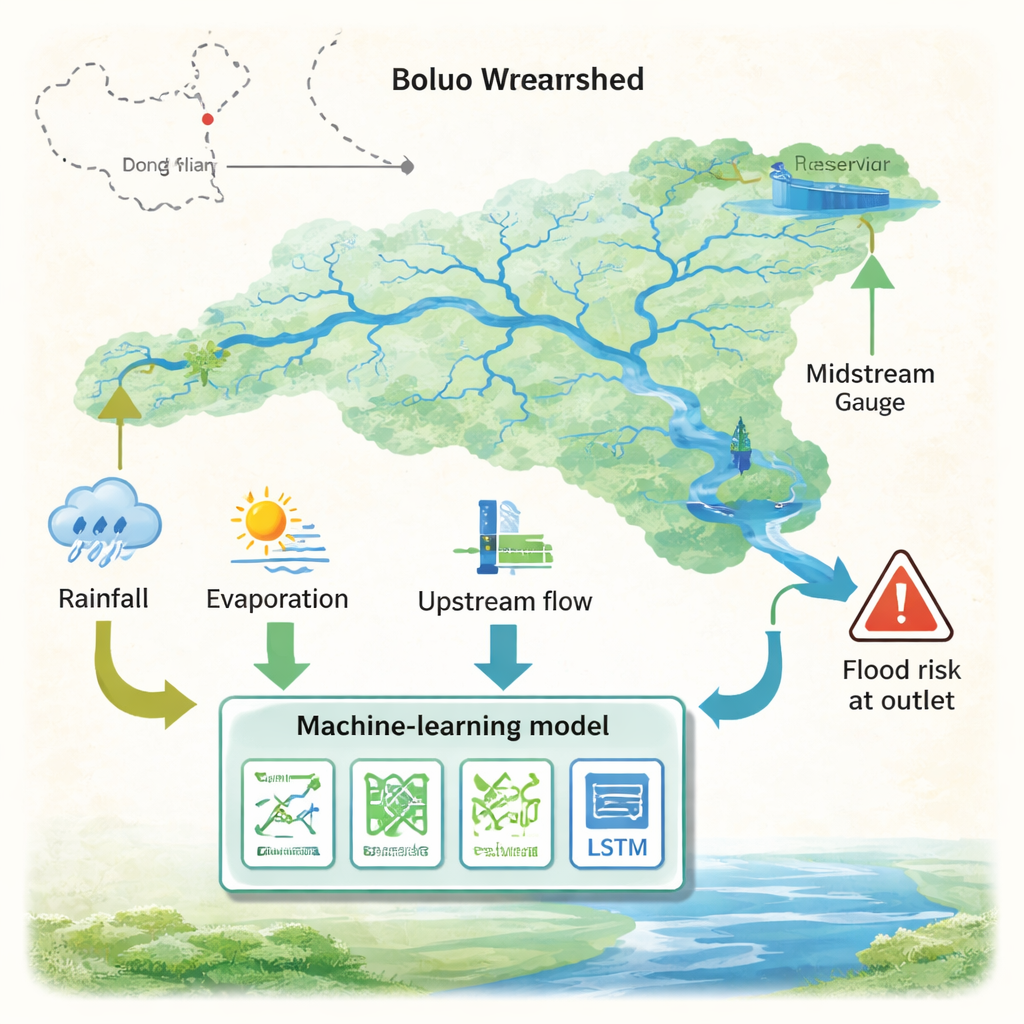
Badanie koncentruje się na dorzeczu Boluo, będącym częścią rzeki Dongjiang, która dostarcza wodę do Guangdong–Hong Kong–Macao Greater Bay Area. Region ma typowy klimat monsunowy: większość opadów przypada na kilka intensywnych miesięcy, często związanych z frontami atmosferycznymi i tajfunami. Do tej naturalnej zmienności dochodzi duży zbiornik retencyjny i inne działania człowieka, które zmieniają czas i wielkość przepływów. Autorzy zgromadzili dziesięciolecia dobowych danych z deszczomierzy, stacji pogodowych i miar przepływu w kluczowych punktach, a następnie podzielili zapisy na lata treningowe i testowe, by naśladować warunki rzeczywistego prognozowania. Pozwoliło to sprawdzić, jak różne algorytmy radzą sobie z systemem rzecznym silnie sezonowym i intensywnie zarządzanym.
Siedem cyfrowych prognostyków w bezpośrednim porównaniu
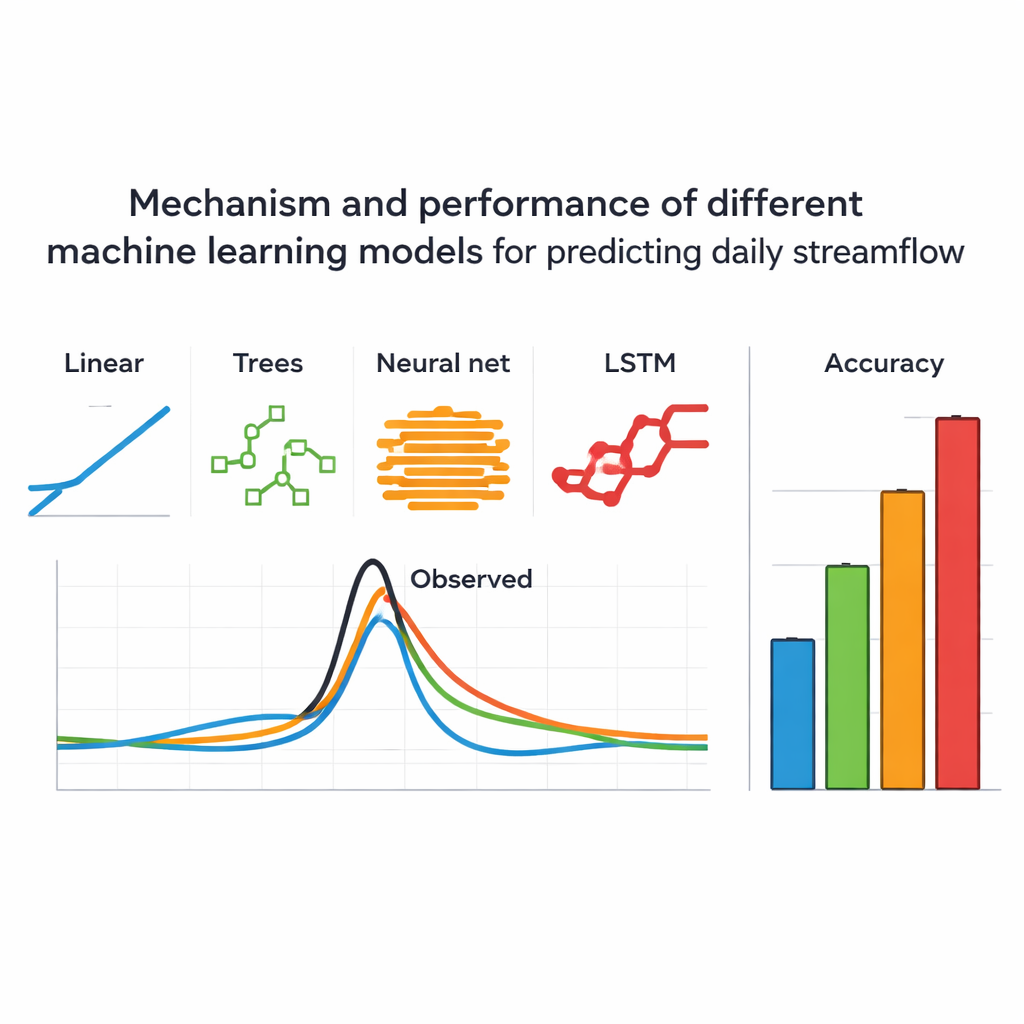
Zespół porównał siedem powszechnie stosowanych modeli uczenia maszynowego: prostą regresję liniową, trzy typy zespołów opartych na drzewach (Random Forest, Extra Trees i Gradient Boosting, w tym XGBoost), klasyczną sieć neuronową oraz bardziej zaawansowaną sieć LSTM (Long Short‑Term Memory) zaprojektowaną do pracy z danymi sekwencyjnymi. Każdy model został starannie dostrojony przy użyciu tych samych procedur i oceniony za pomocą kilku miar dokładności. W szerokim zakresie warunków wszystkie siedem modeli generowało w miarę dobre prognozy, co potwierdza, że podejścia oparte na danych są potężnym narzędziem do przewidywania zachowania rzek. Pojawiły się jednak wyraźne różnice. Model LSTM okazał się najlepszy, nieco wyprzedzając konwencjonalną sieć neuronową, podczas gdy prosty model liniowy zachował się zaskakująco dobrze i przewyższył wszystkie metody oparte na drzewach.
Jak modele zachowują się, gdy rzeki szaleją
Powodzie to sytuacje, w których prognozy mają największe znaczenie, więc autorzy skupili się na dniach o wysokim przepływie i na trzech największych wydarzeniach powodziowych w rejestrze. W tych ekstremalnych warunkach kontrasty się pogłębiły. LSTM utrzymał przewagę, pozostając najbardziej dokładnym, gdy przepływy przekraczały 90., 95. i nawet 99. percentyl — dni, gdy rzeka jest najbardziej niebezpieczna. Model nadal nieco niedoszacowywał niektórych szczytów, ale zwykle o mniej niż 20 procent. Standardowa sieć neuronowa radziła sobie przyzwoicie, natomiast modele drzewiaste często nie trafiały w rozmiary szczytów o 30–50 procent i w najwyższych przepływach wypadały gorzej niż proste użycie długoterminowej średniej. Mimo to większość modeli poprawnie określała dzień wystąpienia szczytu z dokładnością około jednego dnia, co jest kluczowe dla wydawania ostrzeżeń, nawet jeśli dokładna wysokość jest nieco błędna.
Co naprawdę napędza wahania rzeki
Aby wyjść poza „czarne skrzynki” prognoz, badanie zbadało, które dane wejściowe miały największe znaczenie dla modeli. Kilka technik, w tym metoda inspirowana teorią gier zwana SHAP, wskazało na tę samą odpowiedź: dominującym czynnikiem prognoz był przepływ mierzony na górnym wodowskazie o nazwie Lingxia. Innymi słowy, poziom rzeki w górze z dnia poprzedniego był przeważnie bardziej informatywny niż dzisiejsze sumy opadów. Odzwierciedla to rodzaj hydrologicznej pamięci, w której rzeka integruje wpływ niedawnych burz, wilgotności gleby i wód gruntowych w swój aktualny przepływ. Gdy badacze usunęli dane o przepływie z górnego wodowskazu, umiejętność LSTM spadła gwałtownie; gdy usunęli dane o opadach, wydajność zmieniła się nieznacznie. Sugeruje to, że w dobowym prognozowaniu dla tego dorzecza śledzenie tego, ile wody już znajduje się w systemie, może być ważniejsze niż instalowanie większej liczby deszczomierzy.
Co wyniki oznaczają dla bezpieczeństwa przeciwpowodziowego
Dla osób niebędących specjalistami główny wniosek jest prosty: inteligentne modele, które pamiętają warunki z poprzedniego dnia, takie jak LSTM, mogą dostarczać bardziej wiarygodne prognozy rzek niż wiele popularnych alternatyw, zwłaszcza gdy nadciągają powodzie. Jednocześnie dobrze zaprojektowany, prosty model wciąż może być zaskakująco skuteczny, zwłaszcza gdy dostępne są dobre pomiary przepływu w górnym biegu. Praca podkreśla, że poprawa prognoz powodziowych to nie tylko kwestia stosowania bardziej wyrafinowanych algorytmów czy większej ilości danych o opadach; chodzi o uchwycenie wbudowanej pamięci rzeki i łączenie narzędzi opartych na danych z rozumieniem procesów fizycznych. Takie postępy mogą pomóc zarządcom wodnymi w regionach monsunowych podejmować wcześniejsze i pewniejsze decyzje, gdy nadciąga kolejna duża burza.
Cytowanie: Zhang, Z., Xiao, Y., Chen, R. et al. Comparative assessment of machine learning models for daily streamflow prediction in a subtropical monsoon watershed. Sci Rep 16, 7341 (2026). https://doi.org/10.1038/s41598-026-38969-8
Słowa kluczowe: prognozowanie przepływu, prognozowanie powodzi, uczenie maszynowe, sieci neuronowe LSTM, rzeki monsunowe