Clear Sky Science · pl
Dostrajane duże modele językowe z uporządkowanymi promptami umożliwiają efektywne budowanie grafów wiedzy o raku płuca
Dlaczego zamienianie tekstów medycznych w mapy ma znaczenie
Rak płuca jest jednym z najgroźniejszych nowotworów na świecie, a informacje o jego diagnozowaniu i leczeniu są rozproszone w artykułach naukowych, notatkach szpitalnych, konsultacjach online i księgach przypadków medycyny tradycyjnej. Lekarze i naukowcy mają problem z nadążaniem za tym zalewem tekstu. Badanie to analizuje nowy sposób automatycznego przekształcania tej rozproszonej wiedzy w jedną, nawigowalną „mapę” — graf wiedzy o raku płuca — wykorzystując dostrojony duży model językowy i starannie skonstruowane promptowanie. Efekt ma ułatwić komputerowe wyszukiwanie złożonej wiedzy medycznej i wspierać ekspertów w narzędziach wspomagania decyzji.
Z rozproszonych opowieści do powiązanych faktów
Autorzy koncentrują się na prostej idei: jeśli można wiarygodnie wydobyć z tekstu informacje kto-co-z czym robi, można poszyćć te fakty w graf. W praktyce oznacza to konwersję swobodnych zdań w małe elementy budulcowe zwane trójkami — pary bytów powiązane relacją, na przykład „rak płuca – leczony przez – chemioterapia.” Tradycyjne metody tworzenia takich grafów wymagają albo armii anotatorów, albo kruchych reguł, które nie uchwycą niuansów i nowych odkryć. Aby to przezwyciężyć, zespół dostraja istniejący chiński duży model językowy, ChatGLM-6B, tak aby specjalizował się w wykrywaniu medycznie istotnych trójek dotyczących raka płuca w szerokim wachlarzu źródeł — od internetowych rozmów pacjent–lekarz po zorganizowane bazy danych i zapisy medycyny tradycyjnej chińskiej. 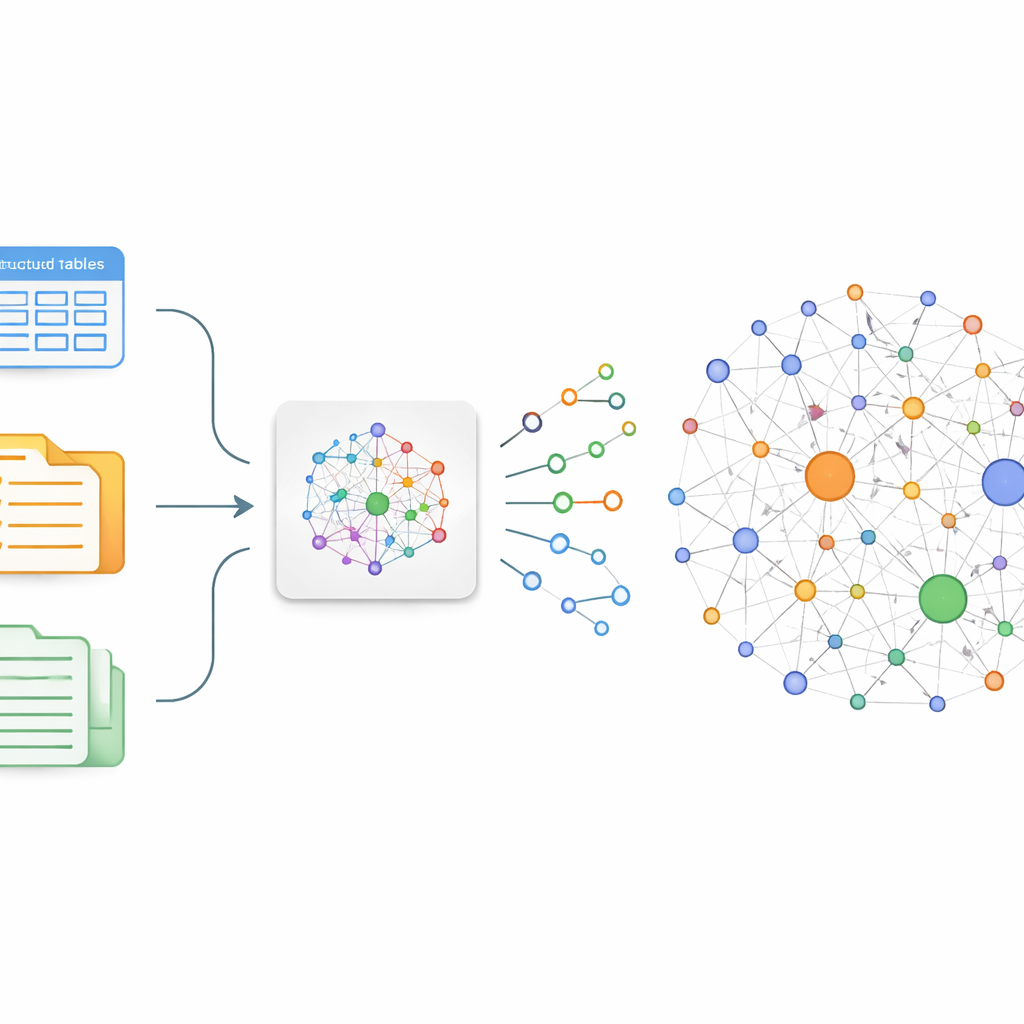
Nauczanie SI myślenia w schludnych jednostkach
Proste poproszenie ogólnego modelu językowego o „wyciągnięcie informacji” często daje chaotyczne, rozwlekłe odpowiedzi. Badacze zaprojektowali więc rygorystyczny schemat promptów i dostroili model na prawie 50 000 przykładów poprawnego zachowania. Każdy przykład pokazuje instrukcję i dokładny, oczekiwany wynik w stylu trójki. Prompt nakazuje modelowi zachowywać się jak profesjonalny ekspert w ekstrakcji tekstu, generować wyłącznie ustrukturyzowane trójki w formacie czytelnym dla komputera oraz „myśleć krok po kroku”, gdy zdania zawierają zagnieżdżone szczegóły — na przykład leczenie, użyty lek i jego dawkę. To połączenie nadania roli, zasad formatu i rozumowania krokowego przekształca model — teraz nazwany KGLM — z asystenta konwersacyjnego w zdyscyplinowany ekstraktor faktów gotowych do obróbki maszynowej.
Scalanie wielu źródeł w jeden przejrzysty graf
Surowe trójki wyodrębnione z tekstu to tylko część procesu. Ta sama choroba lub lek często występuje pod różnymi nazwami — na przykład „przewlekła obturacyjna choroba płuc” versus „POChP.” Aby uniknąć bałaganu i niejasności, autorzy opracowali etap fuzji, który łączy równoważne byty pochodzące z trzech strumieni danych: nieustrukturyzowanego tekstu internetowego, półustrukturyzowanych przypadków klinicznych oraz istniejących medycznych grafów wiedzy. Najpierw szybkie sprawdzenie podobieństwa ciągów znaków wyłapuje oczywiste dopasowania. Gdy to nie wystarcza, głębszy model podobieństwa semantycznego (Sentence-BERT) porównuje znaczenia w kontekście. Byty uznane za duplikaty są konsolidowane w jeden kanoniczny węzeł, z preferencją krótszych nazw, a inne formy przechowywane są jako aliasy. Eksperci następnie przeglądają przypadki brzegowe i usuwają mylące lub niskiej jakości stwierdzenia, co daje czyściejszy i bardziej spójny graf wiedzy o raku płuca przechowywany w bazie Neo4j. 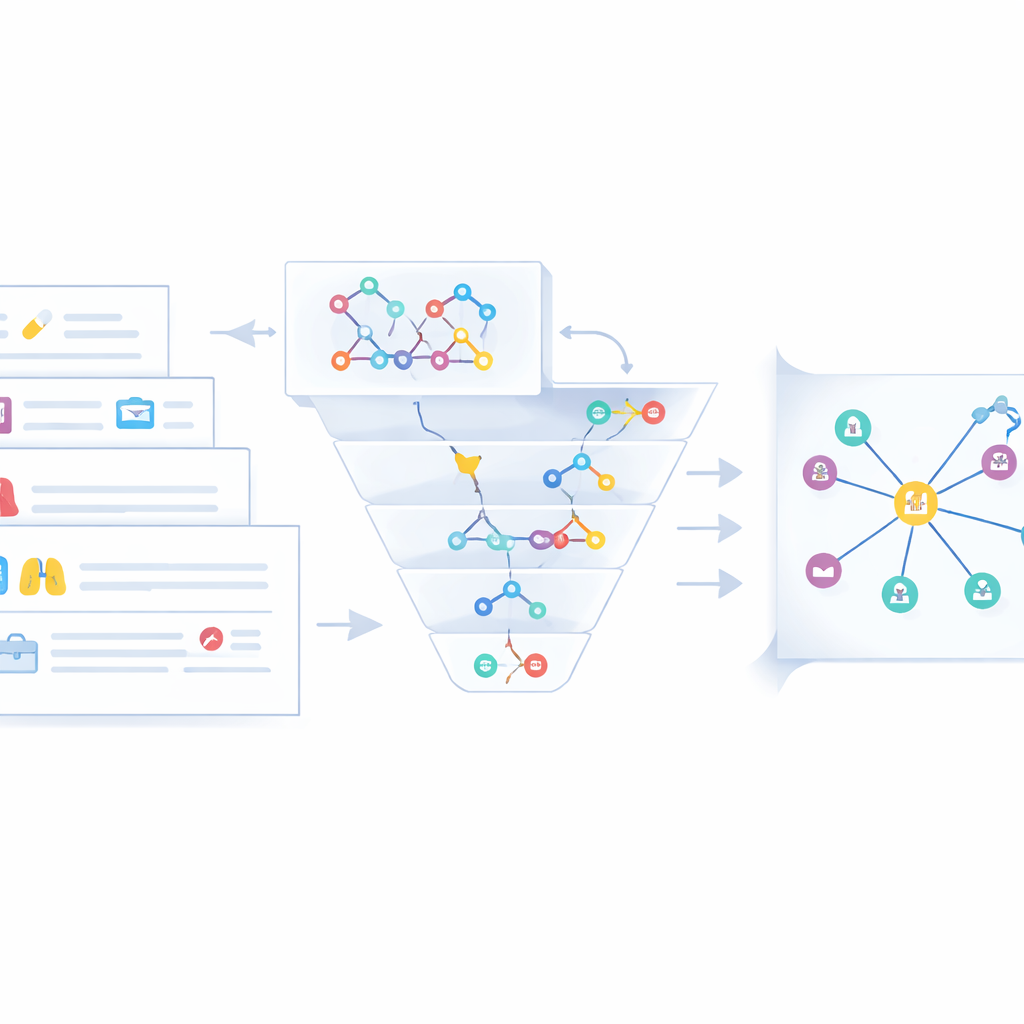
Jak dobrze działa ta mapa wiedzy?
Aby ocenić wydajność, zespół porównuje KGLM ze standardowymi podejściami głębokiego uczenia opartymi na BERT i sieciach konwolucyjnych, a także z oryginalnym, niedostrojonym modelem ChatGLM. W zadaniu ekstrakcji relacji — decydowania, które byty są powiązane i w jaki sposób — dostrojony KGLM prowadzony promptami osiąga wynik F1 około 0,82, przewyższając wszystkie testowane bazowe modele i poprawiając wynik o około 25 procent w porównaniu z modelem wyjściowym. Testy ablaacyjne pokazują, że każdy element promptu ma znaczenie: usunięcie roli eksperta, rygorystycznego formatu trójek lub wskazówki „myśl krok po kroku” pogarsza dokładność, szczególnie dla złożonych zdań z zagnieżdżonymi atrybutami lub terminologią medycyny tradycyjnej chińskiej. Panel ekspertów klinicznych i informatycznych również ocenił, że otrzymany graf jest dokładniejszy, bardziej użyteczny i bardziej istotny klinicznie niż grafy zbudowane bez dostrajania lub ustrukturyzowanych promptów.
Co to oznacza dla przyszłych narzędzi medycznych
Mówiąc prosto, badanie pokazuje, że przy odpowiednim treningu i instrukcjach duży model językowy potrafi efektywnie przekształcać chaotyczne, rzeczywiste teksty o raku płuca w ustrukturyzowaną, przeszukiwalną sieć faktów. Ten graf wiedzy o raku płuca, choć nadal prototyp badawczy i ograniczony do źródeł w języku chińskim oraz jednej dziedziny chorobowej, wskazuje na przyszłość, w której stale aktualizowane „mapy wiedzy” mogłyby wspierać systemy wspomagania decyzji, narzędzia edukacyjne i eksplorację badawczą. Autorzy podkreślają, że takie grafy muszą być starannie weryfikowane i regularnie aktualizowane oraz nie są gotowe do bezpośredniego kierowania opieką bez nadzoru ekspertów. Mimo to ich wyniki sugerują, że dostrojone modele językowe w połączeniu z inteligentnym promptowaniem mogą uczynić zadanie organizowania wiedzy medycznej bardziej skalowalnym i terminowym.
Cytowanie: Zhou, C., Gong, Q., Luan, H. et al. Fine-tuned large language models with structured prompts enable efficient construction of lung cancer knowledge graphs. Sci Rep 16, 9505 (2026). https://doi.org/10.1038/s41598-026-38959-w
Słowa kluczowe: rak płuca, graf wiedzy, duży model językowy, ekstrakcja relacji, medyczne AI