Clear Sky Science · pl
Dwutorowy framework głębokiego uczenia do ciągowego rozpoznawania języka migowego w celu zwiększenia dostępności komunikacji w regionie Ha’il
Przełamywanie bariery komunikacyjnej
Dla wielu osób głuchych język migowy jest podstawowym sposobem komunikacji, tymczasem większość komputerów, telefonów i usług publicznych wciąż go nie rozumie. W artykule przedstawiono nowy system sztucznej inteligencji, który potrafi obserwować ciągłe miganie w nagraniu wideo i przekształcać je w zapisany tekst z większą dokładnością. Dzięki uwzględnieniu nie tylko ruchów rąk, ale też pozycji głowy i sygnałów twarzy, system ma na celu uczynienie komunikacji z użyciem technologii bardziej naturalną i dostępną — zwłaszcza dla społeczności głuchych w regionie Ha’il w Arabii Saudyjskiej, gdzie wsparcie cyfrowe wciąż jest ograniczone. 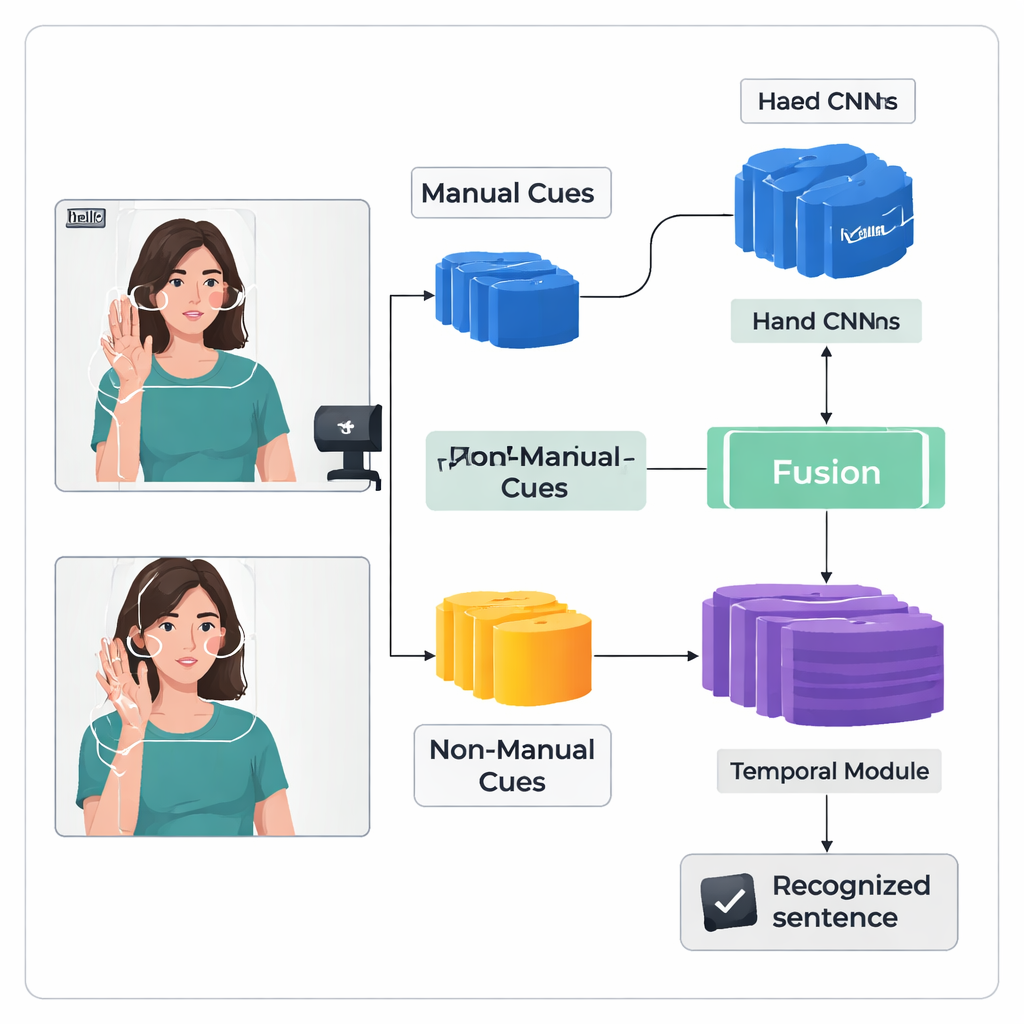
Dlaczego same ręce to za mało
Języki migowe są bogatymi, złożonymi systemami wykorzystującymi całe górne partie ciała. Znaczenie wynika nie tylko z tego, jak poruszają się ręce, ale także z wyrazu twarzy, kierunku spojrzenia oraz pochyleń czy skinień głową. Te sygnały pozaręczne mogą oznaczać pytania, przeczenie, nacisk lub emocje. Ludzie odczytują to intuicyjnie, ale większość systemów komputerowych rozpoznających język migowy skupia się prawie wyłącznie na rękach. To uproszczenie ułatwia trenowanie, lecz powoduje utratę istotnych wskazówek, zwłaszcza gdy znaki płyną razem w szybkie, ciągłe zdania, a nie jako izolowane słowa.
Dwa równoległe strumienie
Autorzy proponują „dwutorowy” framework głębokiego uczenia nazwany TS-CNN, który przetwarza ręce i głowę osobno, a następnie łączy te informacje. Jeden strumień koncentruje się na wykadrowanych obrazach rąk signera, ucząc się wzorców kształtu, ruchu i położenia. Drugi strumień otrzymuje skompresowaną mapę twarzy i głowy, wyprowadzoną z punktów orientacyjnych i estymacji pozycji głowy. Oba strumienie wykorzystują standardowy typ sieci wizji komputerowej do przekształcenia każdej klatki w cechy numeryczne. System następnie fuzjuje te cechy klatka po klatce, respektując fakt, że wskazówki z rąk i głowy występują równocześnie w naturalnym języku migowym. Późniejszy moduł temporalny analizuje wiele klatek, by zrozumieć, jak znaki rozwijają się w czasie, a warstwa rekurencyjna generuje sekwencję przewidywanych jednostek migowych, czyli tzw. glosów.
Wzmacnianie pamięci systemu dotyczącej znaków
Rozpoznawanie ciągłego języka migowego jest trudne, ponieważ dane treningowe są ograniczone, a znaki zlewają się bez wyraźnych etykiet w każdej klatce. Aby temu sprostać, autorzy dodają Moduł Wzmacniania Cech, który daje sieci dodatkowe wskazówki podczas treningu. Powszechnie stosowana technika wyrównuje przewidywaną sekwencję glosów z nagraniem wideo, wskazując prawdopodobne pozycje każdego glosu w czasie. Nowy moduł bierze te sugestie wyrównania i stosuje je jako bezpośredni nadzór, aby dopracować wewnętrzną reprezentację cech glosów. Upraszczając: system uczy się nie tylko wypisywać prawidłową sekwencję, lecz także budować wyraźniejsze, bardziej spójne wewnętrzne „wspomnienia” tego, jak każdy znak wygląda w różnych nagraniach.
Testy podejścia
Zespół ocenia TS-CNN na dwóch znanych zbiorach danych języka migowego: RWTH-PHOENIX-Weather 2014 dla niemieckiego języka migowego oraz CSL Split II dla chińskiego języka migowego. Wydajność mierzona jest współczynnikiem błędu słów (word error rate), standardową miarą podobną do stosowanej w rozpoznawaniu mowy. W porównaniu z bazą skupioną wyłącznie na ruchu rąk, dodanie informacji o pozie głowy zmniejsza błędy o około 4 punkty procentowe w danych niemieckich oraz o 3–4 punkty w danych chińskich. Dodanie modułu wzmacniania cech przynosi jeszcze większe korzyści, redukując błędy łącznie o około 10–14 procent na obu zbiorach. System działa też wydajnie, osiągając prędkości w czasie rzeczywistym na nowoczesnym procesorze graficznym, co jest kluczowe, jeśli ma być używany w interpretacji na żywo lub narzędziach mobilnych. 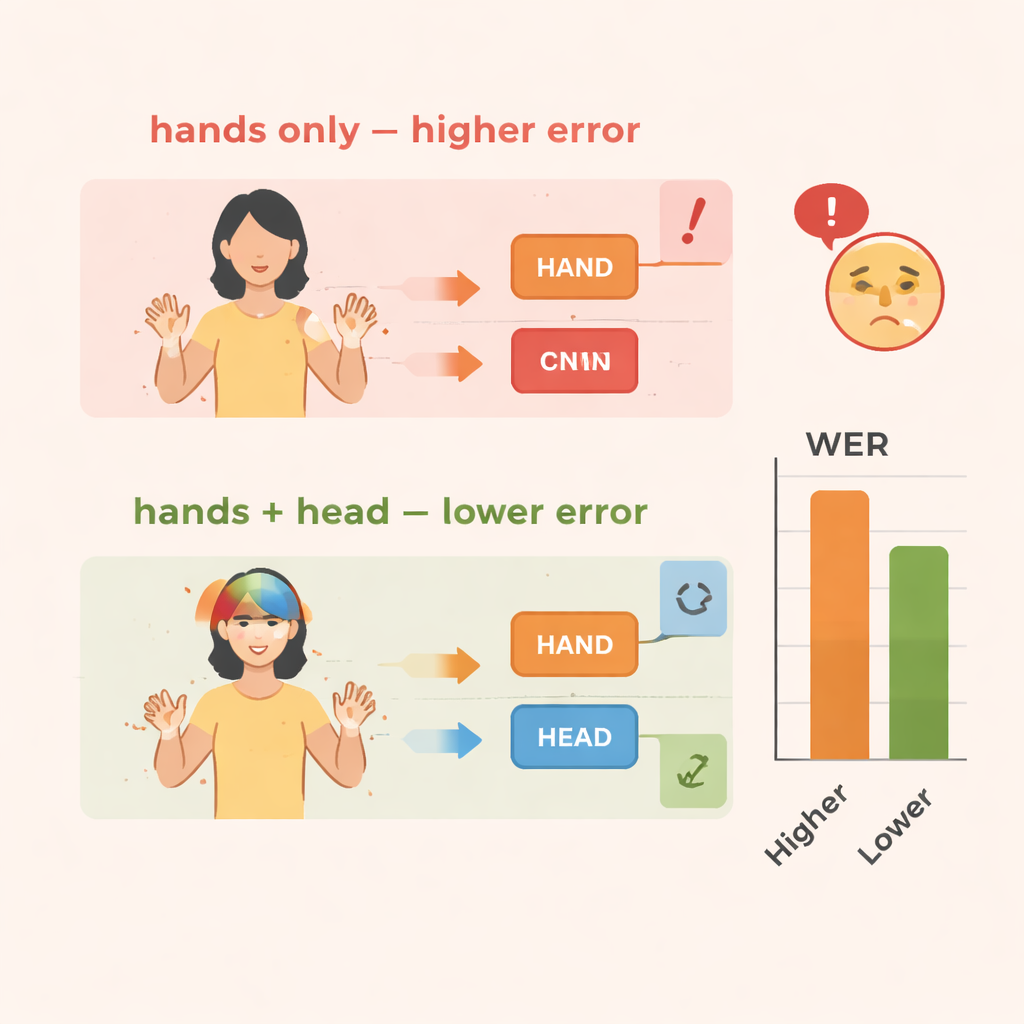
Co to oznacza w codziennym życiu
Mówiąc prościej, badania pokazują, że komputery mogą lepiej rozumieć język migowy, gdy obserwują całego sygnalizującego, a nie tylko ręce. Modelując ruchy głowy i mimikę obok ruchów rąk oraz starannie dopracowując sposób uczenia się na ograniczonych danych treningowych, framework TS-CNN zbliża się do praktycznych systemów, które mogłyby wspierać osoby głuche w szkołach, szpitalach i urzędach. W regionach takich jak Ha’il, gdzie tłumacze są nieliczni, a projekty technologiczne dopiero się rozwijają, taki system mógłby w przyszłości wspierać bardziej inkluzywną komunikację — pomagając zmniejszyć dystans między migającymi a słyszącym światem, nie zastępując przy tym bogatego, ludzkiego doświadczenia migania.
Cytowanie: Harrouch, H., Guesmi, H., Alalfy, H. et al. A dual-stream deep learning framework for continuous sign language recognition to enhance communication accessibility in the Ha’il region. Sci Rep 16, 7070 (2026). https://doi.org/10.1038/s41598-026-38912-x
Słowa kluczowe: rozpoznawanie języka migowego, głębokie uczenie, dostępność, widzenie komputerowe, interakcja człowiek–komputer