Clear Sky Science · pl
Metoda ochrony prywatności danych dla modeli predykcyjnych chorób zakaźnych z wyważoną szybkością treningu i dokładnością
Dlaczego ochrona danych zdrowotnych nadal ma znaczenie
Szpitale i agencje zdrowia coraz częściej polegają na sztucznej inteligencji, aby prognozować fale grypy, COVID-19 i innych zakażeń na dni lub tygodnie naprzód. Te przewidywania mogą kierować kampaniami szczepień, planowaniem obsady oraz przygotowaniami kryzysowymi. Jednak te same szczegółowe rekordy pacjentów, które zwiększają dokładność prognoz, są też niezwykle wrażliwe. Przepisy prawne i obawy społeczne często uniemożliwiają łączenie danych między instytucjami, co osłabia siłę takich modeli. Artykuł przedstawia sposób trenowania wysokiej jakości systemów do przewidywania chorób zakaźnych przy jednoczesnym zachowaniu danych każdego szpitala bezpiecznie na miejscu.
Uczenie się od wielu szpitali bez udostępniania kart pacjentów
Autorzy opierają się na technice zwanej uczeniem federacyjnym, w której kilka szpitali wspólnie trenuje wspólny model predykcyjny. Zamiast kopiować surowe rekordy pacjentów na serwer centralny, każde miejsce trenuje model lokalnie i wysyła jedynie numeryczne aktualizacje do wewnętrznych parametrów modelu. Serwer centralny łączy te aktualizacje i rozsyła ulepszony model z powrotem. Pętla ta powtarza się wiele razy. Teoretycznie uczenie federacyjne chroni prywatność, ponieważ dane osobowe nigdy nie opuszczają placówki. W praktyce jednak sprytni atakujący czasem potrafią wywnioskować szczegóły o danych wyjściowych z przesyłanych aktualizacji, dlatego potrzebne są dodatkowe zabezpieczenia. 
Zamykanie liczb za pomocą inteligentnego szyfrowania
Aby wzmocnić bezpieczeństwo, zespół wykorzystuje szyfrowanie homomorficzne — formę cyfrowej blokady, która pozwala na wykonywanie obliczeń bezpośrednio na zaszyfrowanych liczbach, bez odsłaniania ich w postaci jawnej. Tradycyjne schematy tego rodzaju są bardzo bezpieczne, ale niesłusznie powolne i wymagające dużych zasobów, co utrudnia ich zastosowanie w dużych, złożonych modelach, takich jak sieci typu Long Short-Term Memory (LSTM). Badacze zaprojektowali hybrydowy schemat, który traktuje różne części modelu w odmienny sposób. Najbardziej ujawniające komponenty chronione są silnym, lecz ciężkim szyfrowaniem, natomiast mniej wrażliwe części korzystają z lżejszej, szybszej blokady. Dodatkowo zaplanowany z wyprzedzeniem losowy harmonogram decyduje, w których rundach treningowych ośrodki faktycznie wysyłają zaszyfrowane aktualizacje, pozwalając ominąć zbędną komunikację. Testy pokazują, że takie połączenie przyspiesza trening o około 25 procent w porównaniu z użyciem ciężkiego szyfrowania wszędzie, przy jednoczesnym zachowaniu ochrony danych zgodnie z silnymi założeniami kryptograficznymi.
Wysyłanie tylko tych aktualizacji, które naprawdę mają znaczenie
Nawet przy mądrzejszym szyfrowaniu przesyłanie każdej drobnej zmiany modelu między instytucjami marnuje czas i przepustowość sieci. Dlatego autorzy proponują nowe reguły treningowe nazwane Data Selection–Distributed Selection Stochastic Gradient Descent (DS-DSSGD). Podczas treningu algorytm mierzy, jak bardzo każda część modelu zmienia się z jednego kroku na następny. Przesyłane są tylko aktualizacje, które przekraczają ustalony próg; małe, niskowyraziste zmiany są po prostu pomijane. Równocześnie algorytm śledzi, które rekordy danych odpowiadają za największe, najbardziej informatywne zmiany. Te wpływowe rekordy są gromadzone w przefiltrowanym zbiorze danych używanym w końcowej rundzie treningu. Eksperymenty na trzech latach rzeczywistych raportów zakażeń z miasta Yichang, połączonych z lokalnymi trendami wyszukiwania w sieci, pokazują, że DS-DSSGD skraca czas treningu o około 10 procent w porównaniu z kilkoma standardowymi metodami, bez istotnej utraty dokładności predykcyjnej.
Praktyczna platforma dla bezpiecznej współpracy
Postępy techniczne mają znaczenie tylko wtedy, gdy szpitale i laboratoria mogą je rzeczywiście wykorzystać. Aby zamknąć tę lukę, zespół zintegrował swoje metody w rzeczywistym środowisku obliczeniowym nazwanym Yi Shu Fang XDP Privacy Security Computing Platform. XDP zarządza całą ścieżką danych zdrowotnych — od zbierania i oczyszczania po zaszyfrowaną analizę i udostępnianie wyników. Obsługuje znane narzędzia używane przez statystyków, bioinformatyków i klinicystów, i pozwala badaczom z różnych instytucji współpracować w kontrolowanym miejscu pracy bez pobierania surowych danych. W ramach tej platformy hybrydowy schemat szyfrowania i algorytm DS-DSSGD działają jako wtyczkowe komponenty, przekształcając ramy teoretyczne w działający system. 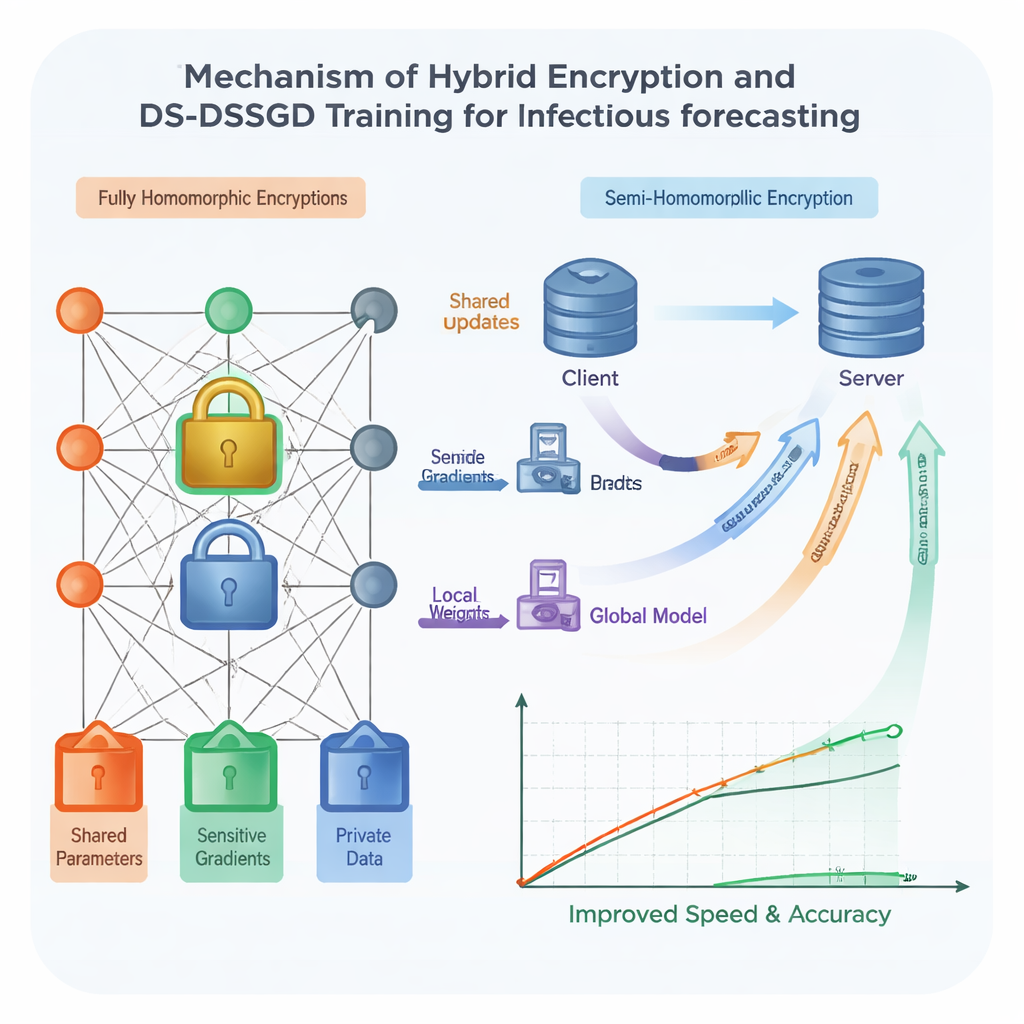
Co to oznacza dla przyszłych prognoz wybuchów epidemii
Mówiąc prosto, badanie pokazuje, że możliwe jest „mieć to podwójnie” przy prognozowaniu chorób zakaźnych: chronić prywatność pacjentów, a jednocześnie trenować szybkie i dokładne modele na danych pochodzących z wielu instytucji. Poprzez zaszyfrowanie różnych części modelu z odpowiednim poziomem siły, wysyłanie aktualizacji tylko wtedy, gdy jest to konieczne, i osadzenie wszystkiego w bezpiecznej platformie współpracy, autorzy obniżają koszt prywatności z paraliżującego ciężaru do zarządzalnego narzutu. Jeśli podejścia te zostaną szeroko przyjęte, mogłyby pozwolić szpitalom i agencjom zdrowia publicznego łączyć wiedzę przeciwko kolejnej epidemii bez ujawniania indywidualnych rekordów medycznych.
Cytowanie: Wang, X., Jiang, Y., Pan, G. et al. A data privacy protection method for infectious disease prediction models with balanced training speed and accuracy. Sci Rep 16, 7415 (2026). https://doi.org/10.1038/s41598-026-38906-9
Słowa kluczowe: prognozowanie chorób zakaźnych, prywatność danych zdrowotnych, uczenie federacyjne, szyfrowanie homomorficzne, uczenie głębokie