Clear Sky Science · pl
Szacowanie pospolitości i rozpowszechnienia gatunków metodami niesuperwizowanymi
Dlaczego liczenie pospolitych i rzadkich gatunków ma znaczenie
Gdy wyobrażamy sobie przyrodę zagrożoną, często myślimy o rzadkich zwierzętach na krawędzi wyginięcia. Tymczasem większość życia wokół nas tworzą bardzo zwyczajne organizmy, które są albo pospolite, albo cicho znikają, zanim ktoś to zauważy. Możliwość określenia, jak rozpowszechniony jest gatunek w danym miejscu, jest kluczowa do przewidywania, jak ekosystemy zareagują na zanieczyszczenia, zmiany użytkowania terenu czy klimat. W artykule przedstawiono sposób na jednoczesne oszacowanie, które gatunki są pospolite, a które rzadkie, używając jedynie istniejących zapisów obserwacji i współczesnych metod analizy danych. Celem jest dostarczenie obiektywnych danych wejściowych do modeli komputerowych przewidujących, gdzie gatunki mogą występować teraz i w przyszłości.
Od prostych obserwacji do dużych pytań ekologicznych
Ekolodzy rutynowo wykorzystują modele komputerowe, zwane modelami niszy ekologicznej, by ocenić, które środowiska są odpowiednie dla danego gatunku. Modele te pomagają prognozować, gdzie gatunek może się pojawić przy zmianie klimatu lub w nowych regionach. Kluczowym składnikiem jest „prewalencja” – w przybliżeniu udział badanych stanowisk, na których gatunek występuje. Wyraża ona, czy gatunek ma być oczekiwany jako pospolity czy rzadki przed przeprowadzeniem nowych badań. To wcześniejsze oczekiwanie silnie wpływa na to, jak modele zamieniają surowe oceny przydatności siedliska na prawdopodobieństwa występowania i jak wytyczają granice między „występuje” a „nie występuje” na mapie. Jeśli prewalencja jest źle oszacowana, zwłaszcza dla gatunków rzadkich, prognozy mogą być mylące, a działania ochronne skoncentrowane w niewłaściwych miejscach.
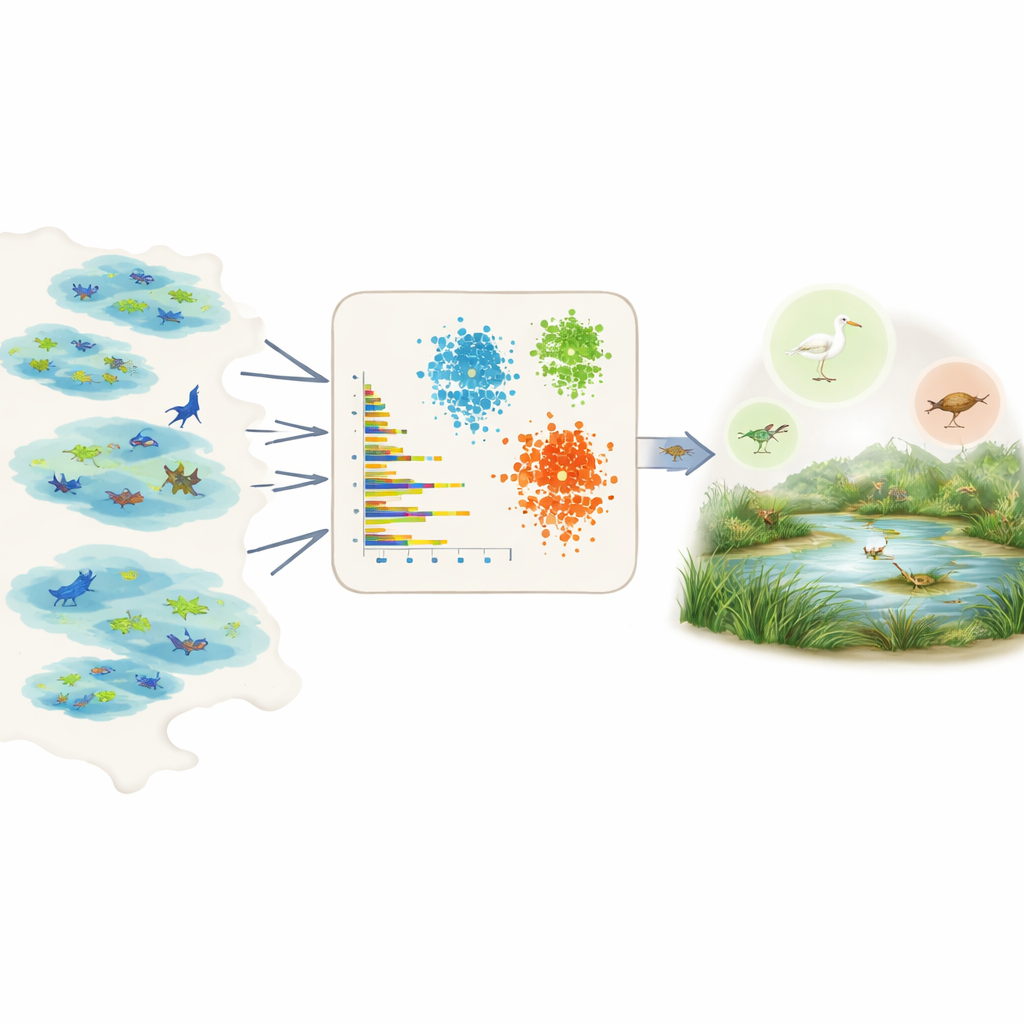
Puszczenie danych, aby przemówiły za setki gatunków
Bezpośrednie mierzenie prewalencji jest trudne, ponieważ dane terenowe są fragmentaryczne i obarczone uprzedzeniami. Niektóre obszary są intensywnie monitorowane, niektóre gatunki łatwiej zaobserwować, a wiele zapisów pochodzi z projektów citizen science o nierównym wysiłku. Zamiast polegać na opiniach ekspertów czy szczegółowej wiedzy dla każdego gatunku, autorzy wykorzystują Global Biodiversity Information Facility, ogromną otwartą bazę danych obserwacji gatunków. Dla każdego gatunku w wybranym regionie podsumowują surowe zapisy do kilku prostych, porównywalnych miar: ile osobników zwykle zgłasza się na jedno zgłoszenie, w ilu różnych zbiorach danych lub mokradłach występuje gatunek, jak jest rozpowszechniony w obrębie tych mokradeł oraz jak często jest obserwowany w czasie, w tym jak często pojawiają się nagłe „wybuchy” wielu obserwacji.
Nauczanie maszyn rozróżniania gatunków pospolitych i rzadkich
Z tymi cechami podsumowującymi zespół stosuje trzy narzędzia uczenia niesuperwizowanego – dwie metody grupowania i model głębokiego uczenia znany jako wariacyjny autoenkoder – które wyszukują wzorców bez wstępnej informacji, które gatunki są pospolite, a które rzadkie. Metody grupowania łączą gatunki mające podobną obfitość, zasięg i częstotliwość obserwacji. Autoenkoder uczy się, jak wygląda „typowy” zapis gatunku i oznacza nietypowe wzorce jako anomalie, które często odpowiadają gatunkom rzadkim lub słabo obserwowanym. Modele przypisują następnie każdy gatunek do trzech intuicyjnych klas – bardzo pospolity, dość pospolity lub rzadki – i zamieniają te klasy na wartości numeryczne prewalencji, które można bezpośrednio wykorzystać w modelach niszy ekologicznej jako wcześniejsze prawdopodobieństwa.
Testowanie podejścia na wrażliwym mokradle
Aby sprawdzić, jak dobrze ta metoda działa w praktyce, autorzy skoncentrowali się na dorzeczu jeziora Massaciuccoli w Toskanii we Włoszech, nisko położonym mokradle bogatym w ptaki, ryby, owady i inne zwierzęta. Ten krajobraz jest zarówno hotspotem bioróżnorodności, jak i atrakcyjnym miejscem turystycznym, ale jest też podatny na zmiany klimatu, niedobory wody i zanieczyszczenia. Dla 161 gatunków zwierząt związanych z jeziorem modele trenowano na zapisach z innych włoskich mokradeł, a następnie proszono o wnioskowanie, jak pospolity powinien być każdy gatunek w Massaciuccoli. Dwóch lokalnych ekspertów z dużym doświadczeniem terenowym niezależnie oceniło te same gatunki. W porównaniu autorzy stwierdzili, że model głębokiego uczenia zgadzał się ze skonsolidowaną oceną ekspertów dla około 81–90 procent gatunków, podczas gdy metody grupowania i zespół wszystkich trzech modeli również dobrze się sprawdziły.
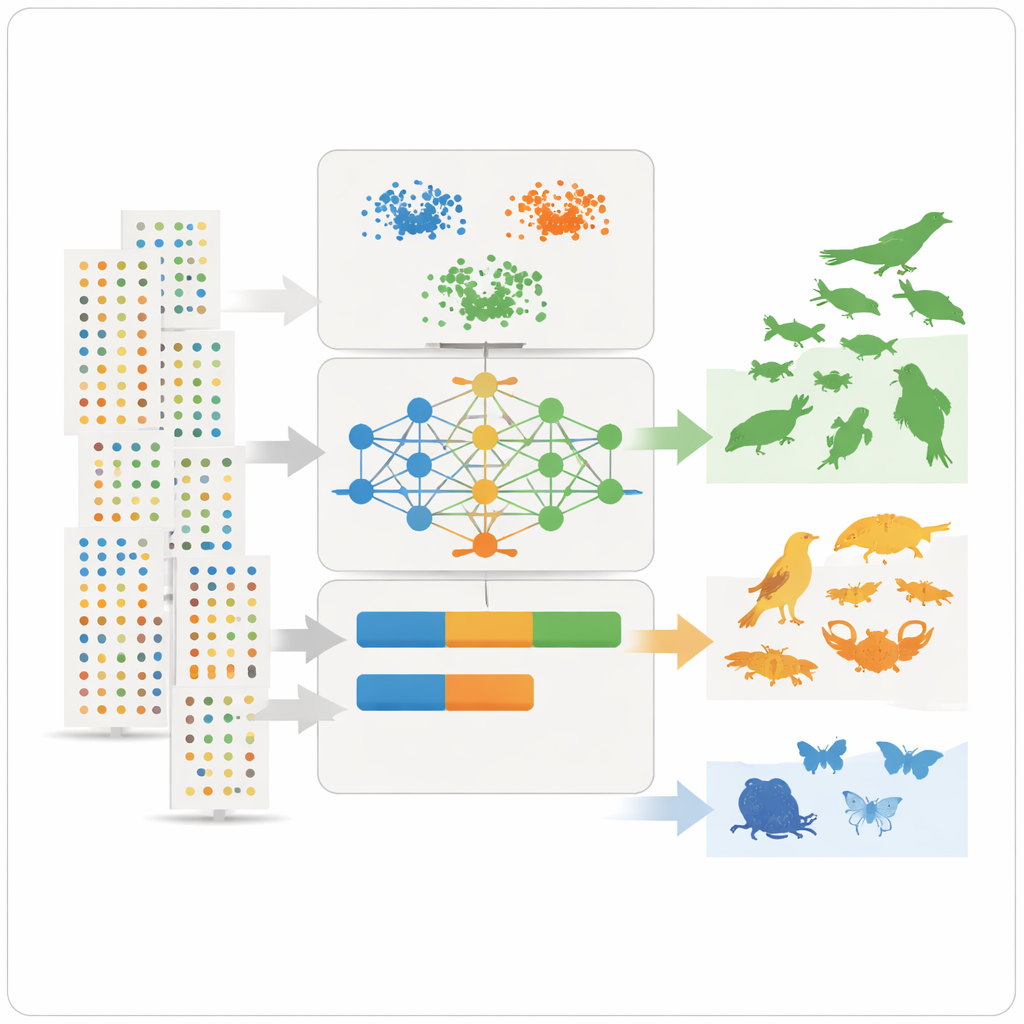
Nauka z niezgodności i ukrytych uprzedzeń
Nie wszystkie przypadki pokrywały się idealnie. Kilka gatunków dobrze znanych ekspertom jako liczne wokół jeziora wydawało się rzadkich w danych, często dlatego, że są płochliwe, niedorejestrowane lub bardziej obserwowane w niektórych mokradłach niż w innych. To uwypukliło kluczowe ograniczenie: duże bazy danych odzwierciedlają miejsca i sposoby poszukiwań przyrody, a nie tylko rzeczywiste występowanie gatunków. Analiza wrażliwości pokazała, które cechy były najważniejsze dla klasyfikacji: średnia liczba zapisów na zbiór danych, obfitość na obserwację oraz spójność obserwacji w latach okazały się szczególnie informacyjne. Pomimo utrzymujących się uprzedzeń metoda wygenerowała jasne, powtarzalne szacunki prewalencji i można ją dostroić, używając drobniejszych lub grubszych klas w zależności od potrzeb modelowania.
Co to oznacza dla przyszłych prognoz przyrody
Dla osób niebędących specjalistami główne przesłanie jest takie, że możemy teraz wykorzystać istniejące dane o bioróżnorodności w sposób bardziej inteligentny, aby ocenić, które gatunki prawdopodobnie będą pospolite, umiarkowane lub rzadkie w danym otoczeniu, bez ręcznego dostrajania każdej sytuacji. Przekształcając hałaśliwe zapisy obserwacji w przejrzyste, oparte na danych oszacowania prewalencji, ramy te pomagają modelom ekologicznym formułować bardziej realistyczne prognozy przydatności siedlisk i przyszłych trendów bioróżnorodności. To z kolei może wspierać lepsze planowanie dla mokradeł takich jak Massaciuccoli i wielu innych ekosystemów na całym świecie, nawet gdy dane terenowe są niekompletne, a czas ekspertów ograniczony.
Cytowanie: Bove, P., Bertini, A. & Coro, G. Estimating species commonness and prevalence through unsupervised methods. Sci Rep 16, 8331 (2026). https://doi.org/10.1038/s41598-026-38900-1
Słowa kluczowe: rozpowszechnienie gatunków, modelowanie bioróżnorodności, ekosystemy wodno-błotne, uczenie maszynowe w ekologii, pospolitość gatunków