Clear Sky Science · pl
Klasyfikacja tekstów piosenek oparta na sekwencyjnie kaskadowanych hybrydowych adaptacyjnych głębokich sieciach z wykorzystaniem podejścia optymalizacyjnego
Dlaczego inteligentniejsze filtry piosenek mają znaczenie
Muzyka napływa do naszego życia niemal bez przerwy, a wiele z tego, co słyszymy, wybierają algorytmy. Wciąż jednak wiele z tych systemów ma problem z prostym pytaniem: co dokładnie mówią słowa w piosence i dla kogo są one odpowiednie? Artykuł rozwiązuje ten problem, budując zaawansowany model sztucznej inteligencji (AI), który automatycznie odczytuje teksty piosenek i sortuje je według nastroju, gatunku, sentymentu, a nawet typu wykonawcy. Celem jest pomoc w tworzeniu bezpieczniejszych playlist dla dzieci, dokładniejszych rekomendacji opartych na nastroju oraz lepszych narzędzi dla badaczy muzyki.
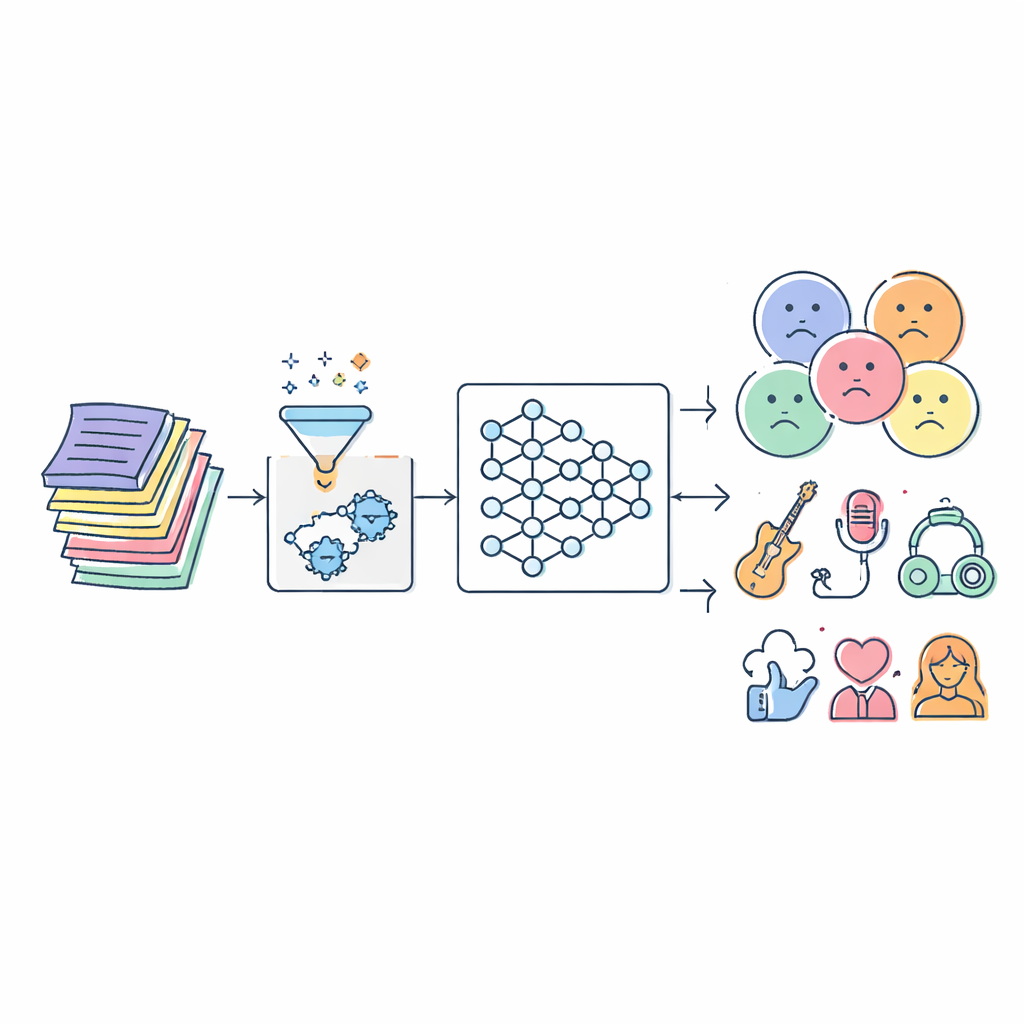
Wyzwanie ukryte w słowach piosenek
Teksty są znacznie bardziej skomplikowane niż lista słów dobrych lub złych. Ta sama fraza może brzmieć czuło w jednym utworze, a groźnie w innym, a słuchacze wnoszą do odbioru własne doświadczenia. Tradycyjne filtry zwykle opierają się na statycznych listach obraźliwych słów lub prostych technikach statystycznych. Takie podejścia tracą kontekst, nie nadążają za ewoluującym slangiem i często błędnie etykietują utwory. Równocześnie eksplozja muzyki cyfrowej oznacza miliony utworów do analizy, w wielu językach i stylach, co przytłacza ręczne oznaczanie i starsze algorytmy.
Oczyszczanie surowych tekstów
Autorzy zaczynają od zgromadzenia dużych zbiorów tekstów z trzech publicznych datasetów, które łącznie obejmują setki tysięcy piosenek z różnych gatunków i języków. Zanim jakiekolwiek AI zacznie się uczyć na tekście, trzeba go oczyścić. System usuwa interpunkcję, znaki specjalne oraz powtarzające się lub nieistotne fragmenty, a następnie sprowadza pokrewne formy słów do wspólnego rdzenia (na przykład „śpiewając”, „śpiewa” i „zaśpiewał” wszystkie stają się „śpiew”). Ten etap wstępnego przetwarzania usuwa szum przy zachowaniu sensu, dzięki czemu kolejne etapy mogą skupić się na tonie emocjonalnym i temacie, zamiast na niuansach formatowania czy wariantach ortograficznych.
Wielowarstwowe AI, które czyta jak uważny słuchacz
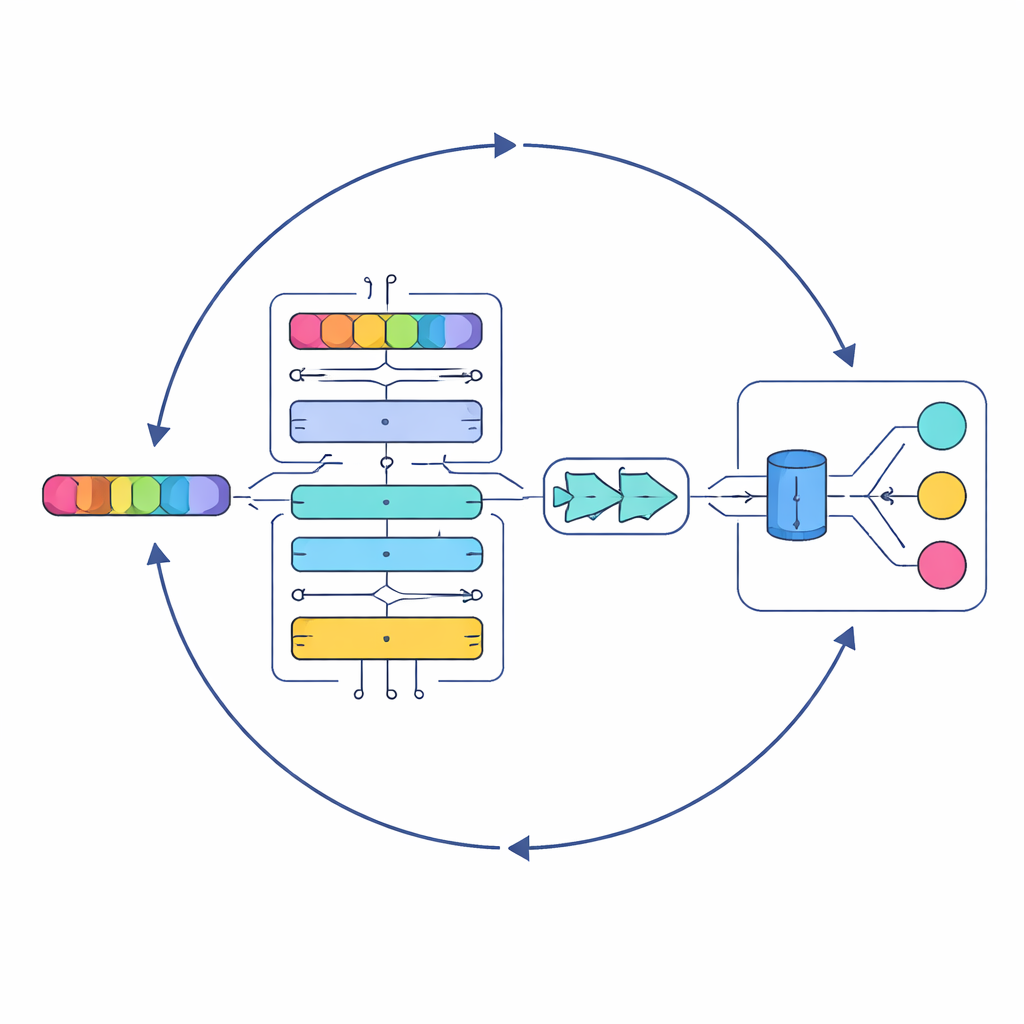
W centrum badania znajduje się nowy model nazwany Serial Cascaded Hybrid Adaptive Deep Network, w skrócie SCHADNet. Łączy on trzy potężne idee współczesnego przetwarzania języka. Po pierwsze, enkoder oparty na transformerze uchwyca, jak słowa odnoszą się do siebie w całym tekście, nie tylko w sąsiedztwie. Po drugie, dwukierunkowa warstwa Long Short-Term Memory czyta tekst zarówno w przód, jak i w tył, co pomaga zrozumieć, jak wcześniejsze wersy wpływają na znaczenie późniejszych. Po trzecie, warstwa Gated Recurrent Unit dopracowuje te informacje do kompaktowego podsumowania, dobrze nadającego się do podejmowania ostatecznych decyzji. Razem te komponenty działają jak chór wyspecjalizowanych czytelników, z których każdy skupia się na innym aspekcie tekstu piosenki.
Zap借anie strategii od morza
Samodzielne układanie kolejnych warstw uczenia głębokiego nie wystarcza; ich parametry wewnętrzne — takie jak liczba neuronów czy czas treningu — silnie wpływają na wydajność. Zamiast ręcznego strojeniu tych wyborów, autorzy sięgają po podejście optymalizacyjne inspirowane wzorcami polowań morskich drapieżników. Ich Ulepszony Algorytm Drapieżników Morskich (Improved Marine Predators Algorithm, IMPA) eksploruje wiele możliwych kombinacji parametrów, stopniowo zbliżając się do tych, które dają najlepsze wyniki. Przycinając części oryginalnego algorytmu, które nie pomagały w tym zastosowaniu, poprawiają zbieżność, co oznacza, że system szybciej i bardziej niezawodnie osiąga dobre rozwiązania.
Jak dobrze działa system
Naukowcy testują SCHADNet z IMPA na trzech różnych zbiorach tekstów i porównują go z szeregiem ugruntowanych metod, w tym klasycznymi klasyfikatorami uczenia maszynowego oraz kilkoma popularnymi modelami uczenia głębokiego, takimi jak zwykłe LSTM, systemy oparte wyłącznie na transformerach oraz sieci hybrydowe. W zakresie dokładności, czułości (ile rzeczywiście istotnych utworów zostało znalezionych) oraz innych miar jakości, nowe podejście konsekwentnie wypada najlepiej. W jednym dużym wielojęzycznym zbiorze poprawnie klasyfikuje około 93% utworów i uzyskuje wyjątkowo wysoką wartość predykcyjną negatywną, co oznacza, że dobrze rozpoznaje teksty, które nie należą do oznaczonej kategorii — kluczowe dla unikania nadgorliwego blokowania czy błędnego etykietowania.
Co to oznacza dla słuchaczy i twórców
Dla laika przesłanie jest proste: autorzy stworzyli bardziej subtelnego, bardziej niezawodnego czytelnika tekstów piosenek. Zamiast polegać na prymitywnych listach słów, ich system analizuje całe frazy, kontekst i wzorce w dużych zbiorach muzyki, a następnie automatycznie przypisuje etykiety takie jak nastrój, styl czy przydatność dla młodszej publiczności. Choć model jest złożony i wymagający obliczeniowo, otwiera drogę do inteligentniejszych kontroli rodzicielskich, bogatszych playlist opartych na nastroju i nowych sposobów badania trendów w muzyce popularnej. Przyszłe prace mają na celu zmniejszenie zapotrzebowania na dane i przyspieszenie treningu, ale nawet w obecnej formie SCHADNet wskazuje na przyszłość, w której platformy muzyczne rozumieją teksty niemal tak uważnie jak skoncentrowany ludzki słuchacz.
Cytowanie: Jasmine, R.L., Mukherjee, S., Robin, C.R.R. et al. Serial cascaded hybrid adaptive deep networks-based lyrics text classification using optimization approach. Sci Rep 16, 8527 (2026). https://doi.org/10.1038/s41598-026-38813-z
Słowa kluczowe: rekomendacje muzyczne, analiza tekstów piosenek, klasyfikacja tekstu, uczenie głębokie, moderacja treści