Clear Sky Science · pl
Udoskonalenie wykrywania oszustw abonamentowych za pomocą uczenia zespołowego: przypadek Ethio Telecom
Dlaczego oszustwa telefoniczne dotyczą nas wszystkich
Za każdym razem, gdy dzwonimy, wysyłamy SMS lub korzystamy z danych mobilnych, ufamy, że rachunek odzwierciedla rzeczywiste użycie. Tymczasem przestępcy mogą wykorzystywać sieci telefoniczne, zakładając linie na fałszywe tożsamości, generując ogromne niezapłacone rachunki, a nawet używając tych linii do innych przestępstw. Badanie koncentruje się na Ethio Telecom, narodowym operatorze Etiopii, i pokazuje, jak zaawansowane, oparte na danych metody potrafią wykrywać podejrzane subskrypcje znacznie skuteczniej niż tradycyjne narzędzia, pomagając utrzymać usługi telefoniczne w przystępnej cenie i bezpieczne dla milionów użytkowników.
Ukryte koszty fałszywych kont telefonicznych
Oszustwa abonamentowe mają miejsce, gdy ktoś rejestruje usługę telefoniczną z fałszywymi lub skradzionymi danymi i nie zamierza płacić. Na całym świecie jest to jedna z najbardziej dotkliwych form oszustw telekomunikacyjnych, kosztująca branżę dziesiątki miliardów dolarów rocznie. W przypadku samego Ethio Telecom szacuje się, że oszustwa drenowały około miliarda dolarów rocznie, przy czym fałszywe subskrypcje odpowiadają za około 40% tych strat. Poza utraconymi przychodami linie te mogą być wykorzystywane do oszustw, odsprzedaży międzynarodowych połączeń lub innych nielegalnych działań, stwarzając ryzyko zarówno dla klientów, jak i dla bezpieczeństwa narodowego.
Od ręcznie tworzonych reguł do uczenia się z danych
Podobnie jak wielu operatorów, Ethio Telecom tradycyjnie polegał na ekspertach tworzących stałe reguły do sygnalizowania podejrzanych zachowań — na przykład blokowaniu linii po zbyt wielu połączeniach międzynarodowych w krótkim czasie. Systemy oparte na regułach są łatwe do zrozumienia, ale mają trudności, gdy oszuści zmieniają taktykę lub gdy wzorce użycia są złożone. Autorzy argumentują, że uczenie maszynowe, które uczy się wzorców bezpośrednio z danych historycznych, może reagować szybciej i bardziej czułe. Zamiast polegać na jednym modelu, badacze eksplorują metody „zespołowe”, łączące kilka modeli, oraz metody „adaptacyjne”, które na bieżąco aktualizują się w miarę napływu nowych danych.
Co zbudowali badacze na podstawie rzeczywistych rejestrów połączeń
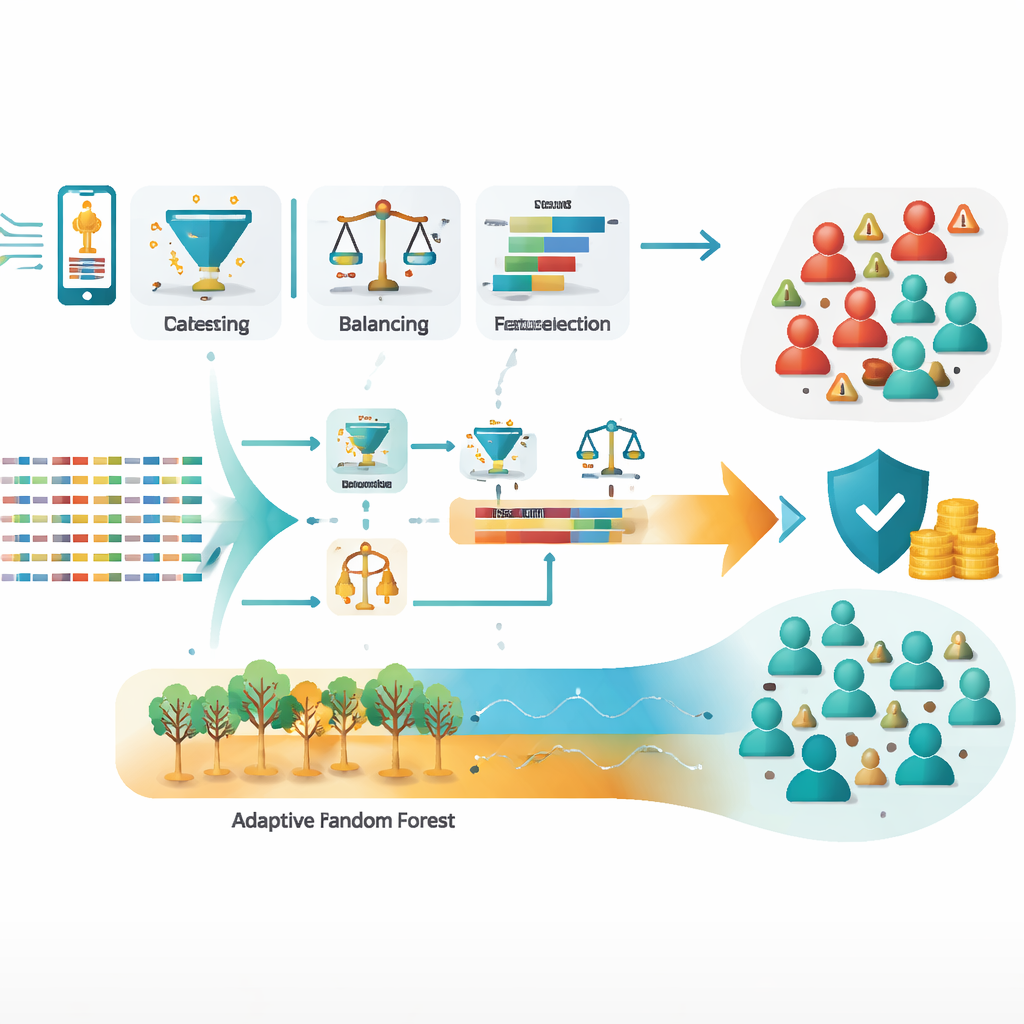
Zespół pracował na dużym zbiorze rejestrów szczegółów połączeń — logów kto, komu dzwonił, jak długo i w jakich warunkach — z dwumiesięcznego okresu znanego z intensywnej aktywności oszustów. Z około miliona surowych rekordów dane zostały oczyszczone, usunięto błędy i duplikaty, wyrównano silnie zróżnicowane klasy (znacznie więcej uczciwych użytkowników niż oszustów) oraz skonstruowano nowe cechy lepiej odzwierciedlające podejrzane zachowania. Szczególnie istotne były miary takie jak liczba wybieranych numerów międzynarodowych przez abonenta, udział połączeń międzynarodowych w całości połączeń oraz stosunek unikalnych numerów do liczby wszystkich połączeń. Te skoncentrowane sygnały często lepiej odróżniają normalne użycie od zorganizowanego nadużycia niż proste sumy czy dane demograficzne.
Jak łączenie modeli zwiększa wykrywalność
Badacze przetestowali trzy standardowe modele — drzewa decyzyjne, regresję logistyczną i sztuczne sieci neuronowe — wraz z kilkoma strategiami zespołowymi takimi jak bagging (Random Forest), boosting (XGBoost), głosowanie i stacking, oraz modelami adaptacyjnymi zaprojektowanymi dla ciągów danych (Hoeffding Tree i Adaptive Random Forest). Po starannym dostrojeniu parametrów, podejście stackingowe, które uczy się, jak łączyć mocne strony wielu modeli bazowych, osiągnęło około 99,3% dokładności na niewidocznych danych. Adaptacyjny Las Losowy był niemal tak samo silny, z około 99,2% dokładności, a dodatkowo potrafił dostosowywać się, gdy wzorce oszustw się zmieniają. Oba podejścia znacząco zmniejszyły najgroźniejszy błąd — nie wykrycie rzeczywistego oszustwa — w porównaniu z pojedynczymi modelami.
Nadążanie za zmieniającymi się trikami w czasie rzeczywistym
Ponieważ oszuści nieustannie zmieniają metody działania, statyczny model szybko może stać się przestarzały. Aby temu sprostać, autorzy zastosowali technikę selekcji cech online, która nieustannie ponownie ocenia, które sygnały są najważniejsze, bez konieczności przebudowy całego systemu. Podkreślają też znaczenie prywatności: wszystkie identyfikatory osobowe w danych zostały zanonimizowane przed analizą, i zalecają ścisłą kontrolę dostępu oraz ścieżki audytu. Dla praktycznego wdrożenia badanie szkicuje architekturę czasu rzeczywistego, w której nowe rejestry połączeń są przesyłane strumieniowo przez narzędzia takie jak Apache Kafka do modeli adaptacyjnych, które aktualizują się „w locie” i jednocześnie monitorują nagłe zmiany zachowań.
Co to oznacza dla użytkowników i dostawców
Mówiąc wprost, badanie pokazuje, że pozwalanie kilku inteligentnym modelom „głosować” razem oraz umożliwienie im ciągłego uczenia się może wykrywać fałszywe subskrypcje z niezwykłą dokładnością, jednocześnie utrzymując liczbę fałszywych alarmów na akceptowalnym poziomie. Dla Ethio Telecom może to oznaczać znaczne oszczędności, bardziej stabilne ceny i silniejszą ochronę przed przestępczym wykorzystaniem sieci. Dla klientów oznacza to mniejsze ryzyko, że nietypowe, lecz prawowite użycie zostanie błędnie zinterpretowane jako oszustwo, przy jednoczesnym szybszym wykrywaniu i zamykaniu rzeczywiście ryzykownych linii. Autorzy konkludują, że uczenie zespołowe i adaptacyjne, oparte na starannie dobranych, specyficznych dla kontekstu wskaźnikach, stanowią potężny i skalowalny wzorzec dla nowoczesnego wykrywania oszustw telekomunikacyjnych.
Cytowanie: Desta, E.A., Azale, K.W., Hailu, A.A. et al. Enhancing subscription fraud detection through ensemble learning the case of Ethio telecom. Sci Rep 16, 7867 (2026). https://doi.org/10.1038/s41598-026-38790-3
Słowa kluczowe: oszustwa telekomunikacyjne, oszustwa abonamentowe, uczenie zespołowe, adaptacyjny las losowy, rejestry szczegółów połączeń