Clear Sky Science · pl
Dokładne i interpretowalne prognozowanie chemicznego zapotrzebowania na tlen za pomocą wyjaśnialnych algorytmów wzmacniających z analizą SHAP
Dlaczego warto obserwować tlen w rzece
Rzeki są życiodajnym elementem miast i gospodarstw rolnych, ale gdy zapełniają się materią organiczną z fabryk, kanalizacji czy pól, woda może zostać pozbawiona tlenu i stać się niebezpieczna dla ludzi oraz ekosystemów. Powszechnym badaniem stanu rzek jest „chemiczne zapotrzebowanie na tlen” (COD), które mierzy, ile tlenu potrzeba do rozkładu zanieczyszczeń. Pomiary COD w laboratorium są czasochłonne i kosztowne, dlatego w tym badaniu sprawdzono, czy zaawansowane, a jednocześnie wyjaśnialne narzędzia uczenia maszynowego mogą wiarygodnie przewidywać COD na podstawie rutynowych danych z czujników — oraz jasno wskazywać, co napędza zanieczyszczenie. 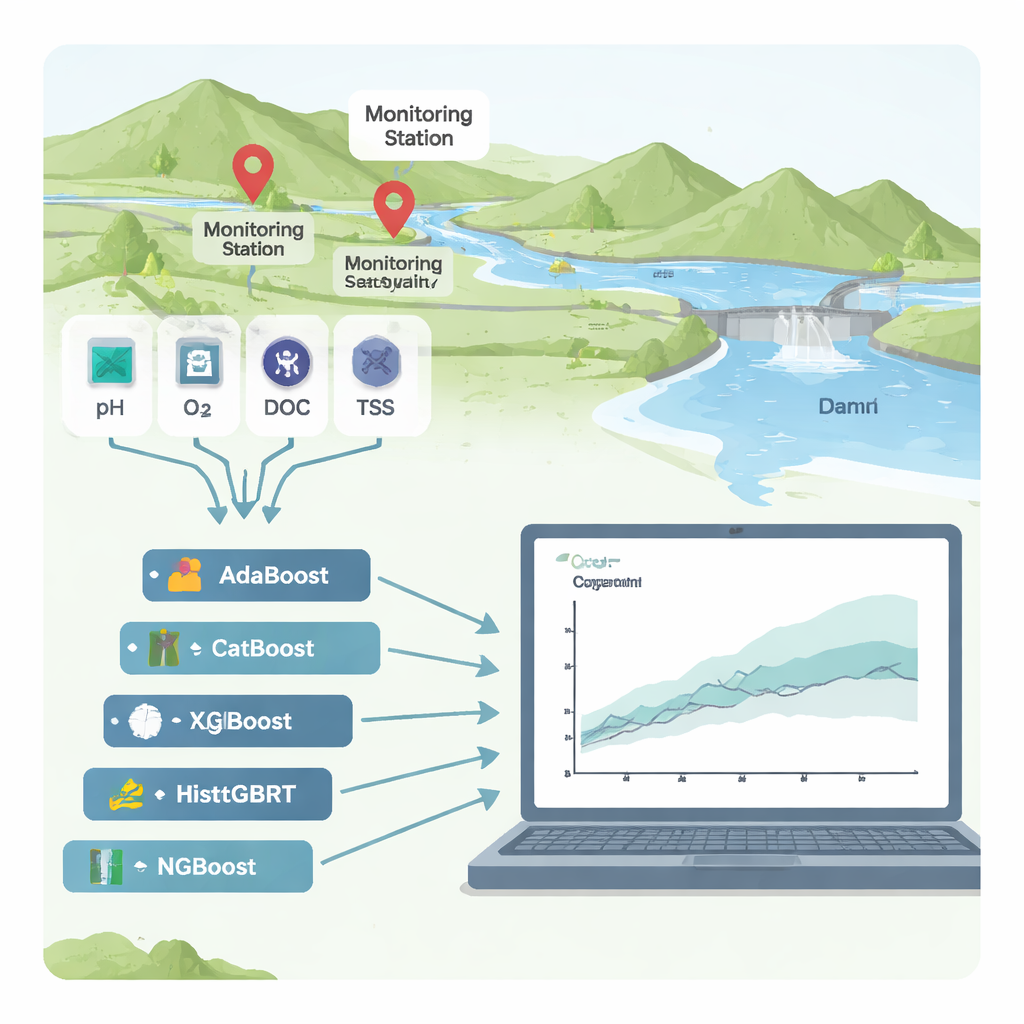
Inteligentne modele dla zanieczyszczonego świata
Badacze skupili się na dwóch stacjach monitoringu rzek w Korei Południowej, Hwangji i Toilchun, tuż powyżej wielofunkcyjnej zapory Yeongju. Na tych stacjach istnieją dziesięciolecia zapisów dla standardowych wskaźników jakości wody: kwasowość (pH), tlen rozpuszczony, zawieszone cząstki (SS), substancje odżywcze takie jak azot i fosfor, całkowity węgiel organiczny (TOC), biochemiczne zapotrzebowanie na tlen (BOD₅), temperatura wody, przewodność elektryczna oraz przepływ rzeki. Zamiast budować tradycyjny model oparty na fizyce — który bywa trudny do przeniesienia między rzekami — przetestowali sześć algorytmów „boostingowych”, potężnej rodziny metod uczenia maszynowego łączących wiele prostych drzew decyzyjnych w silny predyktor.
Poszukiwanie najlepszego „prognozera” rzeki
Aby porównać sześć metod boostingowych (AdaBoost, CatBoost, XGBoost, LightGBM, HistGBRT i NGBoost), zespół trenował modele na około 70% danych historycznych i oceniał ich działanie na pozostałych 30%. Dokładność oceniano przy użyciu kilku statystyk, które odzwierciedlają, jak bliskie są prognozy rzeczywistym pomiarom COD oraz jak dobrze modele uogólniają się na nieznane warunki. Na stacji Toilchun model NGBoost — który przewiduje nie tylko pojedynczą wartość, lecz pełne rozkłady prawdopodobieństwa dla COD — okazał się wyraźnym zwycięzcą, odtwarzając niemal całą zmienność COD przy bardzo małych błędach. W Hwangji, będącym bardziej złożonym miejscem, najlepszą równowagę dokładności i stabilności zapewnił CatBoost. Niektóre modele, zwłaszcza XGBoost, wyglądały niemal idealnie na danych treningowych, lecz zawodziły na danych testowych — klasyczny objaw przeuczenia (overfitting), gdy model zapamiętuje szum zamiast uczyć się prawdziwych wzorców.
Otwarcie czarnej skrzynki AI
Głównym celem badania nie było tylko przewidywanie COD, lecz także wyjaśnienie, dlaczego modele formułowały swoje prognozy. Do tego autorzy użyli SHAP (Shapley Additive Explanations), techniki przypisującej każdemu wejściowemu zmiennemu wkład — dodatni lub ujemny — do poszczególnych prognoz. W obu rzekach i dla większości algorytmów trzy zmienne konsekwentnie wyróżniały się jako główni sprawcy COD: całkowity węgiel organiczny (TOC), biochemiczne zapotrzebowanie na tlen (BOD₅) oraz zawieszone cząstki (SS). Mówiąc prościej: im więcej materii organicznej i drobnych cząstek w wodzie, tym większe zapotrzebowanie na tlen. Modele ujawniły też różnice lokalne: w Toilchun większą rolę odgrywał przepływ (discharge) i całkowity fosfor, co sugeruje silniejszy wpływ rozproszonych źródeł, takich jak spływ rolniczy; w Hwangji wzorce przewodności i zawieszonych cząstek wskazywały na bardziej lokalne lub przemysłowe źródła zanieczyszczeń. 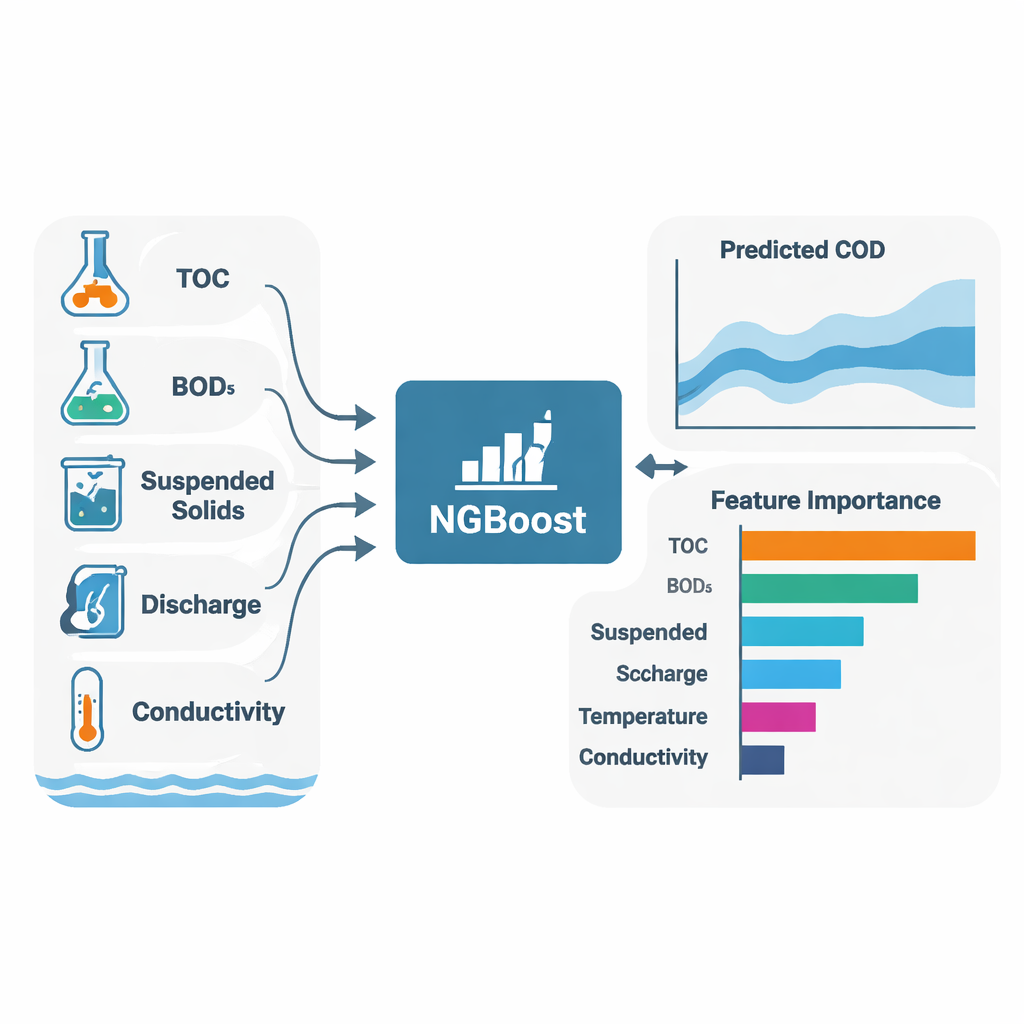
Co wyniki oznaczają dla rzeczywistych rzek
Te obserwacje pokazują, że modele boostingowe, połączone z SHAP, mogą wyjść poza bycie nieprzejrzystymi „czarnymi skrzynkami”. Dostarczają one jednocześnie precyzyjnych prognoz zapotrzebowania na tlen w rzece oraz fizycznie sensownego wyjaśnienia, co napędza zanieczyszczenie w danym miejscu. Ma to znaczenie dla zarządzających zaporami i dorzeczami, którzy muszą priorytetyzować, co monitorować i gdzie interweniować: jeśli TOC i BOD₅ są najsilniejszymi dźwigniami, to kontrola dopływu odpadów organicznych może przynieść największą poprawę jakości wody. Prognozy probabilistyczne z NGBoost dostarczają też informacji o niepewności, co jest istotne dla systemów wczesnego ostrzegania i decyzji opartych na ocenie ryzyka. Krótko mówiąc, badanie demonstruje, że starannie zaprojektowana, wyjaśnialna sztuczna inteligencja może pomóc chronić zbiorniki wody pitnej i życie wodne, przekształcając rutynowe odczyty z czujników w wiarygodne, przejrzyste prognozy stanu rzeki.
Cytowanie: Merabet, K., Kim, S., Heddam, S. et al. Accurate and interpretable prediction of chemical oxygen demand using explainable boosting algorithms with SHAP analysis. Sci Rep 16, 6359 (2026). https://doi.org/10.1038/s41598-026-38757-4
Słowa kluczowe: jakość wody, chemiczne zapotrzebowanie na tlen, uczenie maszynowe, zanieczyszczenie rzek, wyjaśnialna sztuczna inteligencja