Clear Sky Science · pl
Ocena wydajności dużych modeli językowych na irańskich egzaminach z reumatologii w języku perskim: trafność i rozumowanie kliniczne GPT-4o kontra GPT-5.1
Dlaczego to ważne dla lekarzy i pacjentów
Sztuczna inteligencja szybko wkracza do sal wykładowych i gabinetów lekarskich, ale większość testów tych narzędzi koncentruje się na języku angielskim. To badanie stawia pytanie istotne dla milionów osób mówiących po persku: jak dobrze zaawansowane chatboty AI, w szczególności GPT‑4o i GPT‑5.1, radzą sobie z trudnymi pytaniami egzaminacyjnymi z reumatologii napisanymi w języku perskim? Odpowiedź pomaga edukatorom, rezydentom i pacjentom zrozumieć, gdzie te narzędzia mogą bezpiecznie wspierać naukę, a gdzie wciąż niezbędna jest ludzka ekspertyza.
Wystawienie AI na próbę
Naukowcy zgromadzili 204 pytania wielokrotnego wyboru z oficjalnych irańskich egzaminów z reumatologii z lat 2023 i 2024 — tych samych egzaminów, które specjaliści muszą zdać, by uzyskać certyfikat. Po usunięciu siedmiu wadliwych pytań wykorzystano 197 pozycji. Każde pytanie, wraz z ewentualnymi obrazami lub wykresami, wprowadzono po persku do GPT‑4o i GPT‑5.1 w odrębnych, świeżych czatach. Modele proszono o wybór najlepszego rozwiązania i wyjaśnienie rozumowania, naśladując sposób, w jaki rezydent mógłby pytać narzędzie AI podczas nauki.
Sprawdzanie zarówno odpowiedzi, jak i rozumowania
Wydajność oceniano dwuetapowo. Najpierw wybrane przez modele odpowiedzi porównano z oficjalnym kluczem odpowiedzi, co dało proste kryterium poprawności. Następnie sześciu reumatologów z dyplomem oceniło jakość każdego wyjaśnienia w pięciopunktowej skali — od jednoznacznie błędnego rozumowania do kompletnego i klinicznie poprawnego. Odpowiedzi każdego modelu oceniali dwaj różni reumatolodzy, którzy nie znali ocen kolegów ani oficjalnego klucza. Dzięki temu badacze mogli sprawdzić nie tylko, czy AI "strzeliło" poprawnie, ale też, czy jego logika przypomina sposób myślenia specjalistów.
Jak poradził sobie nowszy model
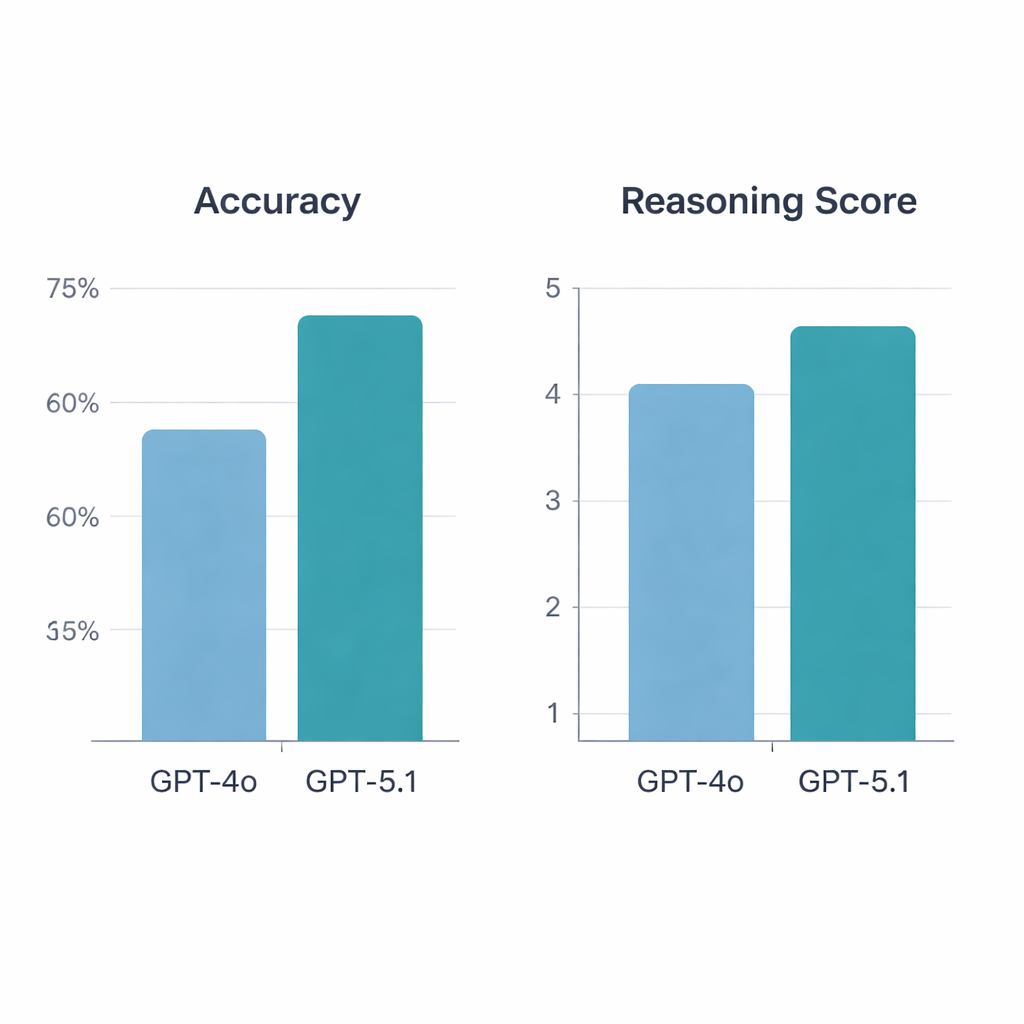
GPT‑5.1 wyraźnie przewyższył GPT‑4o. Na 197 poprawnych pytań GPT‑4o odpowiedział poprawnie w 64,5% przypadków, podczas gdy GPT‑5.1 osiągnął 76% — co stanowi statystycznie istotny wzrost. Oba modele miały po 113 poprawnych i po 34 błędne odpowiedzi, ale GPT‑5.1 samodzielnie rozwiązał dodatkowe 36 pytań, których GPT‑4o nie potrafił; GPT‑4o było wyjątkowo poprawne tylko w 13 przypadkach. Gdy reumatolodzy oceniali wyjaśnienia, ponownie lepszy wynik uzyskał GPT‑5.1, ze średnią oceną rozumowania 4,47 na 5 wobec 4,13 dla GPT‑4o, a także uzyskał więcej najwyższych ocen. W przeciwieństwie do GPT‑4o, którego jakość rozumowania zależała od rodzaju pytania (np. nauki podstawowe, opis przypadku, rozpoznanie czy leczenie), GPT‑5.1 utrzymywał bardziej równomierne wyniki we wszystkich kategoriach.
Mocne strony, luki i niezgody między ludźmi
Badanie ujawniło istotne niuanse. Nawet gdy model udzielił błędnej odpowiedzi, specjaliści czasem oceniali jego rozumowanie jako w miarę spójne, co podkreśla rozbieżność między punktowaniem egzaminów a realnym myśleniem klinicznym. Jednocześnie zgodność ocen między reumatologami była tylko umiarkowana, co pokazuje, że sami klinicyści różnią się w ocenie, co stanowi „dobre rozumowanie”. Wygląda też, że język ma znaczenie: wcześniejsze prace w języku angielskim i hiszpańskim raportowały wyższe wyniki dla podobnych modeli, co sugeruje, że AI nadal radzi sobie lepiej z największymi światowymi językami niż z perskim. Autorzy podkreślają, że te chatboty potrafią generować przekonujące wyjaśnienia, które mogą kryć błędy faktograficzne, oraz że ich wydajność może się zmieniać wraz z aktualizacjami systemów.
Co to oznacza na przyszłość
Dla czytelników niebędących specjalistami przesłanie jest takie: najnowsza generacja chatbotów AI coraz lepiej radzi sobie z egzaminami specjalistycznymi w języku perskim, ale nie zastąpi rygorystycznego szkolenia ani oceny ekspertów. GPT‑5.1 może być przydatnym partnerem do nauki dla rezydentów reumatologii — podsumowując tematy, prowadząc przez przypadki i oferując uporządkowane wyjaśnienia — lecz nie powinien być traktowany jako ostateczny autorytet przy decyzjach o wysokich stawkach dotyczących rozpoznania czy leczenia. Autorzy apelują o większe, wielojęzyczne badania, powtarzane testy w czasie oraz realistyczne symulacje kliniczne, aby ustalić, jak te narzędzia można bezpiecznie włączyć do edukacji medycznej i w końcu do codziennej opieki nad pacjentem.
Cytowanie: Rafiei, F., Sadeghipour, S., Sheikhalishahi, S. et al. Evaluation of large Language model performance on Persian rheumatology board exams: accuracy and clinical reasoning of GPT-4o vs. GPT-5.1. Sci Rep 16, 7274 (2026). https://doi.org/10.1038/s41598-026-38716-z
Słowa kluczowe: reumatologia, irańska edukacja medyczna w języku perskim, duże modele językowe, rozumowanie kliniczne, egzaminy specjalizacyjne