Clear Sky Science · pl
Wstępne trenowanie na ImageNet i dwuetapowe uczenie transferowe w klasyfikacji obrazów chromosomów
Wyraźniejsze spojrzenie na nasze chromosomy
Nasze chromosomy zawierają instrukcje budowy i funkcjonowania organizmu, a lekarze badają ich kształty, by wykrywać zaburzenia genetyczne i niektóre nowotwory. Dziś komputery mogą wspomagać odczyt obrazów chromosomów, ale nauczenie ich tego zadania jest trudne, ponieważ obrazy medyczne są rzadkie i znacząco różnią się od typowych fotografii. W tym badaniu postawiono proste pytanie o duże praktyczne znaczenie: czy komputery uczą się lepiej na powiązanych obrazach medycznych, a nie tylko na ogromnych zbiorach zdjęć kotów, psów i samochodów?
Dlaczego zdjęcia chromosomów mają znaczenie
W szpitalach specjaliści układają 46 chromosomów danej osoby w wykres zwany kariotypem, pogrupowanym na 24 typy (22 pary numerowane oraz chromosomy X i Y). Subtelne jasne i ciemne prążki wzdłuż chromosomów pomagają ujawnić brakujące lub dodatkowe fragmenty związane z takimi schorzeniami jak zespół Downa czy niektóre białaczki. Tradycyjnie eksperci klasyfikują te prążki wzrokowo, co jest powolne i subiektywne. Głębokie uczenie oferuje sposób na automatyzację tej pracy, ale systemy te zwykle startują od modeli wytrenowanych na ImageNet — ogromnym zestawie zdjęć codziennych scen. Skok z wakacyjnych kadrów do mikroskopowych widoków chromosomów jest ogromny i nie jest pewne, na ile takie doświadczenie rzeczywiście się przenosi.
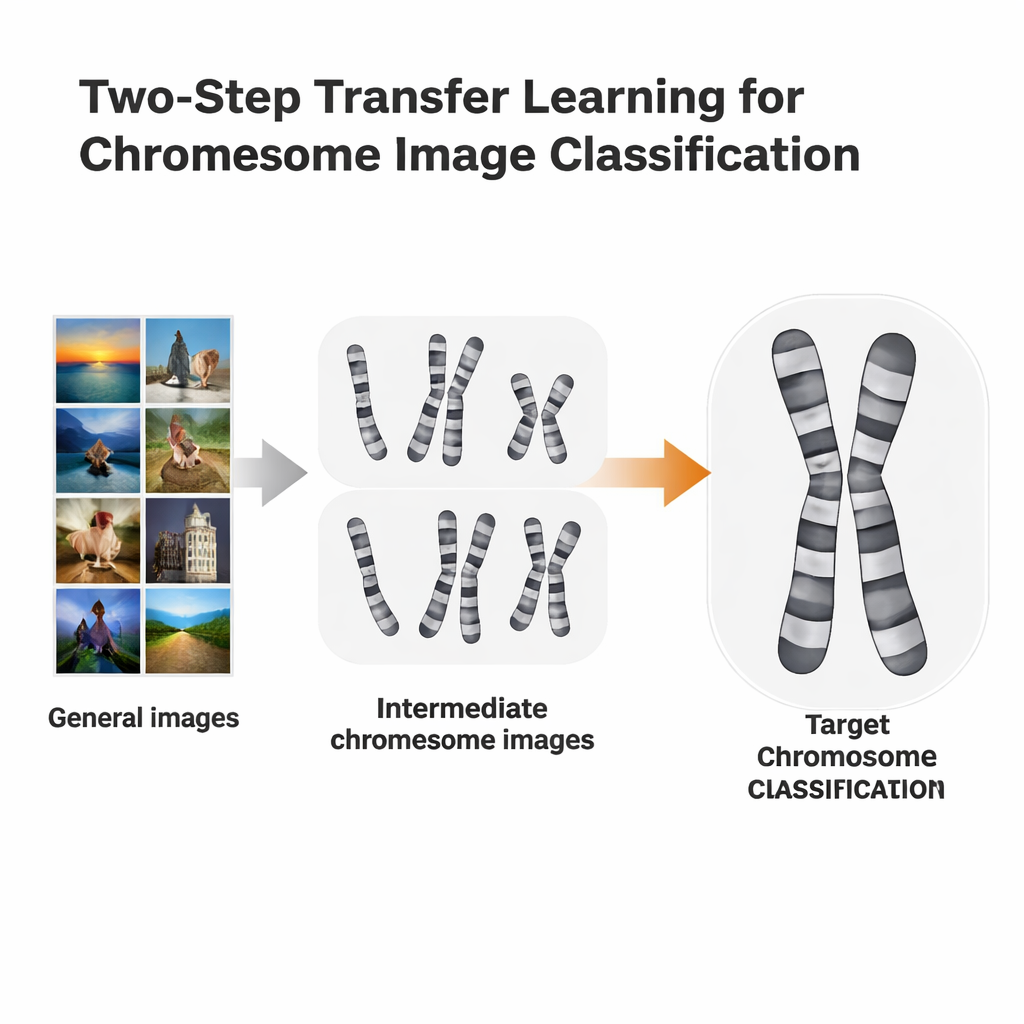
Dwuetapowe skrócenie drogi uczenia
Badacze przetestowali bardziej dopasowaną ścieżkę trenowania, nazwaną dwuetapowym uczeniem transferowym. Zamiast przechodzić bezpośrednio z ImageNet do konkretnego zadania z chromosomami, najpierw dostrajali modele wytrenowane na ImageNet na obrazach chromosomów z jednej metody barwienia, a potem ponownie dostrajali je na obrazach z drugiej, nieco innej metody. Wykorzystali dwa otwarte zbiory: obrazy Q-band, które są niższej jakości i trudniejsze do odczytania, oraz obrazy G-band, które są czyściejsze i bardziej szczegółowe. Każdy zbiór na przemian pełnił rolę „kroku pośredniego” dla drugiego. Pomysł przypomina naukę języków: jeśli znasz hiszpański, łatwiej będzie ci nauczyć się włoskiego niż przechodzić prosto z angielskiego.
Testowanie wielu „oczu” komputerowych
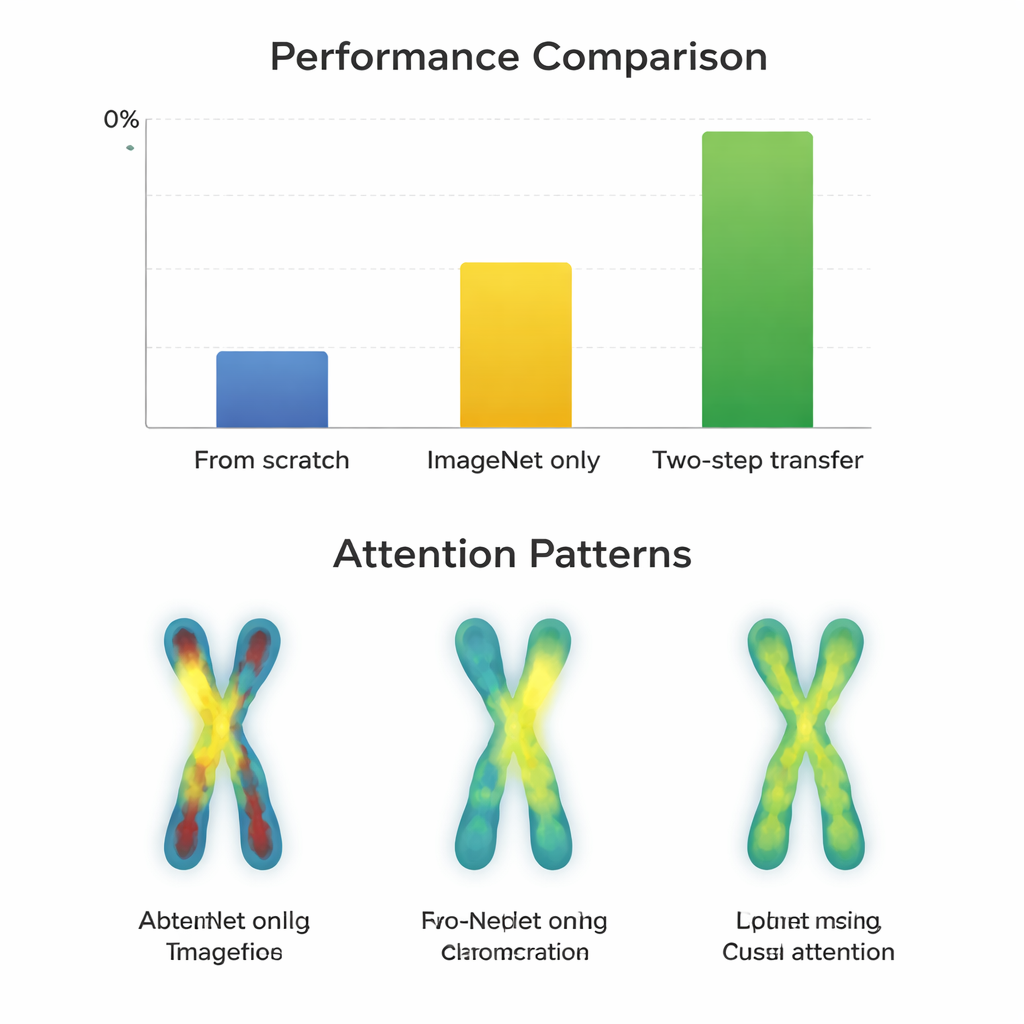
Aby sprawdzić, kiedy dodatkowy krok pomaga, zespół wytrenował 66 różnych klasyfikatorów, łącząc 11 popularnych architektur sieci neuronowych z trzema strategiami: trenowaniem od zera, dostrajaniem tylko z ImageNet oraz dwuetapowym transferem. Wyniki oceniano za pomocą Macro-F1 — miary traktującej wszystkie typy chromosomów równo, w tym te rzadkie. Najpierw potwierdzono, że obrazy Q-band i G-band są statystycznie bardziej podobne do siebie niż którykolwiek z nich do zdjęć z ImageNet, co czyni je obiecującymi krokami pośrednimi. Następnie porównano, jak różne modele uczą się pod każdą strategią na obu zbiorach — łatwiejszym (G-band) i trudniejszym (Q-band).
Kiedy dodatkowy krok się opłaca
W przypadku wyższej jakości obrazów G-band prawie wszystkie modele osiągały bardzo dobre wyniki już po prostym dostrajaniu z ImageNet, z wynikami rzędu 97–98 procent. Tutaj dwuetapowe trenowanie dawało jedynie niewielkie korzyści — często poniżej punktu procentowego — a czasem nawet pogarszało wyniki starszych architektur. W przeciwieństwie do tego, na trudniejszych obrazach Q-band sytuacja się zmieniła. Nowoczesne, zwarte architektury, takie jak ConvNeXt, Swin Transformer, Vision Transformer i MobileNetV3 wyraźnie skorzystały z drogi dwuetapowej, poprawiając wyniki o około 0,8 do 3,3 punktu procentowego w porównaniu z samym ImageNet. Wizualizacje miejsc, na które modele „patrzyły”, wyjaśniały dlaczego: przy dwuetapowym transferze sieci koncentrowały się bardziej równomiernie wzdłuż prążków obu ramion chromosomu, zamiast skupiać się jedynie na konturach lub jednym obszarze. Jednak bardzo duże, starsze sieci, takie jak VGG, nie zyskały, a czasem miały gorsze wyniki, co sugeruje, że sprytny projekt architektury przewyższa samą wielkość.
Ograniczenia narzucone przez same dane
Badacze przeanalizowali też błędy na obrazach G-band. Część porażek nie wynikała ze strategii uczenia, lecz ze złej jakości wejścia, na przykład chromosomów przyciętych niepoprawnie podczas rozdzielania nakładających się kształtów. W takich przypadkach wszystkie metody treningowe miały trudności, a mapy uwagi były rozproszone lub skupiały się na mylących krawędziach. To podkreśla praktyczny wniosek dla klinik i programistów: nawet najlepszy pipeline treningowy nie pokona całkowicie złej jakości obrazu czy błędów w przetwarzaniu wstępnym, szczególnie przy umiarkowanych rozmiarach zestawów danych, takich jak te dostępne dla obrazowania chromosomów.
Co to oznacza dla diagnostyki w praktyce
Dla osób spoza specjalizacji kluczowy wniosek jest taki, że inteligentne ponowne wykorzystanie powiązanych obrazów medycznych może poprawić dokładność automatycznego odczytu chromosomów — zwłaszcza gdy docelowe dane są zaszumione lub skąpe oraz gdy stosuje się nowoczesne, starannie zaprojektowane sieci neuronowe. Dla obrazów wysokiej jakości standardowe trenowanie z ImageNet może być wystarczające. Jednak gdy patolodzy pracują z trudniejszymi zbiorami, dodatkowy krok uczenia z użyciem blisko spokrewnionego typu obrazu może wyostrzyć „oko” komputera, podnosząc wydajność do zakresu 93–98 procent. Podejście to może wykraczać poza chromosomy i być przydatne w wielu dziedzinach obrazowania medycznego, gdzie etykietowanych danych brakuje, pomagając przybliżyć niezawodne narzędzia AI do codziennej praktyki klinicznej.
Cytowanie: Chen, T., Xie, C., Zhang, W. et al. ImageNet pre-training and two-step transfer learning in chromosome image classification. Sci Rep 16, 7572 (2026). https://doi.org/10.1038/s41598-026-38662-w
Słowa kluczowe: klasyfikacja chromosomów, Sztuczna inteligencja w obrazowaniu medycznym, uczenie transferowe, modele głębokiego uczenia, kariotypowanie