Clear Sky Science · pl
Poprawa predykcji nośności końcowej pali zakotwionych w skale za pomocą zoptymalizowanych modeli XGBoost wspomaganych szumem Gaussowskim
Budowanie na skale zamiast na domysłach
Gdy inżynierowie projektują mosty i wieżowce, często polegają na głębokich fundamentach sięgających w twardą skałę. Nośność tych „pali zakotwionych w skale” jest kluczowa dla bezpieczeństwa i kosztów, lecz rzeczywista zdolność przenoszenia obciążeń w strefie końcowej jest trudna do bezpośredniego zmierzenia. Badanie pokazuje, jak nowoczesne narzędzia uczenia maszynowego, połączone ze sprytnymi technikami generowania danych, mogą dostarczyć inżynierom znacznie precyzyjniejszych szacunków, ile obciążenia takie fundamenty mogą bezpiecznie przenieść — co potencjalnie pozwala oszczędzać na budowie przy zachowaniu bezpieczeństwa konstrukcji.
Dlaczego trudniej ocenić głębokie fundamenty
Pale zakotwione w skale to duże betonowe kolumny wiercone przez słabsze grunty i osadzone w twardszej skale. W teorii im twardsza skała i lepsze wykonanie, tym większe obciążenie może przenieść koniec pala. W praktyce sytuacja jest nieporządna: na dnie otworu może gromadzić się muł lub zawiesina, chropowatość i kształt gniazda są zmienne, a ukryte pustki czy spękania w skale trudno wykryć. Z powodu tych niepewności projektanci często przyjmują ostrożne założenia o znikomej lub zerowej nośności końcowej, co prowadzi do dłuższych i droższych fundamentów, niż być może jest to konieczne.
Od prostych wzorów do mądrzejszych prognoz
Dotychczasowe metody szacowania nośności pali opierały się na uproszczonych równaniach lub tradycyjnych modelach numerycznych. Zazwyczaj skupiały się na kilku parametrach — na przykład wytrzymałości na ściskanie skały — i traktowały masę skalną w sposób idealizowany. W ostatnich latach badacze zaczęli stosować techniki sztucznej inteligencji uczące się bezpośrednio na bazach testów obciążeniowych, w których pala były testowane do momentu, gdy ich zachowanie było dobrze poznane. Te podejścia potrafią jednocześnie uwzględniać wiele wejść, w tym średnicę pala, głębokości w gruntach i skale oraz miary jakości skały, ale są też „czarnymi skrzynkami”, które przy ograniczonej ilości danych mogą nadmiernie dopasowywać się do próbek.
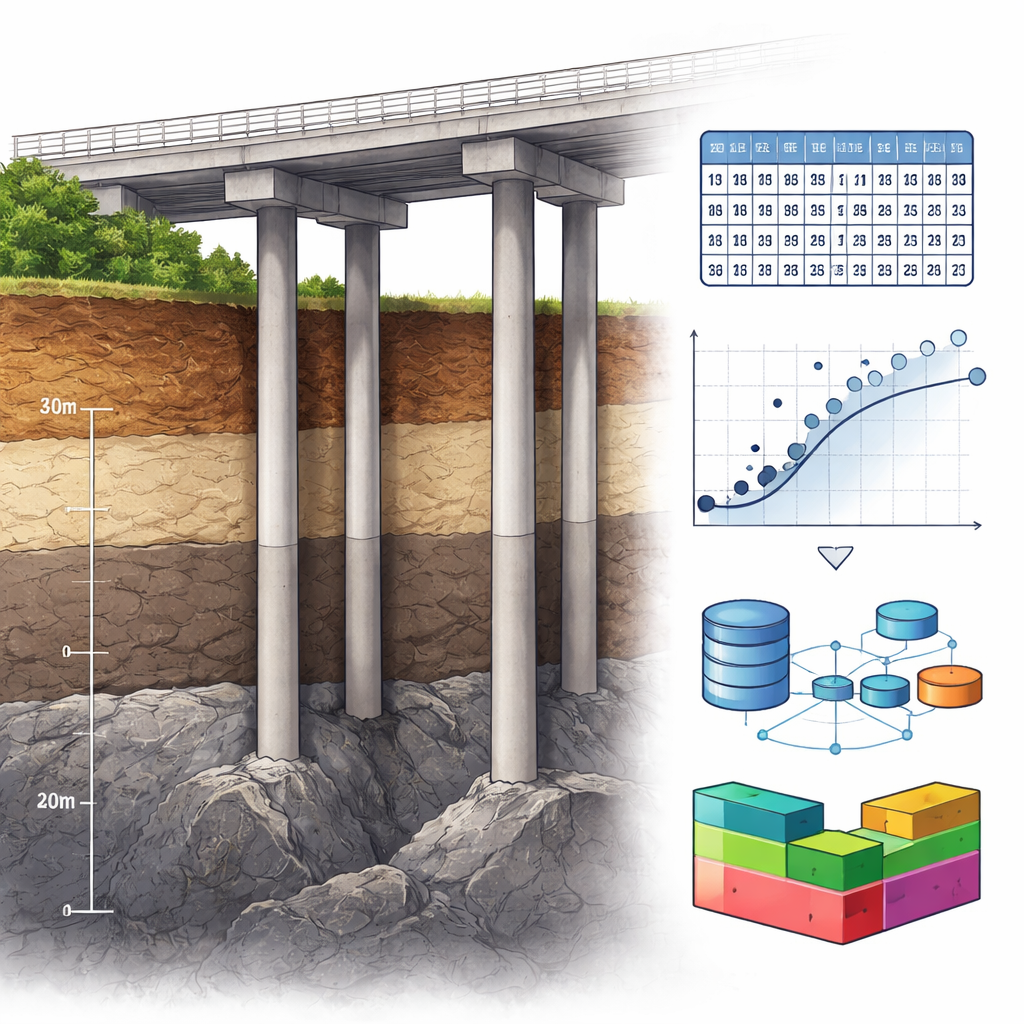
Karmienie algorytmu danymi rzeczywistymi i syntetycznymi
Autorzy opracowali analizę na bazie opublikowanego zbioru 151 testów pali zakotwionych w skale, w którym zanotowano współczynnik nośności końcowej (miara, ile obciążenia może przenieść koniec) wraz z ośmioma cechami opisowymi. Po starannym oczyszczeniu danych w celu usunięcia odchyleń i braków pozostawiono 136 rzeczywistych pali. Aby przezwyciężyć małą liczbę przypadków — powszechny problem w geotechnice — wygenerowano dodatkowe dane „syntetyczne” przez dodanie łagodnego, losowego szumu Gaussowskiego do istniejących rekordów. W ten sposób powstał większy, statystycznie spójny zbiór 460 pali, który zachował pierwotne wzorce, jednocześnie oferując większą różnorodność do treningu modeli uczenia maszynowego.
Trenowanie i strojenie modeli
Zespół skupił się na algorytmie Extreme Gradient Boosting, znanym jako XGBoost, który łączy wiele prostych drzew decyzyjnych w silny predyktor. Aby uzyskać najlepszą wydajność XGBoost, połączono go z trzema optymalizatorami inspirowanymi naturą, opartymi na regułach arytmetycznych, zachowaniach grupowych (brainstorming) i strategiach polowań wielorybów. Te optymalizatory automatycznie stroiły kluczowe parametry — takie jak głębokość drzew i współczynnik uczenia — aby znaleźć równowagę między dopasowaniem do znanych danych a uniknięciem nadmiernego dopasowania. Spośród wariantów model XGBoost strojony algorytmem Arytmetycznej Optymalizacji (XGBoost_AOA) okazał się najbardziej dokładny i stabilny.
Czego modele nauczyły się o skale i palach
Używając tylko oryginalnych 136 pali, model zoptymalizowany już przewyższał wcześniejsze metody. Po treningu na rozszerzonym zbiorze 460 pali jego dokładność dramatycznie wzrosła: błędy prognoz zmniejszyły się do ułamka wcześniejszych wartości, a dopasowanie przewidywanych i zaobserwowanych nośności zbliżyło się do idealnej linii jeden do jednego. Analiza ujawniła też, które dane wejściowe miały największe znaczenie. Dominującymi predyktorami okazały się wytrzymałość skały na ściskanie oraz ocena masy skalnej, podczas gdy średnica pala i ogólny poziom obciążenia również odgrywały istotne role. Miary blisko ze sobą powiązane, takie jak dwie różne oceny jakości skały, okazały się wysoce redundantne, co podkreśla, że nakładające się informacje mogą sprzyjać nadmiernemu dopasowaniu, jeśli nie są odpowiednio uwzględnione.
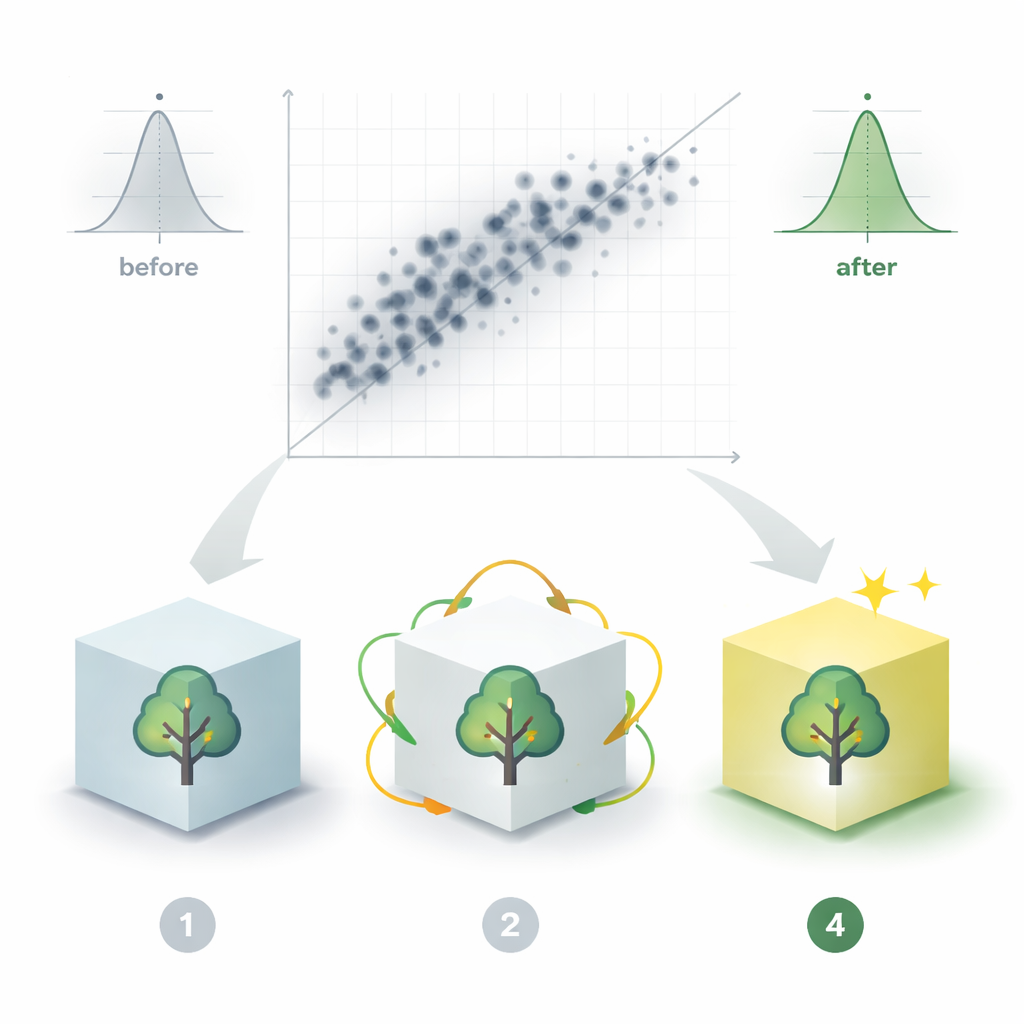
Od kodu badawczego do narzędzia praktycznego
Aby udostępnić wyniki poza laboratorium, autorzy zapakowali swój najlepiej działający model w łatwy w użyciu interfejs komputerowy. Inżynierowie mogą wprowadzić podstawowe parametry pala i skały i natychmiast otrzymać szacunek nośności końcowej, wraz z dowodami, że model był sprawdzany na niezależnych przypadkach. Choć podejście nadal zależy od jakości i zakresu danych wyjściowych, pokazuje, jak połączenie uczenia maszynowego, generowania danych syntetycznych i narzędzi interpretowalności może przekształcić rozproszone wyniki testów w praktyczną pomoc projektową — pomagając ograniczyć domysły, zmniejszyć nadmierną konserwatywność i projektować bezpieczniejsze, bardziej ekonomiczne fundamenty.
Cytowanie: Khatti, J., Fissha, Y. & Cheepurupalli, N. Improving end-bearing capacity prediction of rock-socketed shafts using Gaussian-augmented optimized extreme gradient boosting models. Sci Rep 16, 7664 (2026). https://doi.org/10.1038/s41598-026-38646-w
Słowa kluczowe: pale zakotwione w skale, głębokie fundamenty, uczenie maszynowe, augmentacja danych, inżynieria geotechniczna