Clear Sky Science · pl
FedSCOPE: Federacyjne sekwencyjne rekomendacje międzydomenowe z rozdzielonym uczeniem kontrastowym i ochroną prywatności przez wzmocnienie semantyczne
Dlaczego mądrzejsze i bezpieczniejsze rekomendacje mają znaczenie
Za każdym razem, gdy przeglądasz filmy, robisz zakupy online lub czytasz recenzje, systemy rekomendacyjne cicho decydują, co pokazać Ci dalej. W miarę jak nasze życie cyfrowe rozciąga się na wiele aplikacji i stron, te systemy mogłyby działać znacznie lepiej, gdyby mogły uczyć się na podstawie całej Twojej aktywności jednocześnie — nie ujawniając jednak nigdy Twoich prywatnych danych. W artykule przedstawiono FedSCOPE, nowy sposób współpracy różnych platform nad rekomendacjami, które są zarówno dokładniejsze, jak i bardziej szanujące prywatność użytkowników.
Problemy współczesnych silników rekomendacyjnych
Większość obecnych systemów rekomendacyjnych funkcjonuje w ramach jednej aplikacji lub strony i widzi tylko wąski wycinek Twojego zachowania. Oznacza to, że mają trudności z użytkownikami „cold-start”, którzy mają niewiele historii, albo z niszowymi produktami, z którymi mało osób wchodzi w interakcje. Kiedy firmy próbują łączyć dane między domenami — na przykład książki i filmy, albo jedzenie i narzędzia kuchenne — napotykają trzy główne problemy: dane są często rozrzedzone, różne platformy mają bardzo różne typy użytkowników i aktywności, a surowe przepisy dotyczące prywatności sprawiają, że gromadzenie nieprzetworzonych danych w jednym miejscu jest ryzykowne. Proste rozwiązania, jak dodawanie tej samej ilości losowego szumu chroniącego prywatność dla wszystkich, zwykle prowadzą albo do osłabienia ochrony, albo poważnego pogorszenia dokładności.
Pozwolenie modelom językowym uzupełniać luki
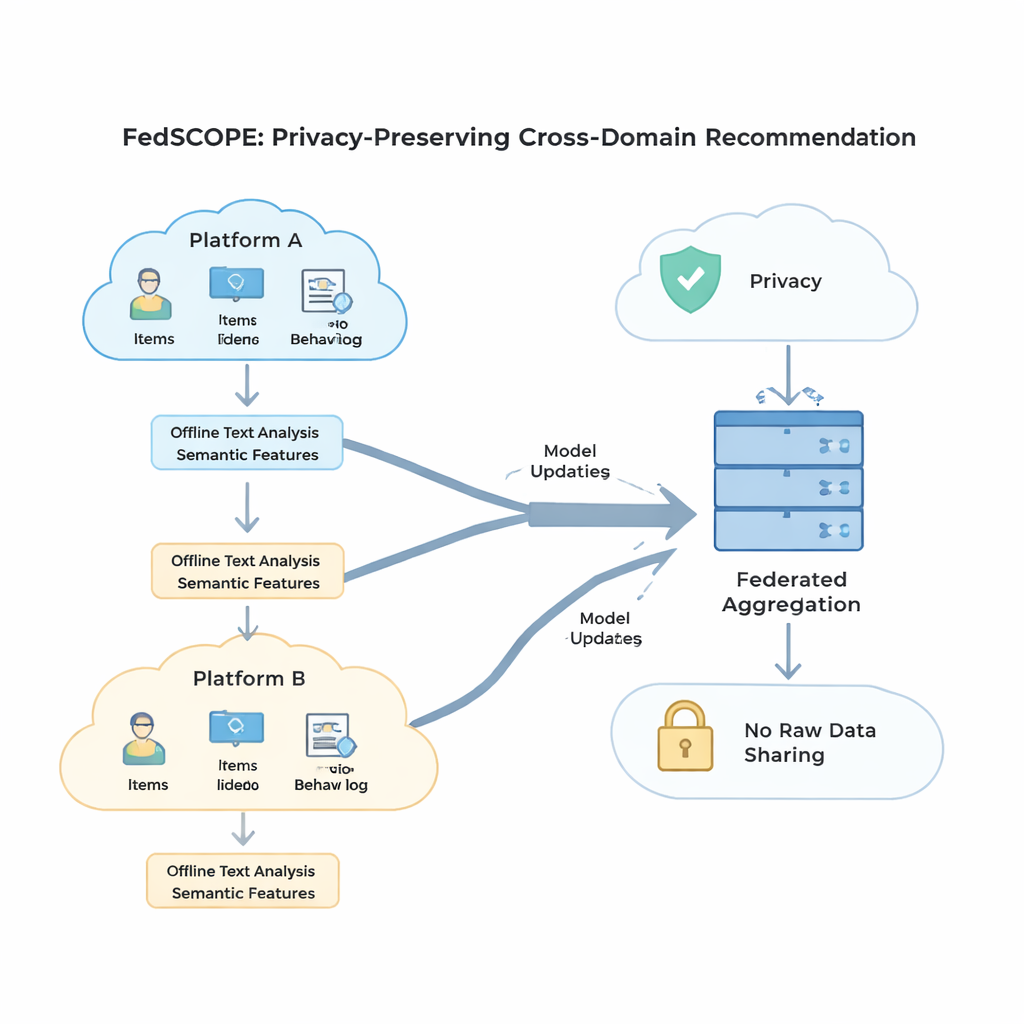
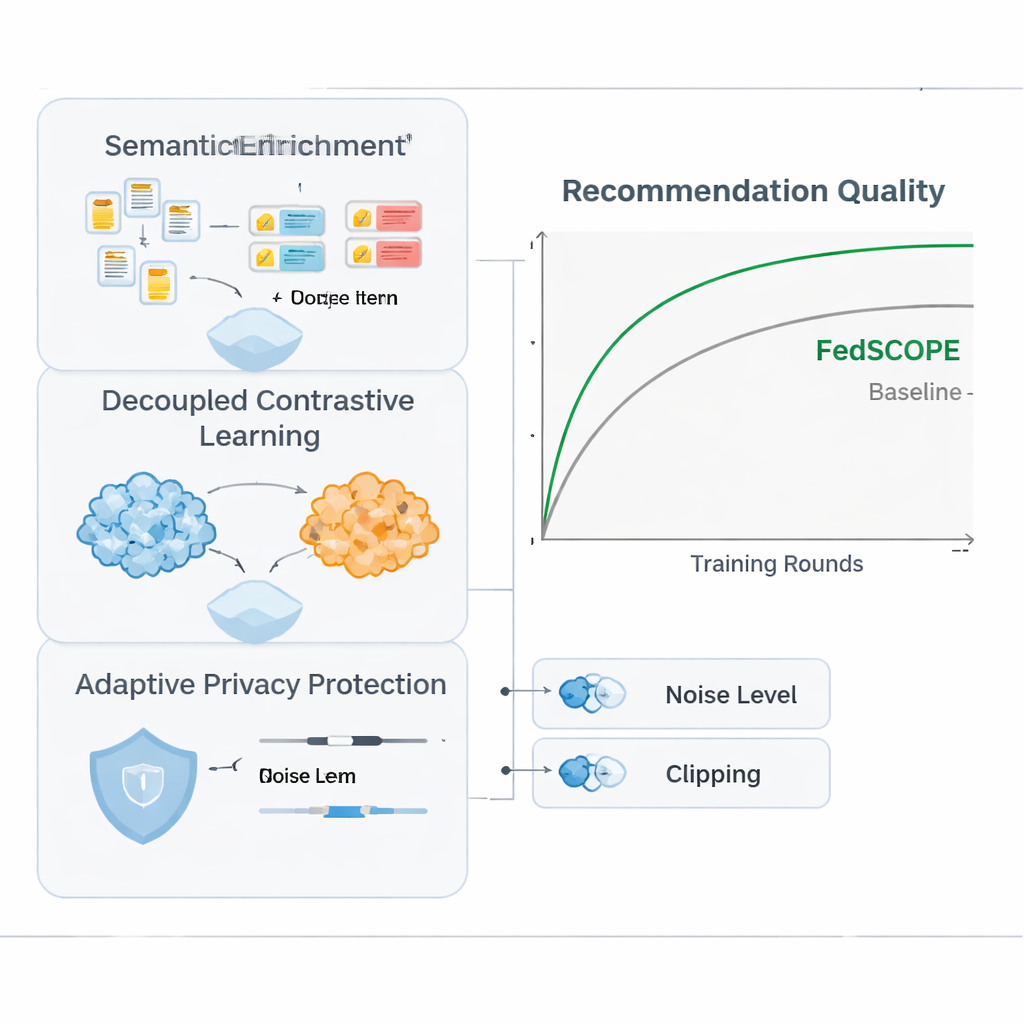
FedSCOPE rozwiązuje problem rozrzedzenia danych, pozwalając każdej platformie wzbogacić swoje dane przy pomocy dużego modelu językowego (LLM), ale w nietypowy, świadomy prywatności sposób. Zamiast wysyłać historie użytkowników do zewnętrznej usługi AI przy każdej rekomendacji, każdy klient wykonuje jednorazowy, offline’owy proces: przekazuje tytuły i podstawowe informacje o przedmiotach (na przykład nazwę filmu i gatunek) do LLM i prosi o uporządkowane opisy, takie jak prawdopodobne motywy, nawyki oglądania czy powiązane zainteresowania. Wygenerowane atrybuty pozostają na lokalnym urządzeniu lub serwerze i są łączone z zwykłymi historiami kliknięć i oglądania za pomocą lekkiej sieci neuronowej. Dzięki temu system zyskuje bogatsze pojęcie o użytkownikach i przedmiotach, co jest szczególnie przydatne przy małej liczbie zarejestrowanych interakcji. Ponieważ proces jest lokalny i offline, surowe zachowania nigdy nie opuszczają platformy i nie ma stałego uzależnienia od zewnętrznych usług AI.
Rozdzielanie tego, co osobiste, od tego, co współdzielone
Aby wykorzystać zachowania pochodzące z wielu domen bez szkodliwego mieszania sygnałów, FedSCOPE wprowadza strategię trenowania nazwaną rozdzielonym uczeniem kontrastowym. Mówiąc w uproszczeniu, system uczy się dwóch rzeczy jednocześnie. Po pierwsze, wewnątrz każdej domeny — na przykład tylko w części dotyczącej filmów — zbliża do siebie użytkowników, którzy zachowują się podobnie, i oddala tych, którzy tego nie robią, wyostrzając poczucie osobistego gustu w tym środowisku. Po drugie, między domenami, dopasowuje reprezentacje tego samego użytkownika, jednocześnie utrzymując rozróżnienie między różnymi użytkownikami, tak aby to, co oglądasz, mogło pomóc przewidzieć, co możesz przeczytać lub kupić, bez zacierania Twojej tożsamości z innymi. Poprzez oddzielne traktowanie celów „wewnątrz-domenowych” i „między-domenowych”, metoda unika powszechnej pułapki polegającej na wymuszaniu jednolitego modelu, który niszczy subtelne preferencje.
Ochrona prywatności bez utraty użyteczności
Mocna, matematyczna ochrona prywatności, znana jako różnicowa prywatność, zwykle polega na dodaniu losowego szumu do aktualizacji modelu przed ich udostępnieniem centralnemu serwerowi. Wiele wcześniejszych systemów stosowało takie same ustawienia prywatności dla każdego uczestnika, co jest słabym rozwiązaniem, gdy niektórzy klienci mają miliony użytkowników, a inni tylko kilka tysięcy. FedSCOPE zamiast tego przyznaje każdemu klientowi spersonalizowany budżet prywatności i dostosowuje, ile przycina i zaburza swoje aktualizacje na podstawie rozmiaru danych i dotychczasowego zachowania. Duże platformy bogate w dane mogą przekazywać bardziej precyzyjne informacje bez nadmiernego zaszumienia, podczas gdy mniejsze są chronione bardziej agresywnie. Wszystkie aktualizacje są następnie łączone przy użyciu bezpiecznej agregacji, tak że serwer nigdy nie widzi żadnego pojedynczego wkładu w postaci jawnej.
Co pokazują eksperymenty w praktyce
Autorzy przetestowali FedSCOPE na rzeczywistych danych zakupowych z Amazon, parując domeny takie jak Filmy z Książkami oraz Jedzenie z Akcesoriami Kuchennymi. Porównali go z szeregiem nowoczesnych metod rekomendacyjnych, w tym innymi podejściami chroniącymi prywatność i międzydomenowymi. W różnych miarach dokładności FedSCOPE konsekwentnie plasował się w czołówce lub blisko niej. Zbiegał szybciej podczas treningu, działał lepiej dla użytkowników z bardzo niewieloma wcześniejszymi interakcjami i dobrze radził sobie przy zmianie liczby uczestniczących klientów lub ułamka próbkowanych w każdej rundzie. Co ważne, gdy zespół zaostrzył ograniczenia prywatności, adaptacyjna strategia FedSCOPE utrzymywała wydajność znacznie wyżej niż systemy stosujące jednolite ustawienia różnicowej prywatności.
Co to oznacza dla codziennych użytkowników
Z perspektywy laika, FedSCOPE wskazuje na przyszłość, w której Twoje ulubione aplikacje mogą współpracować, by lepiej poznać Twoje upodobania, nie łącząc nigdy Twoich nieprzetworzonych danych. Poprzez wzbogacanie rozrzedzonych historii wglądem modelu językowego, staranne rozdzielanie tego, co specyficzne dla domeny, od tego, co współdzielone, oraz dostrajanie kontroli prywatności do każdego uczestnika, ramy te dostarczają rekomendacji, które są zarówno bardziej trafne, jak i bardziej respektujące informacje osobiste. W praktyce może to oznaczać lepsze propozycje tego, co obejrzeć, przeczytać lub kupić następnie — bez konieczności poświęcania swojej cyfrowej prywatności.
Cytowanie: Zhao, L., Lin, Y., Qin, S. et al. FedSCOPE: Federated cross-domain sequential recommendation with decoupled contrastive learning and privacy-preserving semantic enhancement. Sci Rep 16, 7420 (2026). https://doi.org/10.1038/s41598-026-38628-y
Słowa kluczowe: federacyjne rekomendacje, sztuczna inteligencja chroniąca prywatność, personalizacja międzydomenowa, duże modele językowe, różnicowa prywatność