Clear Sky Science · pl
Wykorzystanie przetwarzania języka naturalnego i uczenia maszynowego do identyfikacji chorób przewlekłych w podstawowej opiece zdrowotnej na podstawie elektronicznych kart pacjentów
Dlaczego notatki lekarza są ważniejsze, niż myślisz
Kiedy odwiedzasz lekarza rodzinnego, każdy kaszel, dolegliwość i obawa trafiają do Twojej elektronicznej dokumentacji medycznej. Duża część tych informacji znajduje się w notatkach w formie swobodnego tekstu, a nie w uporządkowanych polach wyboru. Badanie pokazuje, że te narracyjne notatki, połączone z nowoczesnymi technikami komputerowymi, mogą pomóc lekarzom dokładniej wykrywać choroby przewlekłe, takie jak zapalenie stawów, choroby nerek, cukrzyca, nadciśnienie i choroby układu oddechowego — zwłaszcza gdy te problemy nie są wyraźnie zakodowane w innych częściach dokumentacji.
Ukryte wskazówki w codziennych zapisach z gabinetu
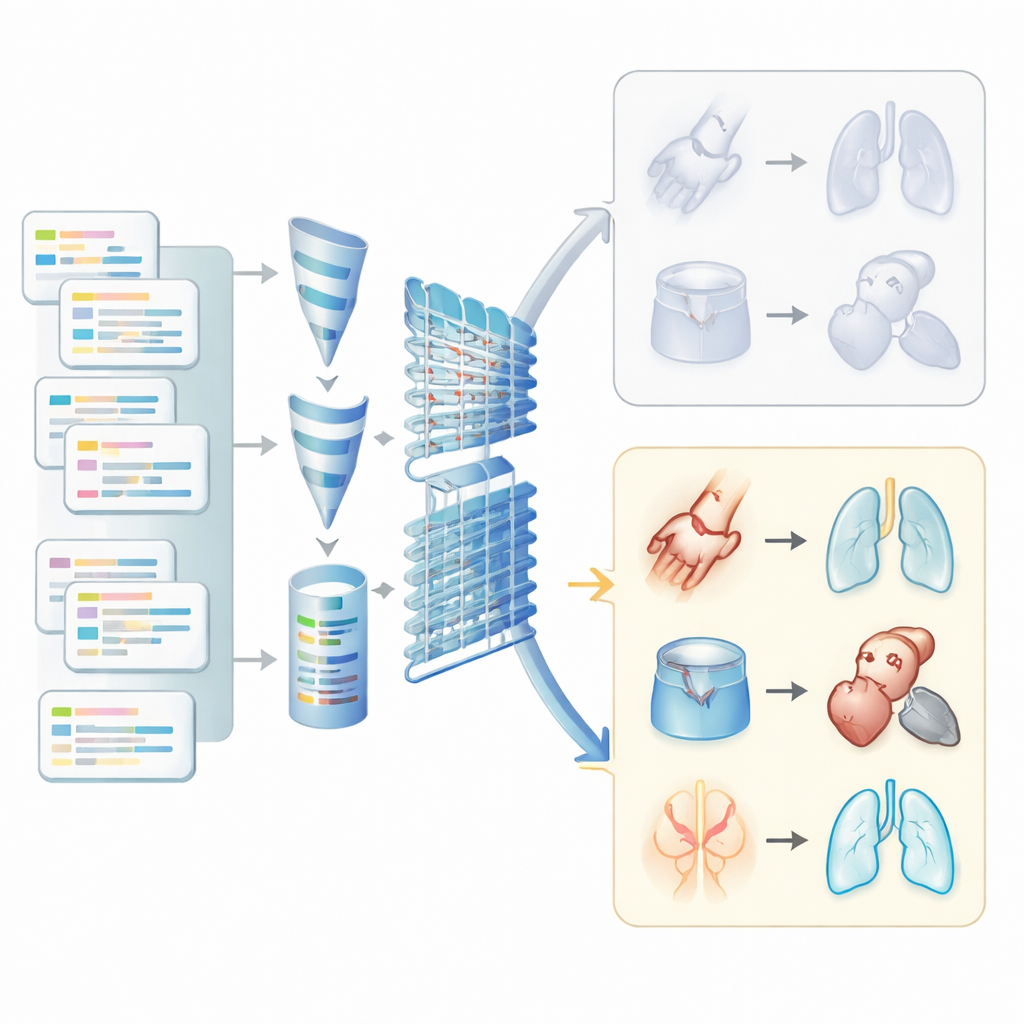
Elektroniczne dokumentacje medyczne w podstawowej opiece zawierają dwa zasadniczo różne rodzaje informacji. Są elementy strukturalne, takie jak kody rozliczeniowe, listy leków i wyniki badań laboratoryjnych, oraz notatki niestrukturalne, gdzie klinicyści opisują objawy, wywiad i swoje rozumowanie zwykłym językiem. W Kanadzie kody rozliczeniowe są często niepełne i służą głównie do rozliczeń, a nie do precyzyjnej diagnozy, więc wiele problemów zdrowotnych ujawnia się wyraźniej w notatkach niż w polach wyboru. Badacze postanowili sprawdzić, czy wydobywanie obu typów informacji razem może lepiej identyfikować pięć powszechnych chorób przewlekłych u pacjentów w wieku 60 lat i starszych, którzy uczęszczali do jednej kliniki rodzinnej w Albercie.

Uczenie komputerów czytania języka lekarzy
Aby wykorzystać bogaty, lecz nieuporządkowany tekst notatek klinicznych, zespół sięgnął po przetwarzanie języka naturalnego — zestaw narzędzi pomagających komputerom pracować z językiem ludzkim. Oczyszczono notatki przez usuwanie zbędnych symboli, ujednolicanie form wyrazów, rozwijanie skrótów i sprowadzanie powiązanych wyrazów do wspólnych rdzeni. Zbudowano też proste reguły rozpoznające, gdy w notatce stwierdzono brak danej choroby — na przykład frazy typu „brak dowodów na” lub „wykluczono” — tak aby komputer nie traktował tych zapisów jako przypadków pozytywnych. Klinicyści w zespole opracowali listy znaczących terminów i fraz dla każdej choroby, pomagając algorytmom skupić się na istotnych pojęciach medycznych zamiast na każdym przypadkowym słowie.
Wyszukiwanie tematów i uczenie się na podstawie wzorców
Następnie badacze skwantyfikowali tekst, aby można go było podać do modeli uczenia maszynowego. Zliczali, jak często każde słowo lub para słów pojawiała się w notatkach danego pacjenta, ale jednocześnie obniżali wagę bardzo popularnych słów i podkreślali te, które były szczególnie charakterystyczne dla danej choroby. Przy użyciu metody zwanej modelowaniem tematów sprawdzili, czy najczęściej występujące grupy słów w notatkach pokrywają się z interesującymi ich stanami — na przykład terminy związane z cukrzycą lub nadciśnieniem. Ten krok służył jako kontrola rzeczywistości, potwierdzając, że tematy zidentyfikowane przez komputer odpowiadają wiedzy klinicznej przed budową modeli predykcyjnych.
Pozwolenie algorytmom wskazywać, kto jest prawdopodobnie chory
Rdzeniem badania było trenowanie trzech typów modeli uczenia maszynowego do oceny, czy każdy pacjent prawdopodobnie miał którąś z pięciu chorób przewlekłych. Jeden model działał jak dopracowany kalkulator ryzyka, inny wytyczał granicę między przypadkami zdrowymi i chorymi, a trzeci przypominał prostą sieć inspirowaną pracą mózgu. Badacze najpierw trenowali te modele używając tylko części strukturalnych dokumentacji, a następnie trenowali je ponownie, wykorzystując zarówno dane strukturalne, jak i przetworzone cechy tekstowe z notatek. Dostosowali też podejście do faktu, że niektóre choroby były w próbce rzadsze, starannie równoważąc dane, aby rzadkie przypadki nie zostały przeoczone przez algorytmy.
Wyraźne korzyści z wykorzystania pełnej historii
Gdy dodano notatki niestrukturalne, modele wyraźnie poprawiły zdolność rozróżniania, kto ma, a kto nie ma danej choroby, szczególnie w przypadku problemów często niedokodowanych w danych rozliczeniowych. Dla zapalenia stawów i chorób układu oddechowego miary oddzielania pacjentów chorych od zdrowych oraz niezawodności wykrywania prawdziwych przypadków poprawiły się znacząco. Na przykład wykrywanie problemów oddechowych i zapalenia stawów przesunęło się z poziomu umiarkowanego do silnego po uwzględnieniu notatek. Dla cukrzycy i nadciśnienia zyski były mniejsze, ponieważ te choroby były już dobrze uchwycone w polach strukturalnych. Co ciekawe, prostsze modele często sprawdzały się równie dobrze lub lepiej niż bardziej złożona sieć neuronowa, co sugeruje, że zaawansowane głębokie uczenie nie zawsze jest konieczne do pracy na poziomie kliniki.
Co to oznacza dla Twojej przyszłej opieki
Podsumowując, badanie pokazuje, że zwracanie uwagi na narracyjne części dokumentacji medycznej — nie tylko na kody i wyniki badań — może znacząco poprawić naszą zdolność do wykrywania pacjentów z chorobami przewlekłymi. Przekształcając notatki w postaci swobodnego tekstu w sygnały czytelne dla maszyn i łącząc je z istniejącymi danymi strukturalnymi, systemy opieki zdrowotnej mogą wcześniej identyfikować pacjentów zagrożonych, skoncentrować opiekę następczą tam, gdzie jest najbardziej potrzebna, oraz rozszerzać to podejście na inne stany, które częściej pojawiają się w pisanej relacji z wizyty niż w menu rozwijanym.
Cytowanie: Zhang, N., Abbasi, M., Khera, S. et al. Leveraging natural language processing and machine learning to identify chronic conditions from primary care electronic medical records. Sci Rep 16, 8441 (2026). https://doi.org/10.1038/s41598-026-38594-5
Słowa kluczowe: elektroniczne karty pacjentów, wykrywanie chorób przewlekłych, przetwarzanie języka naturalnego, uczenie maszynowe w opiece zdrowotnej, dane z podstawowej opieki