Clear Sky Science · pl
Inteligentna inkrementalna klasyfikacja z wykorzystaniem dynamicznej, szarańczowo-wzmacnianej sieci neuronowej dla strumieni danych
Dlaczego dane, które ciągle się zmieniają, mają znaczenie
Od sieci energetycznych i fabryk po płatności online — nowoczesne systemy generują dane co sekundę. W tych ciągłych strumieniach danych kryją się wczesne ostrzeżenia o awariach sprzętu, cyberatakach czy nadchodzących skokach cen. Problem w tym, że ten strumień informacji nigdy nie ustaje, a jego zachowanie zmienia się w czasie. Artykuł streszczony tutaj wprowadza nowy sposób trenowania sieci neuronowych, dzięki któremu mogą one nadal uczyć się z takich danych na żywo bez spowalniania działania czy utraty dokładności, co zwiększa ich użyteczność w monitorowaniu i podejmowaniu decyzji w praktyce.
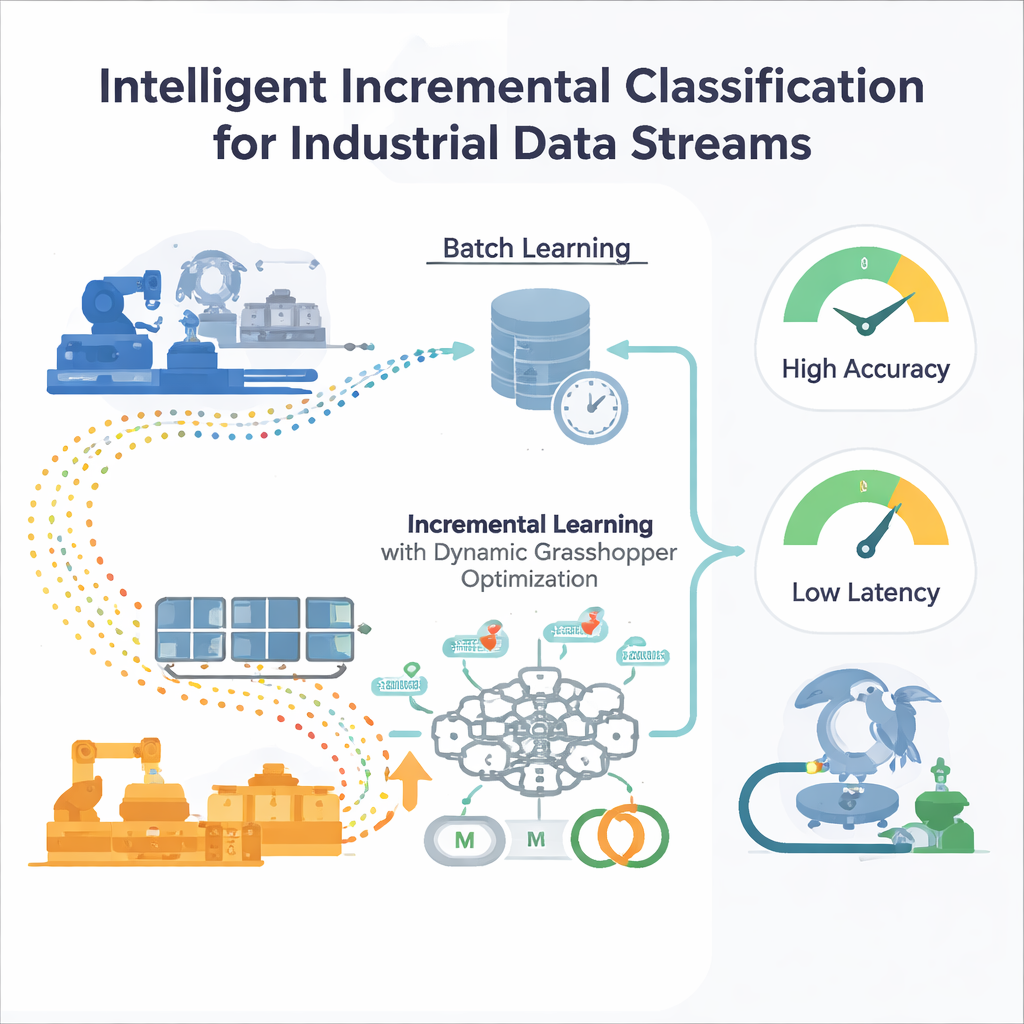
Ograniczenia jednorazowego treningu
Większość tradycyjnych modeli uczenia maszynowego jest trenowana „partiami”: inżynierowie zbierają duży, historyczny zbiór danych, stroją model, a następnie wdrażają go. To działa, jeśli świat pozostaje mniej więcej taki sam. Jednak w środowiskach przemysłowych warunki dryfują — zmieniają się wzorce popytu, czujniki się zużywają, rynki fluktuują. Model zatrzymany w czasie stopniowo przestaje rozpoznawać nowe wzorce, a ponowne trenowanie od zera na rosnących zbiorach danych jest kosztowne i wolne. Standardowe metody automatycznego strojenia, takie jak grid search czy algorytmy ewolucyjne, również zakładają stałe dane, więc muszą być uruchamiane od nowa za każdym razem, gdy rozkład danych się zmienia — co jest niepraktyczne dla systemów działających non-stop.
Sieć neuronowa, która uczy się w locie
Autorzy proponują ramy uczenia przyrostowego oparte na perceptronie wielowarstwowym (MLP), powszechnym typie sieci neuronowej. Zamiast podawać sieci wszystkie przeszłe dane naraz, nadchodzący strumień danych dzielony jest na zarządzalne okna. Każde nowe okno staje się krótkim krokiem treningowym, który aktualizuje wewnętrzne wagi sieci, a następnie jest odrzucane — strategia „trenuj i zapomnij”, która utrzymuje niskie zużycie pamięci. Istotne jest to, że system nie polega na stałych ustawieniach treningowych. Dwa kluczowe pokrętła kontrolujące zachowanie uczenia — współczynnik uczenia (jak duża jest każda aktualizacja) i momentum (jak płynnie przesuwają się aktualizacje) — są ciągle dostosowywane w miarę ewolucji strumienia, dzięki czemu model może pozostać responsywny bez popadania w niestabilność.
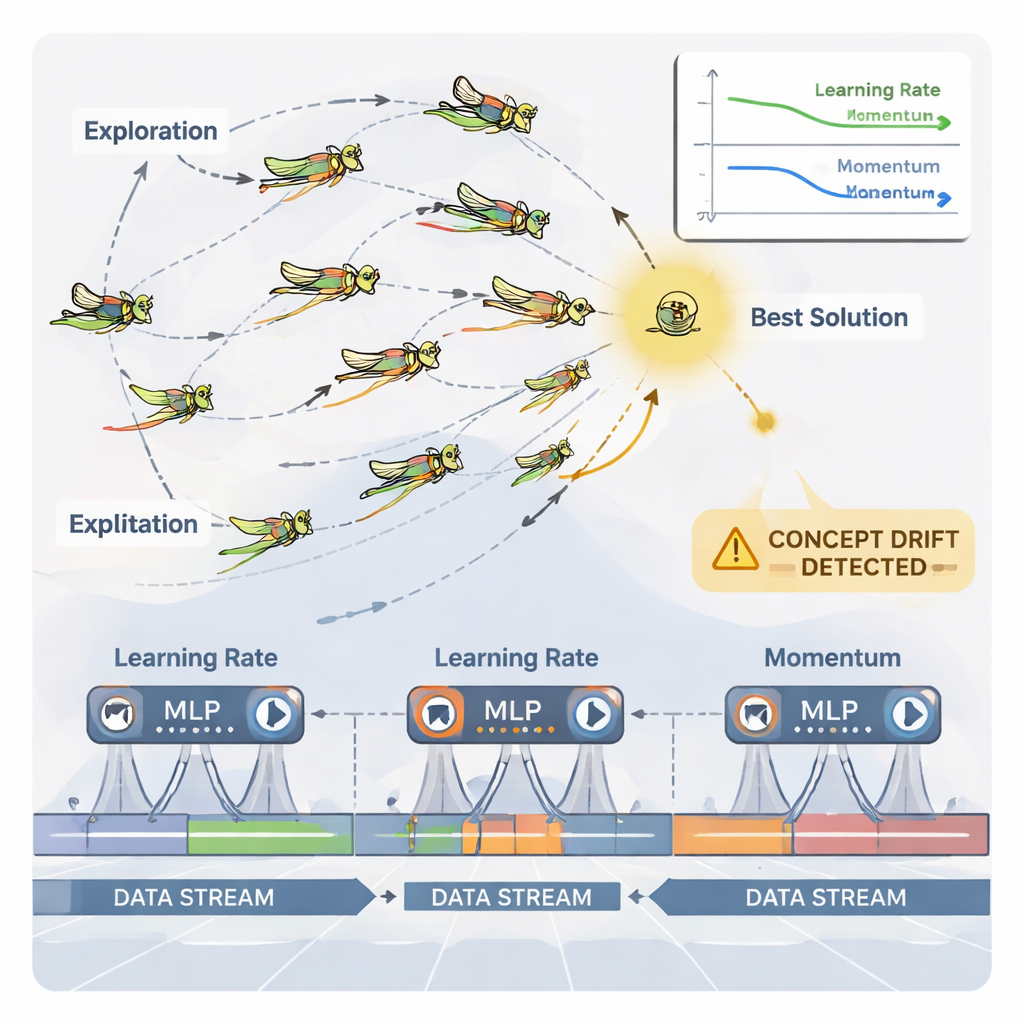
Szarańczyny jako inteligentni stroiciele parametrów
Aby obsłużyć tę ciągłą regulację, artykuł wykorzystuje inspirowany naturą optymalizator zwany Dynamicznym Algorytmem Optymalizacji Szarańczy (DGOA). Wyobraźmy sobie rój wirtualnych szarańczy eksplorujący możliwe kombinacje współczynnika uczenia i momentum. Na początku przemieszczają się szeroko, by znaleźć dobre rejony; później zawężają ruchy, by dopracować obiecujące wybory. W tej dynamicznej wersji ich rozmiar kroków i przyciąganie do najlepszych rozwiązań zmieniają się w czasie w oparciu o to, jak dobrze radzi sobie sieć neuronowa. System dodatkowo monitoruje „dryf pojęciowy” — nagłe zmiany w błędach predykcji lub w samych danych. Gdy wykryty zostanie dryf, niektóre szarańcze są resetowane, a ich kroki tymczasowo się zwiększają, co pozwala optymalizatorowi szybko przeszukać nowe rejony i uciec od przestarzałych ustawień.
Testy metody
Naukowcy ocenili swoje podejście na rzeczywistym zbiorze danych z australijskiego rynku energii, gdzie celem było przewidzieć, czy ceny pójdą w górę czy w dół. W porównaniu z powszechnymi metodami strojenia, takimi jak grid search, random search, optymalizacja rojem cząstek, algorytmy genetyczne, optymalizacja mrowiskowa i standardowy algorytm szarańczy, wersja dynamiczna w połączeniu z uczeniem przyrostowym osiągnęła najwyższą dokładność (około 89,5%) przy jednoczesnym mniejszym wykorzystaniu zasobów obliczeniowych i mniejszej liczbie iteracji. Dodatkowe eksperymenty wykazały, że metoda lepiej dostosowuje się zarówno do stabilnych, jak i zmiennych strumieni danych, skalując się od tysięcy do miliardów próbek przy kontrolowanym użyciu pamięci, oraz wypada konkurencyjnie w zadaniach takich jak utrzymanie predykcyjne, wykrywanie anomalii i wykrywanie oszustw, jak również na standardowych benchmarkach optymalizacji matematycznej.
Co to oznacza w praktyce
Dla osób niebędących ekspertami wniosek jest taki, że ta praca oferuje sposób na utrzymanie sieci neuronowych „żywych” i dobrze dostrojonych w środowiskach, gdzie dane nie przestają napływać, a warunki ciągle się zmieniają. Zamiast wielokrotnie zatrzymywać system, by przebudować modele od podstaw, proponowane ramy pozwalają lekkiej sieci aktualizować się okno po oknie, podczas gdy optymalizator oparty na roju ciągle dostraja, jak szybko i jak płynnie się uczy. Efektem jest szybsze dostosowanie do nowych wzorców, lepsza długoterminowa dokładność i bardziej efektywne wykorzystanie zasobów obliczeniowych — kluczowe elementy dla niezawodnego podejmowania decyzji w czasie rzeczywistym w sektorach takich jak energia, produkcja i finanse.
Cytowanie: Darwish, S.M., El-Shoafy, N.A. Intelligent incremental classification using a dynamic grasshopper-enhanced neural network for data streams. Sci Rep 16, 7730 (2026). https://doi.org/10.1038/s41598-026-38571-y
Słowa kluczowe: strumienie danych, uczenie przyrostowe, sieci neuronowe, optymalizacja hiperparametrów, inteligencja rojowa