Clear Sky Science · pl
Interpretable model uczenia maszynowego wykorzystujący rutynowe dane kliniczne do przewidywania wczesnego nawrotu w raku wątrobowokomórkowym
Dlaczego to ma znaczenie dla pacjentów i rodzin
Dla osób poddawanych operacji usunięcia raka wątroby jedno z najpilniejszych pytań brzmi: „Czy nowotwór szybko powróci?” Obecnie lekarze mogą podać jedynie przybliżone oszacowania, często oparte na szerokich systemach stadializacji, które traktują wielu różnych pacjentów tak, jakby byli tacy sami. To badanie przedstawia nowy sposób wykorzystania informacji, które szpitale już zbierają — rutynowych badań krwi i wyników obrazowania — wraz z interpretowalną sztuczną inteligencją, aby dać każdemu pacjentowi jaśniejszy, bardziej spersonalizowany obraz krótkoterminowego ryzyka nawrotu choroby.
Pospolity nowotwór o uporczywej częstości nawrotów
Rak wątrobowokomórkowy jest najczęstszym typem pierwotnego raka wątroby i istotną przyczyną zgonów z powodu nowotworów na świecie. Nawet gdy chirurdzy całkowicie usuną widoczne guzy, ponad 70% pacjentów doświadcza nawrotu w ciągu pięciu lat. Wczesny nawrót — w przybliżeniu w ciągu dwóch lat po operacji — jest szczególnie niepokojący, ponieważ zazwyczaj odzwierciedla agresywne komórki nowotworowe, które już rozprzestrzeniły się w obrębie wątroby, i znacząco pogarsza rokowanie. Istniejące systemy stadializacji klinicznej, takie jak TNM czy Barcelona Clinic Liver Cancer (BCLC), potrafią w przybliżeniu podzielić pacjentów na szerokie kategorie, ale często zawodzą w precyzyjnym wskazaniu, kto rzeczywiście jest w wysokim ryzyku wczesnego nawrotu.
Przekształcanie codziennych wyników badań w wynik ryzyka
Naukowcy oparli się na zapisach 1 120 pacjentów, którzy przeszli pozornie radykalne zabiegi wątroby w dwóch dużych szpitalach w Chinach w latach 2014–2024. Skoncentrowali się wyłącznie na informacjach dostępnych przed operacją: wieku i płci, cechach obrazowych, takich jak wielkość największego guza i obecność wielu guzów, oraz szerokim panelu standardowych badań laboratoryjnych wykonywanych na kilka dni przed zabiegiem. Z tych danych wyselekcjonowali dziewięć kluczowych predyktorów powiązanych z ryzykiem nawrotu. Zamiast polegać na jednej formule matematycznej, połączyli trzy różne podejścia uczenia maszynowego i uśrednili ich wyniki do jednej skali ryzyka od 0 do 1. Pacjentów podzielono następnie na grupy o niskim, umiarkowanym i wysokim ryzyku na podstawie tego wskaźnika. 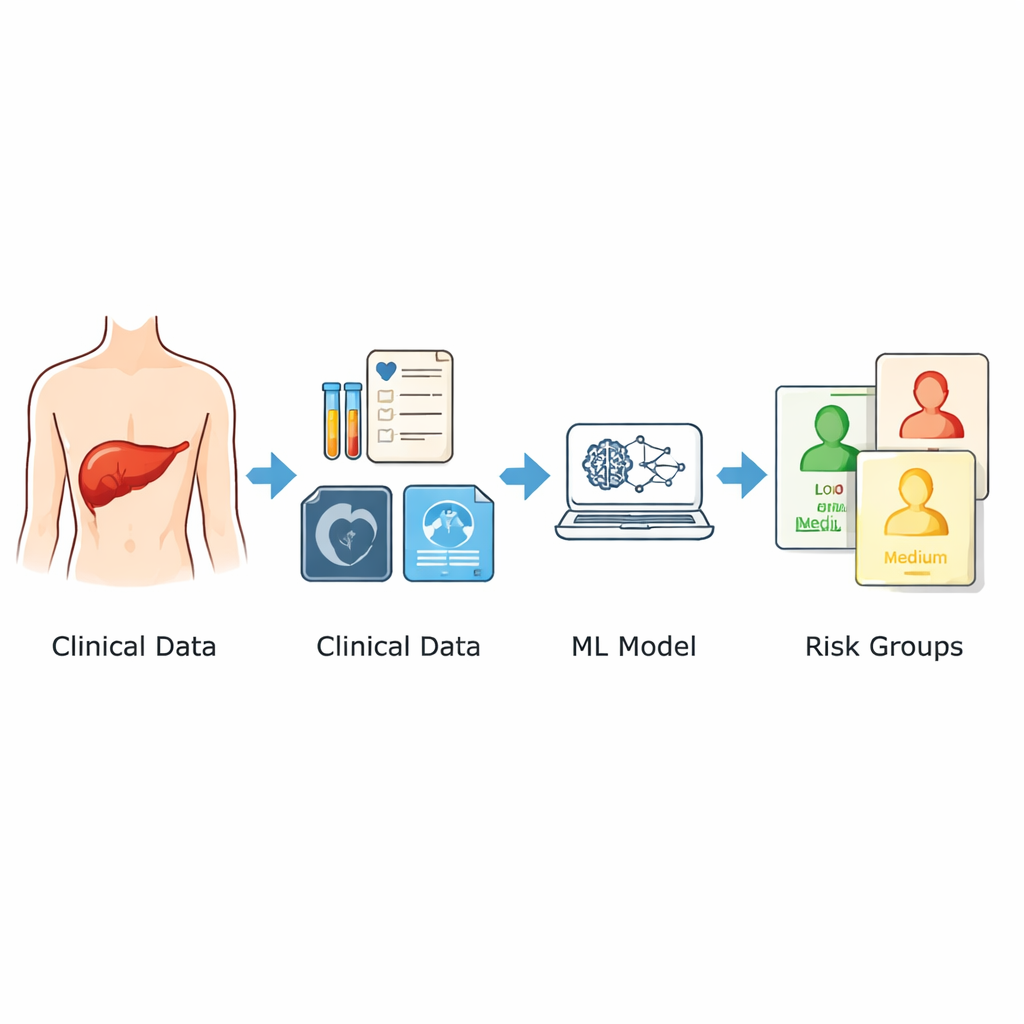
Przewyższanie standardowych systemów stadializacji
Aby sprawdzić skuteczność modelu, zespół najpierw ocenił go na zbiorze „hold-out” pacjentów z pierwotnego szpitala, a następnie na niezależnej grupie z drugiego szpitala. W obu przypadkach nowy model wyraźnie lepiej rozróżniał, kto pozostanie wolny od choroby, a kto doświadczy nawrotu w ciągu 24 miesięcy, niż tradycyjne systemy stadializacji. W wewnętrznym zbiorze testowym dokładność modelu w czasie, mierzona standardową statystyką zwaną polem pod krzywą (AUC), wynosiła około 0,76, w porównaniu z około 0,55–0,64 dla powszechnych metod stadializacji. Osoby w grupie wysokiego ryzyka miały najgorsze przeżycie wolne od nawrotu, w grupie umiarkowanego ryzyka odnotowano zmniejszenie ryzyka nawrotu o około 60%, a w grupie niskiego ryzyka hazard nawrotu był o około 90% niższy niż w grupie wysokiego ryzyka. Silne różnice utrzymały się również w zewnętrznym szpitalu i były spójne w większości podgrup, takich jak młodsi i starsi pacjenci, mężczyźni i kobiety oraz osoby z dużymi lub małymi guzami.
Otwieranie „czarnej skrzynki” sztucznej inteligencji
Częstą krytyką uczenia maszynowego w medycynie jest to, że działa jak czarna skrzynka: może dobrze przewidywać, ale nawet specjaliści nie widzą dlaczego. Aby temu zaradzić, autorzy zastosowali metodę zwaną SHapley Additive exPlanations (SHAP), która rozkłada każdą prognozę na wkłady poszczególnych czynników wejściowych. Analiza wykazała, że rozmiar guza był najsilniejszym pojedynczym czynnikiem zwiększającym ryzyko we wszystkich trzech algorytmach, za nim znajdowały się cechy takie jak liczba guzów oraz wskaźniki krwiowe funkcji wątroby i zapalenia. Co ciekawe, poziom chlorków we krwi miał tendencję do przesuwania ryzyka w przeciwnym kierunku, działając jako czynnik ochronny w tym zbiorze danych. Dla indywidualnych pacjentów model może generować proste wykresy słupkowe, które pokazują, na przykład, jak duża średnica guza i niekorzystne markery krwi podnoszą wynik ryzyka, podczas gdy lepsza funkcja wątroby go obniża. 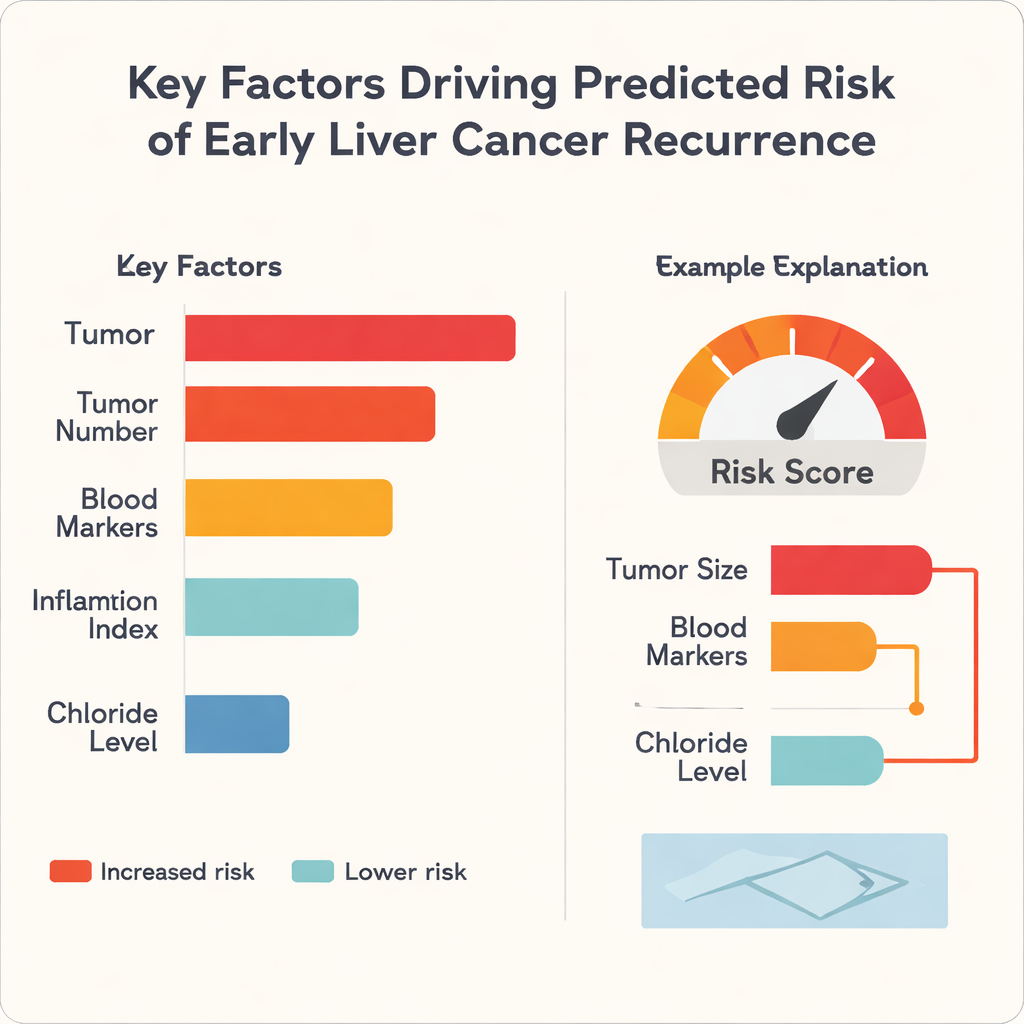
Co to może oznaczać w praktyce klinicznej
Ponieważ model działa na danych, które szpitale już zbierają i nie wymaga specjalnych badań obrazowych ani kosztownych testów genetycznych, może zostać wdrożony w wielu różnych warunkach opieki, także w placówkach o ograniczonych zasobach. Przed operacją lekarze mogliby go użyć, aby zidentyfikować osoby potrzebujące intensywniejszych terminów kontroli lub mogące odnieść korzyść z dodatkowych terapii po zabiegu, jednocześnie oszczędzając rzeczywiście niskiego ryzyka pacjentom niepotrzebnych badań i niepokoju. Autorzy zaznaczają, że ich badanie ma charakter retrospektywny i opiera się na konkretnej populacji pacjentów, więc nadal potrzebne są prospektywne próby w bardziej zróżnicowanych warunkach. Niemniej ich praca ilustruje, jak przejrzysta, wyjaśnialna sztuczna inteligencja może przekształcić znane wyniki laboratoryjne i obrazowe w sensowne, zindywidualizowane prognozy wspierające wspólne podejmowanie decyzji między pacjentami a zespołami opiekuńczymi.
Cytowanie: Guo, DF., Wen, Q., Zhang, X. et al. An interpretable machine learning model using routine clinical data for early recurrence prediction in hepatocellular carcinoma. Sci Rep 16, 7520 (2026). https://doi.org/10.1038/s41598-026-38484-w
Słowa kluczowe: nawrót raka wątroby, model uczenia maszynowego, kliniczne przewidywanie ryzyka, interpretowalna sztuczna inteligencja, rak wątrobowokomórkowy