Clear Sky Science · pl
Wyjaśnialny hybrydowy model CNN–transformer do rozpoznawania języka migowego na urządzeniach brzegowych z adaptacyjną fuzją i destylacją wiedzy
Dlaczego małe narzędzia do języka migowego mają znaczenie
Miliardy codziennych rozmów opierają się na ruchach rąk, mimice i mowie ciała zamiast słów. Mimo to większość telefonów, tabletów i urządzeń publicznych nadal nie rozumie języków migowych, zwłaszcza poza krajami anglojęzycznymi. W artykule przedstawiono TinyMSLR, kompaktowy i wyjaśnialny system rozpoznawania języka migowego zaprojektowany do pracy w czasie rzeczywistym na małych, energooszczędnych urządzeniach. Ma on na celu przekształcenie pospolitego sprzętu w przystępne i godne zaufania narzędzie komunikacyjne dla osób Głuchych i niedosłyszących na całym świecie.
Włączanie większej liczby języków do dyskusji
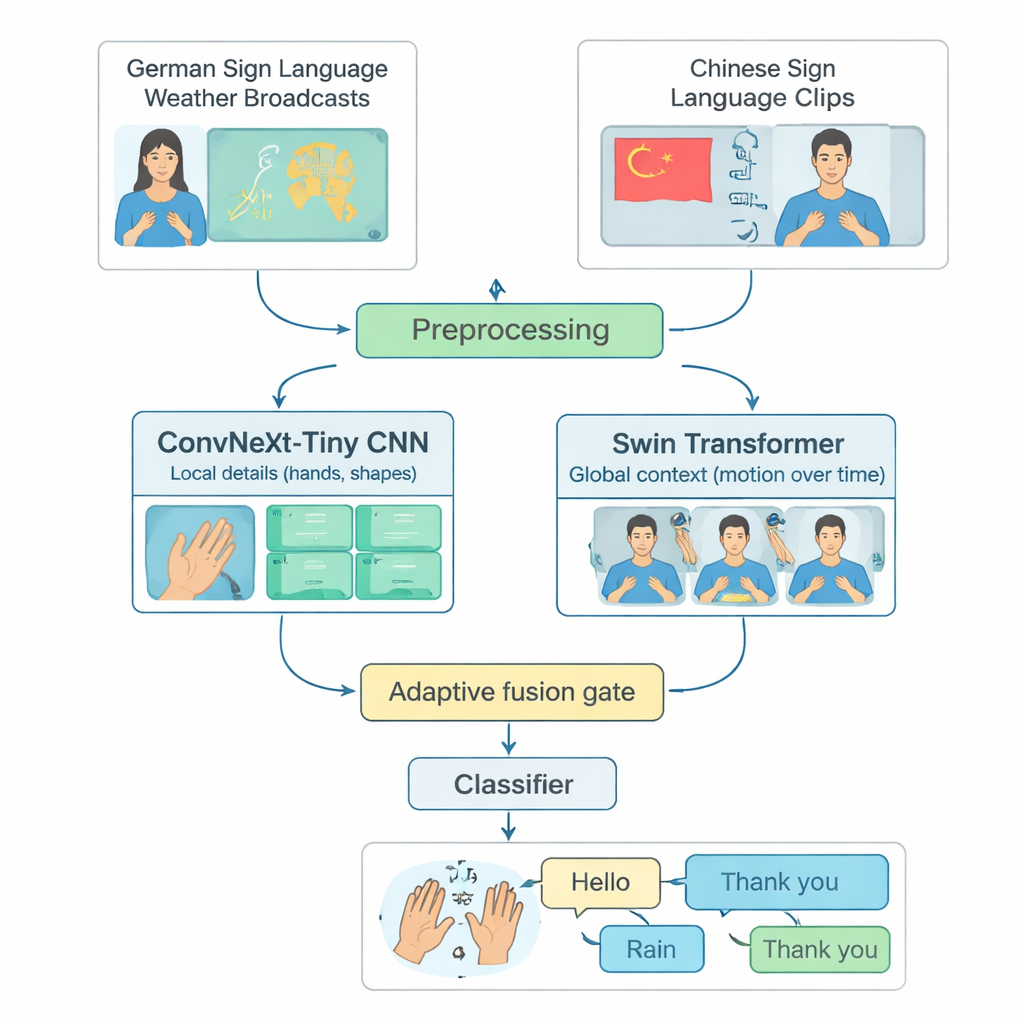
Wiele zaawansowanych systemów rozpoznawania języka migowego skupia się na jednym języku, najczęściej na amerykańskim języku migowym, i działa tylko na wydajnych komputerach. Pomija to osoby używające innych języków migowych lub żyjące w regionach o ograniczonych zasobach obliczeniowych. Autorzy rozwiązują tę lukę, budując wspólne środowisko testowe z dwóch różnych języków: transmisji pogodowych w niemieckim języku migowym oraz dużej kolekcji chińskiego języka migowego. Starannie wybierają 20 powszechnych znaków codziennych — takich jak Cześć, Pogoda, Deszcz, Szczęśliwy, Tak i Dziękuję — które występują w obu językach. Skracając długie nagrania do krótkich klipów zawierających pojedynczy znak i wyrównując liczbę przykładów na klasę i na podpisującego, tworzą uczciwy, powtarzalny sposób oceniania, jak dobrze model rozpoznaje izolowane znaki międzyjęzykowo.
Jak hybrydowy model widzi dłonie i ruch
TinyMSLR łączy dwa uzupełniające się sposoby analizy wideo. Jedna gałąź wykorzystuje nowoczesną sieć splotową (ConvNeXt‑Tiny), która świetnie wychwytuje drobne detale, jak kształty palców i subtelne tekstury. Druga gałąź używa Swin Transformera, nowszej rodziny modeli doskonałej w śledzeniu wzorców w przestrzeni i czasie — jak ręce, twarz i górna część ciała poruszają się przez kolejne klatki. Każdy krótki klip wideo standaryzowany jest do 32 klatek o rozdzielczości 224×224 pikseli, delikatnie augmentowany (np. małe rotacje lub zmiany jasności), a następnie podawany równolegle do obu gałęzi. Każda gałąź generuje 768‑elementowe podsumowanie tego, co widzi; razem te dwa podsumowania uchwycają zarówno wyraźne lokalne detale, jak i szerszy ruch oraz kontekst.
Pozwalanie modelowi zdecydować, co jest najważniejsze
Ponieważ niektóre znaki rozróżniane są głównie przez kształt dłoni, a inne polegają na szerszych ruchach ramion lub sygnałach mimicznych, TinyMSLR nie narzuca jednej recepty na łączenie obu spojrzeń. Zamiast tego używa małej „bramki fuzji”, która uczy się dla każdego klipu, ile zaufać gałęzi skupionej na detalach versus tej skupionej na kontekście. Bramka analizuje oba podsumowania cech i wypuszcza dwie wagi, które zawsze sumują się do jedności; końcowa reprezentacja to ważona mieszanka obu. Podczas treningu każda gałąź otrzymuje też własny mały klasyfikator, żeby nauczyć się być użyteczna samodzielnie, a para większych „nauczycielskich” sieci (jedna CNN, jedna Transformer) delikatnie prowadzi mały model, pokazując nie tylko właściwą etykietę, ale też które etykiety alternatywne są podobne. Ta technika, zwana destylacją wiedzy, pomaga kompaktowemu systemowi zbliżyć się do dokładności cięższych modeli przy zachowaniu odpowiedniego rozmiaru i prędkości dla urządzeń brzegowych.
Widzienie, dlaczego system podejmuje każdą decyzję
Ponadto autorzy podkreślają, że użytkownicy i deweloperzy powinni móc sprawdzić, na co model zwraca uwagę. Przyjmują SHAP, rodzinę narzędzi przypisujących wartość ważności każdej części wejścia. W praktyce obliczają te wyjaśnienia na cechach pośrednich i mapują je z powrotem na klatki jako mapy cieplne i wykresy czasowe. To ujawnia, na przykład, które klatki i regiony decydują o rozróżnieniu wizualnie podobnych znaków, jak Deszcz i Śnieg czy Zimno i Źle. Agregowanie wielu wyjaśnień pokazuje szersze wzorce: sygnały niemanualne, takie jak mimika i ruch głowy, a także orientacja nadgarstka i kształt dłoni, okazują się szczególnie wpływowe. Te spostrzeżenia pomagają zweryfikować, że system opiera się na znaczących aspektach migania, a nie na artefaktach tła.

Szybkość, oszczędność i pole do rozwoju
Na dwujęzycznym zestawie testowym 20 znaków TinyMSLR osiąga około 99% dokładności w trenowaniu i walidacji oraz F1 bliskie 99%, używając mniej niż 2,7 miliona parametrów i około 1,9 miliarda operacji na klip. Na nowoczesnym GPU przetwarzanie pojedynczego znaku zajmuje mniej więcej 13,5 milisekundy i zużywa poniżej 30 miliodżuli energii; zapisany model zajmuje tylko około 7,2 megabajta. Te liczby sugerują, że rozpoznawanie znaków w czasie rzeczywistym bezpośrednio na urządzeniu jest realne na tanich płytkach i systemach wbudowanych. Autorzy ostrożnie zaznaczają, że ich praca obejmuje tylko krótkie, izolowane znaki i dwa języki oraz traktuje mimikę pośrednio, zamiast jako osobny sygnał. Rozszerzenie podejścia na bogatsze słownictwo, ciągłe zdania, więcej języków i jawne modelowanie ruchów twarzy i głowy pozostawiono na przyszłość. Mimo to TinyMSLR stanowi przekonujący dowód koncepcji: dokładne, wydajne i interpretowalne narzędzia do rozumienia języków migowych nie muszą być ograniczone do chmury — mogą działać bezpośrednio na codziennych urządzeniach.
Cytowanie: Lamaakal, I., Yahyati, C., Maleh, Y. et al. An explainable hybrid CNN–transformer model for sign language recognition on edge devices using adaptive fusion and knowledge distillation. Sci Rep 16, 7143 (2026). https://doi.org/10.1038/s41598-026-38478-8
Słowa kluczowe: rozpoznawanie języka migowego, tiny machine learning, edge AI, wyjaśnialna sztuczna inteligencja, modele wielojęzyczne