Clear Sky Science · pl
Porównanie sztucznej inteligencji i zaleceń zespołów multidyscyplinarnych w leczeniu przerzutów raka jelita grubego do wątroby
Dlaczego to ma znaczenie dla pacjentów i rodzin
Dla wielu osób z rakiem jelita grubego choroba może rozsiać się do wątroby, co sprawia, że decyzje terapeutyczne stają się wyścigiem z czasem. Obecnie wybory te zwykle podejmują zespoły multidyscyplinarne — grupy specjalistów spotykające się, by uzgodnić najlepszy plan. Równocześnie w gabinetach lekarskich pojawiają się czatowe narzędzia sztucznej inteligencji, takie jak ChatGPT, jako potencjalne wsparcie. W badaniu postawiono proste, ale istotne pytanie: gdy przedstawiono te same streszczenia pacjentów, na ile sugestie SI pokrywają się z decyzjami ekspertów?
Jak zwykle podejmowane są decyzje terapeutyczne
Gdy rak jelita grubego daje przerzuty do wątroby, opcje leczenia obejmują m.in. zabieg chirurgiczny, chemioterapię lub opiekę ukierunkowaną na łagodzenie objawów. Wybór między tymi ścieżkami rzadko jest jednoznaczny. Szpitale polegają na spotkaniach zespołów multidyscyplinarnych (MDT), które gromadzą chirurgów, onkologów klinicznych, radiologów i innych ekspertów. Dyskusje te uwzględniają wielkość i liczbę zmian, wyniki badań obrazowych, ogólny stan zdrowia pacjenta oraz szanse, że zabieg chirurgiczny usunie widoczne ogniska choroby. Model zespołowy poprawia przeżywalność i pomaga zapewnić spójne, opierające się na dowodach leczenie, ale jest też czasochłonny i wymaga dostępności odpowiednich specjalistów.
Co badacze postanowili sprawdzić
Autorzy zbadali, czy system czatowy oparty na SI mógłby pełnić rolę partnera wspomagającego decyzję dla tych zespołów ekspertów, a nie ich zastępcy. Skoncentrowali się na 30 pacjentach z rakiem jelita grubego z przerzutami do wątroby, wcześniej omawianych przez MDT w jednym szpitalu. Dla każdego pacjenta przygotowano ujednolicone, zanonimizowane streszczenie tekstowe zawierające kluczowe dane kliniczne i wyniki badań obrazowych, przy czym system SI nie miał dostępu do obrazów ani pełnej dokumentacji medycznej. Następnie poproszono ChatGPT o wskazanie najbardziej odpowiedniego leczenia, powtarzając pytanie trzykrotnie dla każdego przypadku, by sprawdzić stabilność odpowiedzi. W drugiej rundzie dodano jedną istotną informację: wyraźnie zaznaczono, że guzy wątroby wydają się potencjalnie możliwe do zoperowania, i zapytano, czy to powinno zmienić plan.
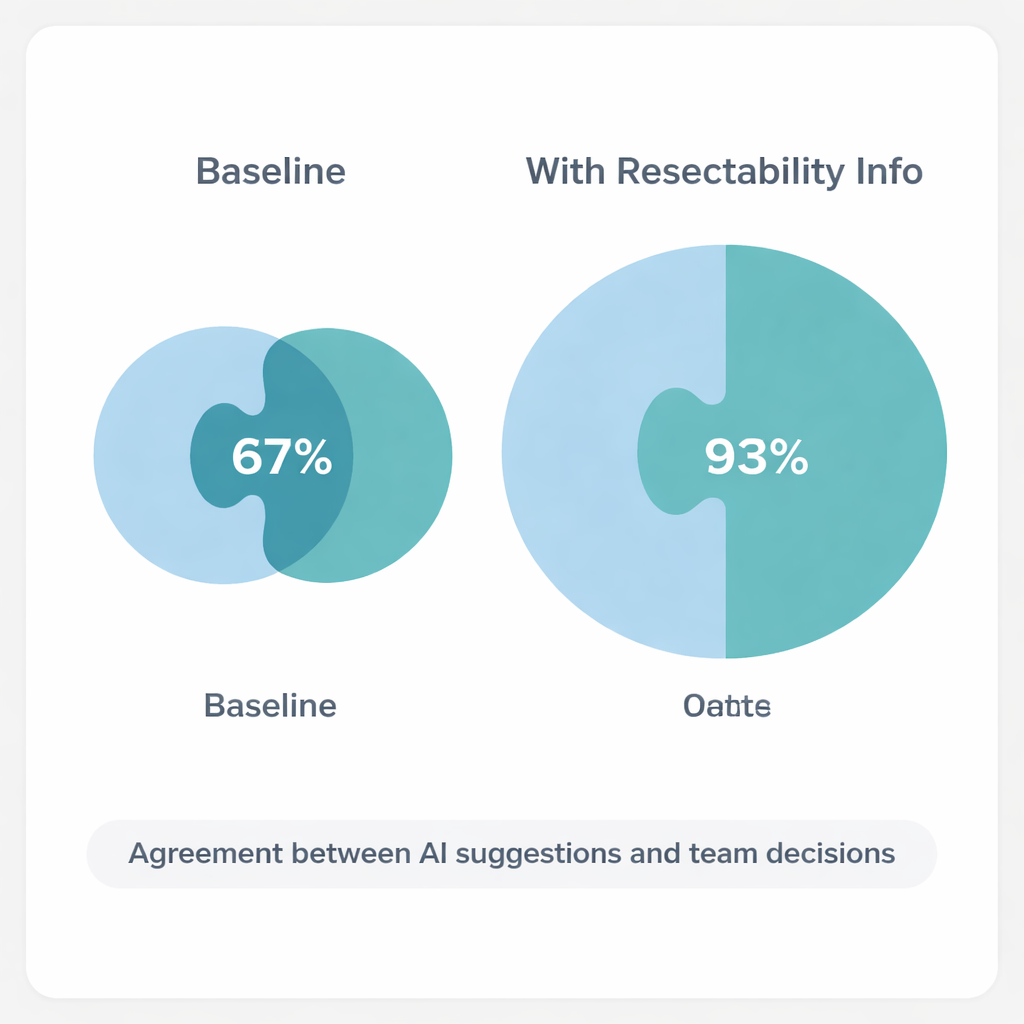
Na ile SI zgadzała się z zespołem ekspertów
SI udzielała tego samego rodzaju zalecenia za każdym razem, gdy pytano o dany przypadek, wykazując bardzo wysoką spójność wewnętrzną. Pracując tylko na podstawie podstawowych streszczeń, jej ostateczne zalecenie pokrywało się z jednogłośną decyzją MDT w około dwóch trzecich przypadków (20 z 30). Większość niezgodności wynikała z tego, że SI wybierała bardziej ostrożne kroki — na przykład proponowała najpierw chemioterapię, dodatkowe badania obrazowe lub biopsje — podczas gdy zespół ekspertów w starannie wybranych przypadkach decydował się od razu na zabieg chirurgiczny. Gdy badacze powtórzyli eksperyment, wyraźnie podkreślając, że przerzuty do wątroby wydają się operacyjne, zgodność gwałtownie wzrosła. W tym scenariuszu „określonej resekcyjności” SI i MDT zgadzały się w 28 z 30 przypadków, czyli w 93%, co autorzy określili jako bardzo dobrą zgodność.
Co ujawniają wzorce niezgodności
Nawet po podaniu dodatkowej informacji pozostały dwa przypadki, w których SI rekomendowała kontynuację leczenia ogólnoustrojowego zamiast zabiegu, podczas gdy MDT zdecydowało się na operację mającą na celu długoterminową kontrolę choroby. W całym badaniu SI skłaniała się ku zachowawczym wyborom przy najmniejszym choćby śladzie niepewności, co najprawdopodobniej odzwierciedla zarówno trening ukierunkowany na bezpieczeństwo, jak i ograniczenia wynikające z pracy na krótkich streszczeniach tekstowych. Autorzy i wcześniejsze badania zauważają też, że takie systemy mogą zachowywać się różnie w różnych szpitalach, dla różnych typów nowotworów i wersji oprogramowania, co oznacza, że wyniki z jednego środowiska nie muszą być powtarzalne wszędzie. Podkreślają również, że istotne czynniki ludzkie — jak preferencje pacjenta, wartości czy codzienna jakość życia — trudno uchwycić w tekście czy wytycznych i nadal należą do domeny bezpośredniej oceny klinicznej.
Co to może znaczyć dla przyszłej opieki onkologicznej
To niewielkie badanie pilotażowe sugeruje, że przy dostępie do jasnych i kompletnych informacji pisemnych czatowa SI często może dochodzić do podobnych sugestii terapeutycznych co doświadczony zespół onkologiczny w przypadkach raka jelita grubego z przerzutami do wątroby. Jednak zgodność z decyzjami ekspertów „na papierze” nie jest równoznaczna z dowodem, że opieka wspomagana przez SI jest bezpieczna lub poprawia wyniki. Autorzy podkreślają, że takie systemy powinny być traktowane co najwyżej jako nadzorowane asystenty — użyteczne do porządkowania streszczeń przypadków lub wskazywania brakujących szczegółów — a nie jako autonomiczni decydenci. Zanim narzędzia te zostaną dopuszczone do rutynowego stosowania, konieczne będą większe, prospektywne badania śledzące rzeczywiste wyniki pacjentów, a nie tylko wskaźniki zgodności.
Cytowanie: Yılmaz, M., Abbaslı, N., Tuna, S. et al. Comparison of artificial intelligence and multidisciplinary team recommendations in the management of colorectal cancer liver metastases. Sci Rep 16, 7278 (2026). https://doi.org/10.1038/s41598-026-38449-z
Słowa kluczowe: rak jelita grubego, przerzuty do wątroby, zespoły multidyscyplinarne, wspomaganie decyzji klinicznych, sztuczna inteligencja w onkologii