Clear Sky Science · pl
SAT: Shift Alignment Transformer do odszumiania wideo bez estymacji przepływu
Bardziej ostre filmy z zaszumionych scen
Każdy, kto próbował nagrywać w pomieszczeniu w nocy lub telefonem przy słabym świetle, zna efekt: ziarniste, migoczące wideo, w którym szczegóły wydają się powoli przesuwać, a kolory są zniekształcone. W artykule przedstawiono nowy sposób oczyszczania takich materiałów, przekształcający je w wyraźniejsze, bardziej stabilne sekwencje bez polegania na ciężkich algorytmach śledzenia ruchu, które zwykle to umożliwiają. Metoda nazwana Shift Alignment Transformer została zaprojektowana tak, by zachować drobne detale przy jednoczesnym zachowaniu wydajności praktycznej.
Dlaczego oczyszczanie wideo jest tak trudne
Usuwanie szumu z pojedynczego zdjęcia jest już wyzwaniem; zrobienie tego dla wideo jest jeszcze trudniejsze. Z jednej strony każda klatka jest zniekształcona przez losowe plamki i przesunięcia kolorów. Z drugiej strony klatki są powiązane w czasie: obiekty się poruszają, kamera drży, a szczegóły pojawiają się i znikają. Tradycyjne metody odszumiania wideo opierały się na estymacji ruchu między klatkami, często za pomocą tzw. optycznego przepływu, który próbuje śledzić, gdzie każdy piksel przesuwa się z jednej klatki do drugiej. Choć potężne, takie estymaty ruchu łatwo zawodzą, gdy wideo jest bardzo zaszumione lub ruch jest szybki i złożony, a dodatkowo znacząco obciążają obliczenia, spowalniając systemy.
Nowy sposób wyrównywania bez śledzenia
Zamiast jawnie próbować śledzić każdy piksel, Shift Alignment Transformer (SAT) wybiera inną drogę: pozwala sieci w sposób ukryty odkrywać powiązania między klatkami przez staranne przesuwanie i porównywanie cech. Model opiera się na nowoczesnej architekturze zwanej Transformerem, która świetnie odnajduje długozasięgowe powiązania w danych. W ramach tego podejścia autorzy wprowadzają moduł przesunięć przestrzenno‑czasowych (Spatial-Temporal Shift Module), który delikatnie miesza informacje w czasie i przestrzeni. W czasie model cyklicznie przesuwa cechy klatek tak, że warstwa po warstwie każda klatka może „zobaczyć” dalej w przeszłość i przyszłość. W przestrzeni dzieli cechy na wiele małych grup i przemieszcza każdą grupę w różnych kierunkach. To połączenie efektywnie imituje, jak obiekty mogą się przesuwać w wideo, pozwalając sieci wyrównywać informacje z różnych klatek bez obliczania jawnego pola ruchu.
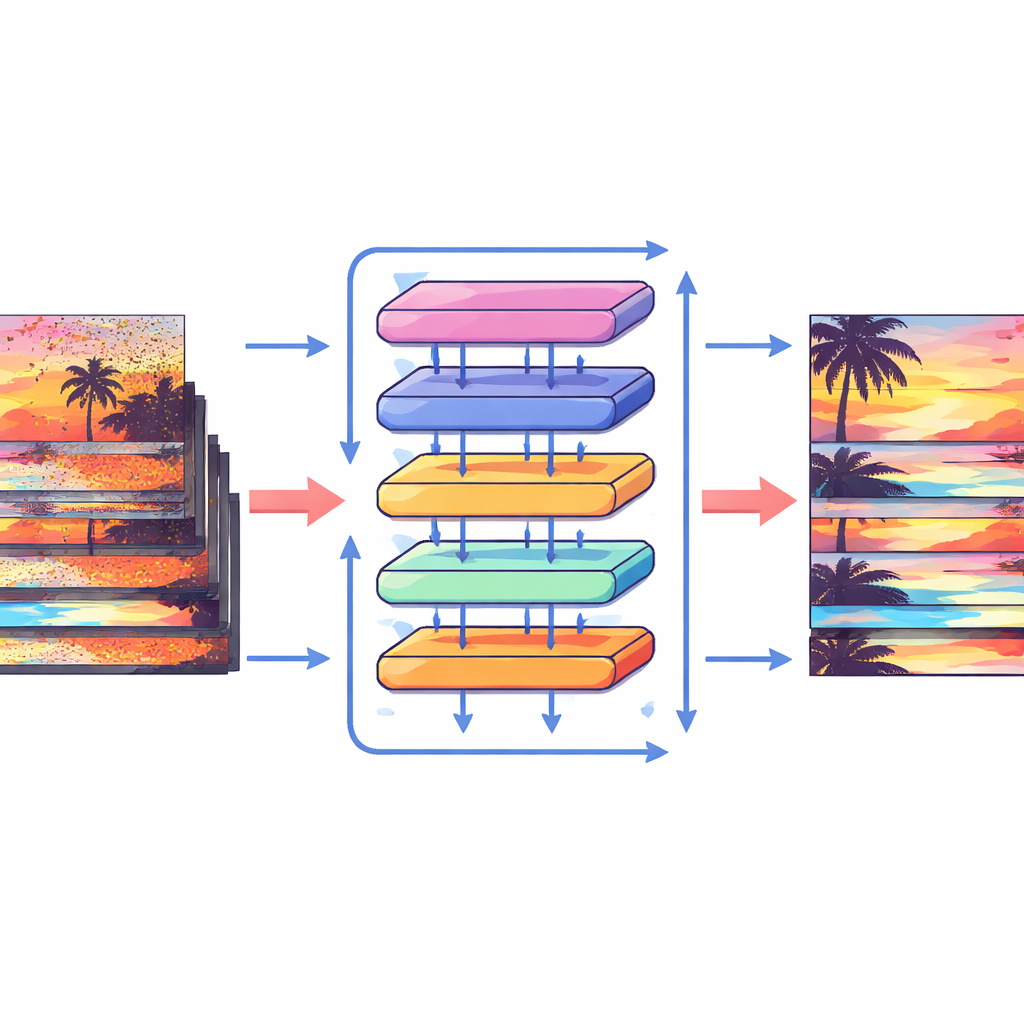
Jak działają nowe elementy konstrukcyjne
Aby w pełni wykorzystać te przesunięcia, autorzy zaprojektowali specjalny blok uwagi, który łączy informacje wewnątrz i między klatkami. Najpierw przesunięte cechy z sąsiednich klatek są zestawiane i porównywane przy użyciu operacji cross-attention: model uczy się, które regiony w innych klatkach najlepiej wspierają bieżącą klatkę w każdym miejscu. Równocześnie osobna operacja uwagi skupia się na relacjach w ramach pojedynczej klatki, wzmacniając strukturę lokalną i teksturę. Te dwa strumienie są następnie łączone i przekazywane przez proste warstwy przetwarzające w wieloskalowej, U‑kształtnej sieci, która przechodzi od grubego do drobnego rozdzielczości i z powrotem. Taka konfiguracja pozwala systemowi radzić sobie zarówno z dużymi ruchami kamery, jak i drobnymi detalami, takimi jak cienkie krawędzie czy małe wzory, stopniowo rekonstruując czystą wersję każdej klatki.
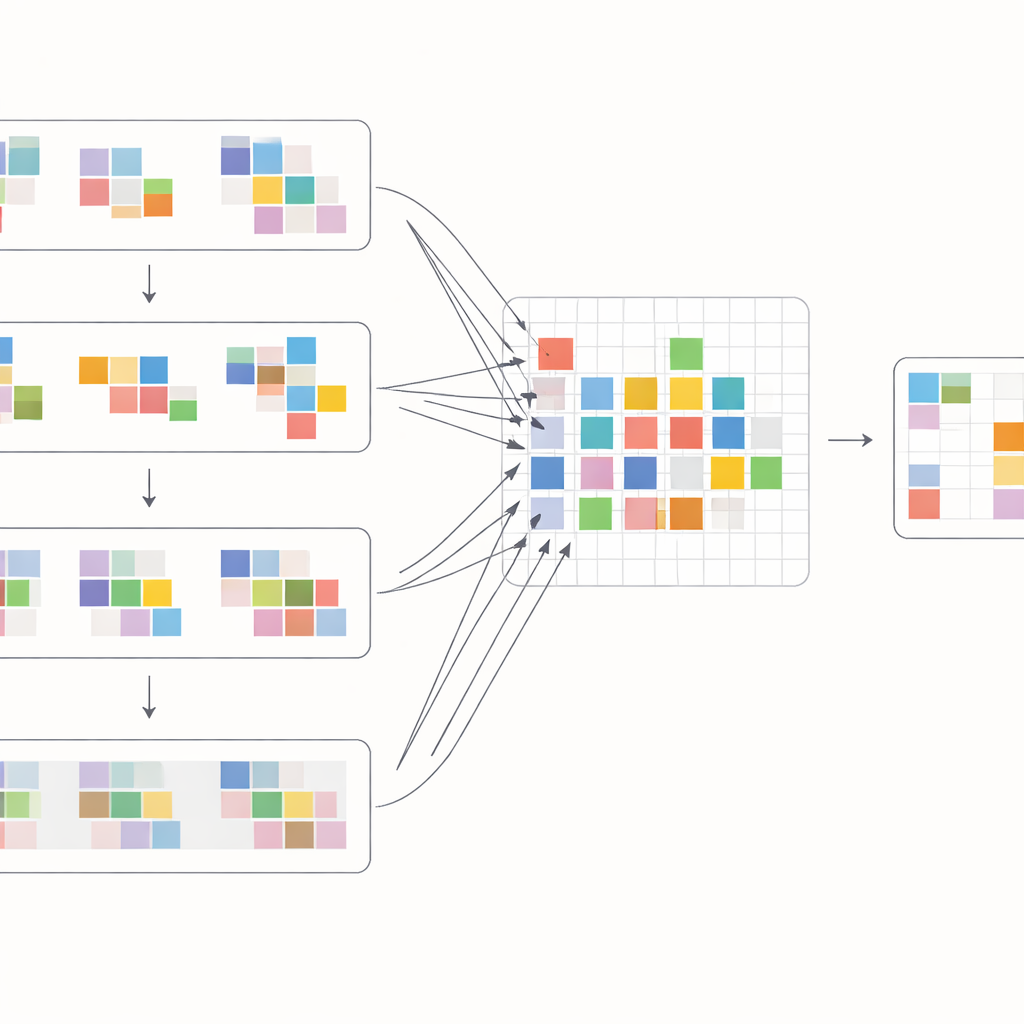
Jak dobrze to działa w praktyce
Badacze przetestowali swoje podejście na dwóch wymagających benchmarkach. Pierwszy obejmuje czyste wideo celowo zanieczyszczone różnymi poziomami losowego szumu, co pozwala dokładnie zmierzyć, jak bardzo przywrócone klatki odpowiadają oryginałom. W tym scenariuszu nowa metoda konsekwentnie dorównuje lub przewyższa jakość wcześniejszych sieci konwolucyjnych i rekurencyjnych, a także zbliża się do najlepszych istniejących modeli opartych na Transformerach, przy jednoczesnym mniejszym wykorzystaniu zasobów obliczeniowych. Drugi benchmark używa rzeczywistych nagrań zarejestrowanych przez czujniki obrazu przy słabym świetle, gdzie szum jest nierównomierny, kolorowy i znacznie mniej przewidywalny. W tym bardziej realistycznym teście Shift Alignment Transformer zdecydowanie przewyższa poprzednie metody, generując wideo, które wygląda czyściej, ostrzej i bardziej stabilnie w czasie, z mniejszą liczbą przesunięć kolorów i pozostałych artefaktów.
Co to oznacza dla przyszłych narzędzi wideo
Mówiąc prościej, autorzy pokazują, że można skutecznie odszumiać wideo bez jawnego śledzenia ruchu, łącząc inteligentne przesunięcia w czasie i przestrzeni z dopasowywaniem cech opartym na uwadze. Ich Shift Alignment Transformer oferuje silne wyważenie między dokładnością a wydajnością, szczególnie dla materiałów rzeczywistych nagrywanych przy słabym oświetleniu, gdzie tradycyjna estymacja ruchu jest podatna na błędy. Wraz z poprawą efektywności modeli opartych na uwadze, takie metody mogą trafić do codziennych aparatów i usług streamingowych, pomagając przekształcać zaszumione, trudne do oglądania nagrania w płynne, ostre filmy przy minimalnym wysiłku użytkownika.
Cytowanie: Zhang, X., Fan, S., Zhang, H. et al. SAT: shift alignment transformer for video denoising without flow estimation. Sci Rep 16, 8207 (2026). https://doi.org/10.1038/s41598-026-38431-9
Słowa kluczowe: odszumianie wideo, transformer, szum obrazu, wideo przy słabym oświetleniu, widzenie komputerowe