Clear Sky Science · pl
Efektywny zapytań atak decyzyjny typu adversarial z niskim budżetem zapytań
Dlaczego drobne zakłócenia w obrazach mogą zmylić inteligentne maszyny
Współczesna sztuczna inteligencja potrafi z imponującą dokładnością rozpoznawać twarze, zwierzęta i przedmioty codziennego użytku. Te same systemy da się jednak oszukać przez zmiany obrazu tak małe, że ludzie ledwie je dostrzegają. Artykuł przedstawia nowy sposób tworzenia takich „oszukujących” obrazów przy jak najmniejszej liczbie zapytań do modelu, ujawniając zarówno kruchość dzisiejszych modeli, jak i możliwości, które mogą wykorzystać atakujący w praktyce.
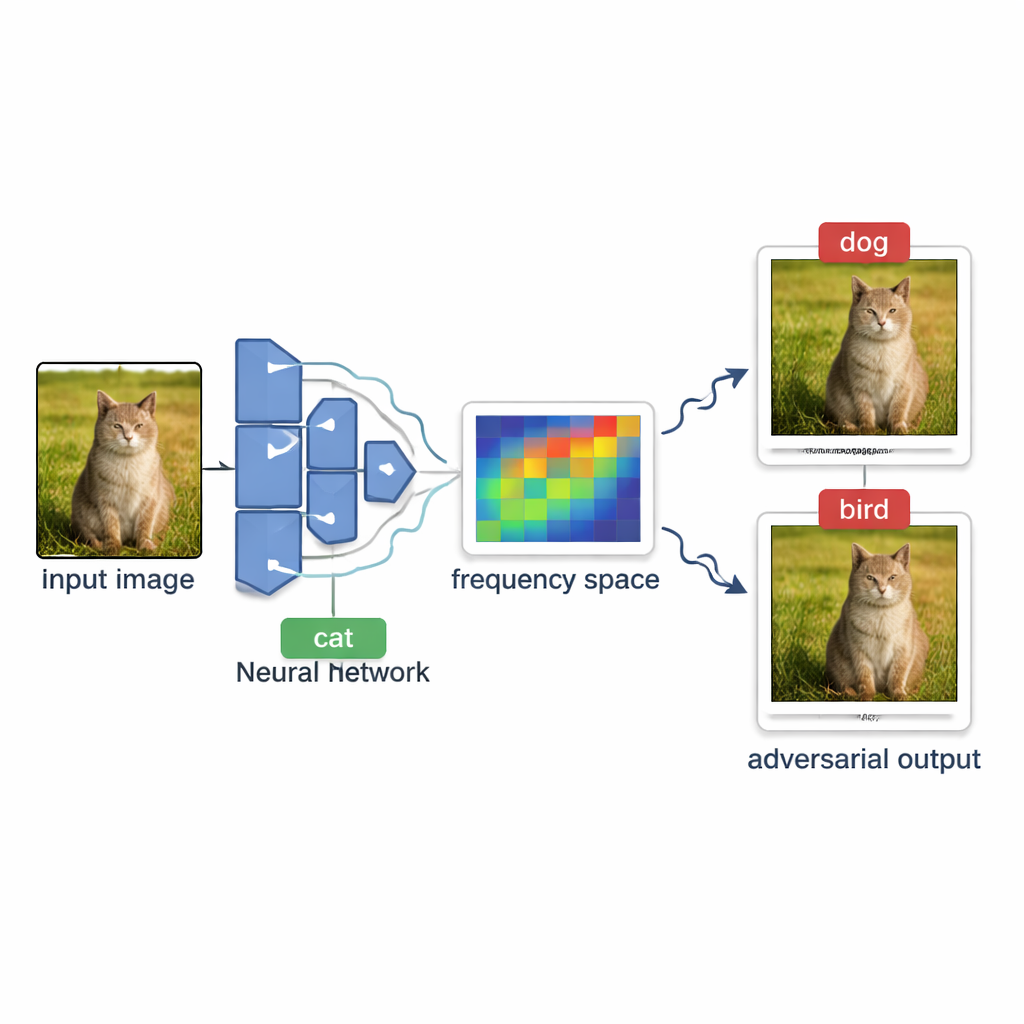
Jak atakujący badają systemy AI z zewnątrz
W wielu usługach — jak automatyczne tagowanie zdjęć czy filtry treści — model działa jak czarna skrzynka. Osoby z zewnątrz mogą przesłać obraz i zobaczyć jedynie końcową etykietę, np. „pies” lub „znak stop”, ale nie widzą wyników pośrednich ani struktury modelu. Tworzenie mylącego obrazu w takich warunkach nazywa się atakiem decyzyjnym typu black-box. Wyzwanie polega na tym, by delikatnie modyfikować zwykłe zdjęcie, aż model je błędnie sklasyfikuje, nie mając wglądu w to, jak „blisko” jest zmiany decyzji i nie wysyłając tylu zapytań, żeby system to zauważył lub by koszty zapytań stały się zbyt wysokie.
Nowy sposób przeszukiwania przy bardzo małej liczbie zapytań
Autorzy proponują OPOQA (One Plane One Query Attack), metodę zaprojektowaną tak, by oszczędzać zapytania przy jednoczesnym tworzeniu wysokiej jakości obrazów adversarial. Zamiast wielokrotnie sondować wzdłuż jednej przypuszczalnej kierunkowej zmiany, OPOQA działa w rundach. W każdej rundzie zaczyna od już mylącego obrazu i oryginalnego, czystego obrazu, a następnie proponuje kilka nowych kandydatów leżących w starannie dobranych kierunkach. Kluczowe jest to, że każdy kierunek jest badany co najwyżej raz, co pozwala lepiej wykorzystać ograniczony budżet zapytań do eksploracji większej liczby możliwości zamiast nadmiernego dopracowywania pojedynczego przypuszczenia.
Płynięcie po gładkich falach w obrazie
Aby wybierać obiecujące kierunki, OPOQA opiera się na pomyśle, że najbardziej efektywne, trudne do zauważenia zmiany są często gładkie i rozległe, a nie ostre, pikselowe szumy. Metoda wykorzystuje narzędzie matematyczne zwane dyskretną transformatą cosinusową, by przenieść obraz do widoku „częstotliwości”, gdzie powolne, łagodne wariacje skupiają się w zwartej części przestrzeni. Losowo próbuje kilku z tych składowych o niskich częstotliwościach, konwertuje je z powrotem na zwykłe zmiany pikseli i wykorzystuje jako podstawowe kierunki eksploracji. Każdy próbkowany kierunek pomaga zdefiniować płaszczyznę dwuwymiarową łączącą oryginalny obraz, bieżący obraz adversarial i nowego kandydata. Na każdej z tych płaszczyzn OPOQA wybiera pojedynczy punkt do przetestowania, równoważąc dwa cele: zbliżenie się do oryginalnego obrazu przy jednoczesnym dużym prawdopodobieństwie sprowadzenia modelu do błędnej decyzji.

Wybór najlepszego kandydata i adaptacja w locie
Gdy OPOQA wygeneruje niewielki zestaw kandydatów, mierzy ich odległość od obrazu oryginalnego i sortuje je od najmniej do najbardziej zmienionych. Następnie zadaje zapytania do modelu w tej kolejności. W chwili, gdy znajdzie kandydata, którego model błędnie klasyfikuje, przerywa i traktuje ten obraz jako punkt startowy dla kolejnej rundy. Jeśli żaden z kandydatów nie zdoła oszukać modelu, OPOQA zachowuje poprzedni najlepszy obraz adversarial, ale dostosowuje wewnętrzny parametr kontrolujący, jak konserwatywne lub agresywne będą następne kroki. Ta „chciwa” strategia — zawsze akceptowanie najlepszego dostępnego błędnie sklasyfikowanego obrazu i dynamiczne strojenie rozmiaru kroku — pozwala atakowi skupić się na subtelnych, skutecznych perturbacjach bez marnowania zapytań na nierokujące kierunki.
Co eksperymenty ujawniają o słabych punktach AI
Badacze przetestowali OPOQA na 200 obrazach z dużego zestawu ImageNet oraz na sześciu szeroko stosowanych modelach sieci neuronowych, w tym Inception-v3, ResNet, VGG, DenseNet i transformery wizji. Przy rygorystycznym limicie 1000 zapytań do modelu na obraz OPOQA dorównywała lub przewyższała kilka wiodących metod ataku. Na przykład dla Inception-v3 udało się oszukać model w 94 procentach przypadków, przy zachowaniu zmian tak małych, że były prawie niewidoczne dla ludzkiego oka, co stanowi poprawę o kilka punktów procentowych względem poprzednio najlepszej metody. W różnych modelach OPOQA miała tendencję do osiągania wysokich wskaźników sukcesu wcześniej — przy mniejszej liczbie zapytań — choć niektóre konkurencyjne metody doganiały lub przewyższały ją przy bardzo dużych budżetach zapytań i czasie na dopracowanie.
Co to oznacza dla codziennego bezpieczeństwa AI
Badanie pokazuje, że współczesne systemy wizji można oszukać nawet wtedy, gdy atakujący widzi tylko końcowe decyzje i ma ograniczone możliwości sondowania modelu. Dzięki sprytnej eksploracji łagodnych, niskoczęstotliwościowych zmian i ostrożnemu gospodarowaniu każdym zapytaniem, OPOQA potrafi tworzyć obrazy, które dla ludzi wyglądają identycznie, a dla maszyn prowadzą do poważnych błędów. Dla osób niebędących ekspertami wniosek jest taki, że „widzenie” przez AI jest wciąż kruche: da się je wyprowadzić z kursu w subtelny sposób, który trudno zauważyć. Rozpoznawanie i badanie takich efektywnych ataków to kluczowy krok w kierunku wzmacniania systemów rzeczywistych — jak kamery bezpieczeństwa, narzędzia do analizy obrazów medycznych czy pojazdy autonomiczne — przed manipulacjami, które inaczej pozostałyby niezauważone.
Cytowanie: Tuo, Y., Yin, M. & Che, S. Query-efficient decision-based adversarial attack with low query budget. Sci Rep 16, 6886 (2026). https://doi.org/10.1038/s41598-026-38428-4
Słowa kluczowe: przykłady adversarial, ataki black-box, bezpieczeństwo uczenia głębokiego, klasyfikacja obrazów, efektywny pod względem zapytań atak