Clear Sky Science · pl
MDI-YOLO — lekki model łączący transformery i CNN do wielowymiarowej fuzji cech w wykrywaniu małych obiektów
Ostre spojrzenie z nieba
Od monitorowania ruchu po reakcje kryzysowe — drony i satelity coraz częściej obserwują nasz świat. Tymczasem to, co w tych obrazach jest dla nas najważniejsze — maleńkie samochody, ludzie, łodzie czy samoloty — często pojawia się jako zaledwie kilka pikseli. Artykuł opisujący MDI‑YOLO zajmuje się prostym, lecz kluczowym pytaniem: jak komputery mogą niezawodnie wykrywać te drobne obiekty w czasie rzeczywistym, nawet na urządzeniach o ograniczonej mocy obliczeniowej noszonych przez same drony?
Dlaczego małe obiekty są trudne do wykrycia
W widokach z powietrza i ze satelity obiekty zainteresowania są zwykle bardzo małe, często ciasno skupione i częściowo zasłonięte przez budynki, drzewa czy cienie. Standardowe systemy wykrywania stoją przed kompromisem: lekkie modele działają szybko na urządzeniach brzegowych, takich jak komputery pokładowe dronów, ale przegapiają wiele małych celów; cięższe, dokładniejsze modele są z kolei zbyt wolne i zasobożerne, by były praktyczne w terenie. Małe obiekty łatwo też zlewają się z złożonym tłem — pomyśl o szarych samochodach na szarych drogach — więc ich charakterystyczne cechy mogą zniknąć w wyniku kompresji obrazu i przetwarzania przez głębokie sieci.
Nowe połączenie widzenia globalnego i lokalnego
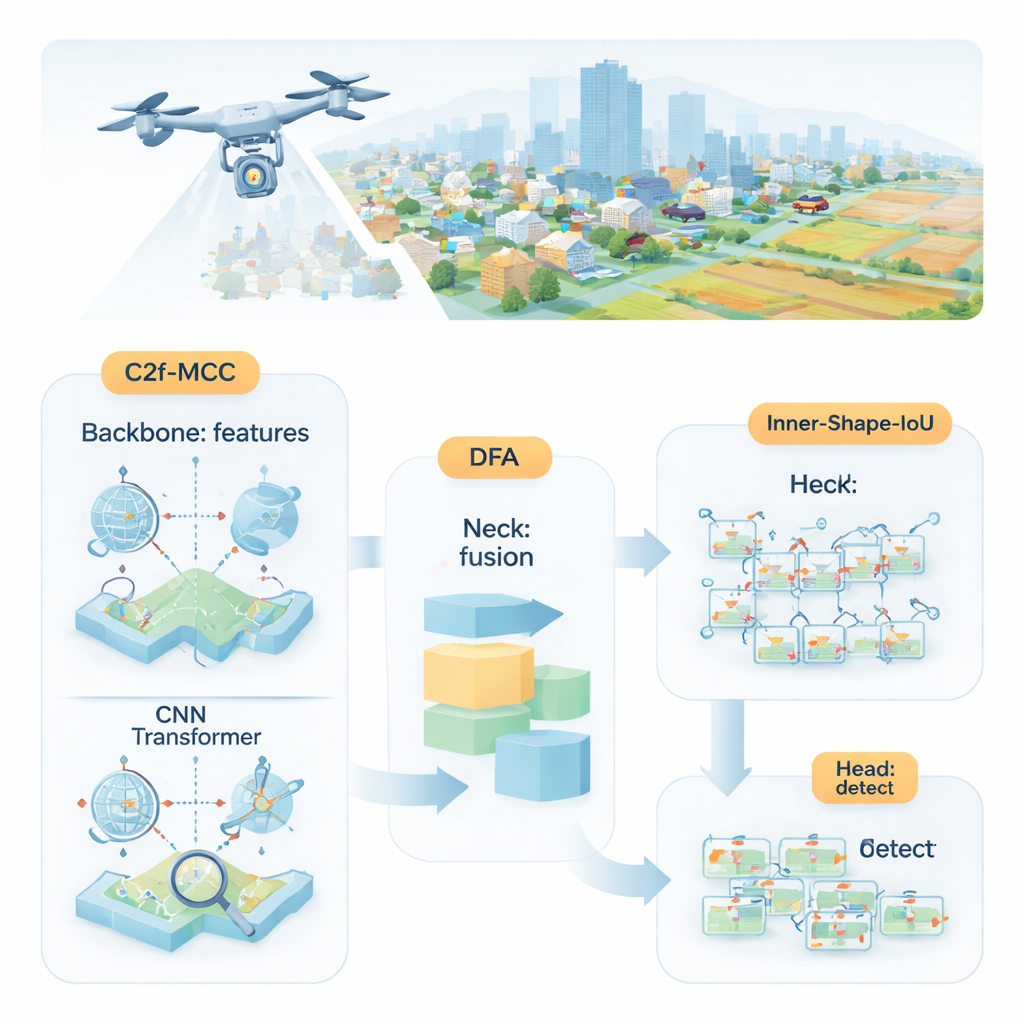
Naukowcy proponują MDI‑YOLO, przeprojektowaną wersję popularnego detektora YOLOv8, która utrzymuje model kompaktowym, a jednocześnie wyostrza jego zdolność do wykrywania drobnych celów. W centrum projektu znajduje się nowy blok konstrukcyjny nazwany C2f‑MCC, który dzieli przepływ informacji wizualnej przez sieć na dwie ścieżki. Jedna ścieżka wykorzystuje przetwarzanie w stylu transformera, które dobrze uchwyca długodystansowe relacje w całym obrazie — na przykład jak skupisko pikseli wpisuje się w większą drogę czy pas startowy. Druga ścieżka pozostaje przy klasycznych filtrach splotowych, które świetnie wydobywają lokalne detale, takie jak krawędzie i tekstury. Grupując kanały i przesyłając tylko część danych przez cięższą ścieżkę transformera, model zyskuje globalną świadomość bez wzrostu rozmiaru ani spadku prędkości działania.
Pomaganie sieci skupić się na tym, co ważne
Nawet przy lepszych blokach konstrukcyjnych sieć musi wciąż zdecydować, gdzie skupić uwagę. Aby to ułatwić, autorzy wprowadzają mechanizm nazwany Directional Fusion Attention (DFA). Moduł ten analizuje wzorce wzdłuż szerokości i wysokości obrazu, a także ogólne podsumowanie sceny, i uczy się, jak ważować różne regiony i kanały cech. W praktyce DFA zachęca model do koncentrowania się na obszarach prawdopodobnych do występowania obiektów — na przykład na plamach przypominających pojazdy na drogach — i do pomniejszania roli powtarzalnych lub mylących tekstur tła. To połączenie selekcji przestrzennej i kanałowej ułatwia oddzielenie drobnych celów od zagraconych otoczeń czy regionów tła o podobnym wyglądzie.
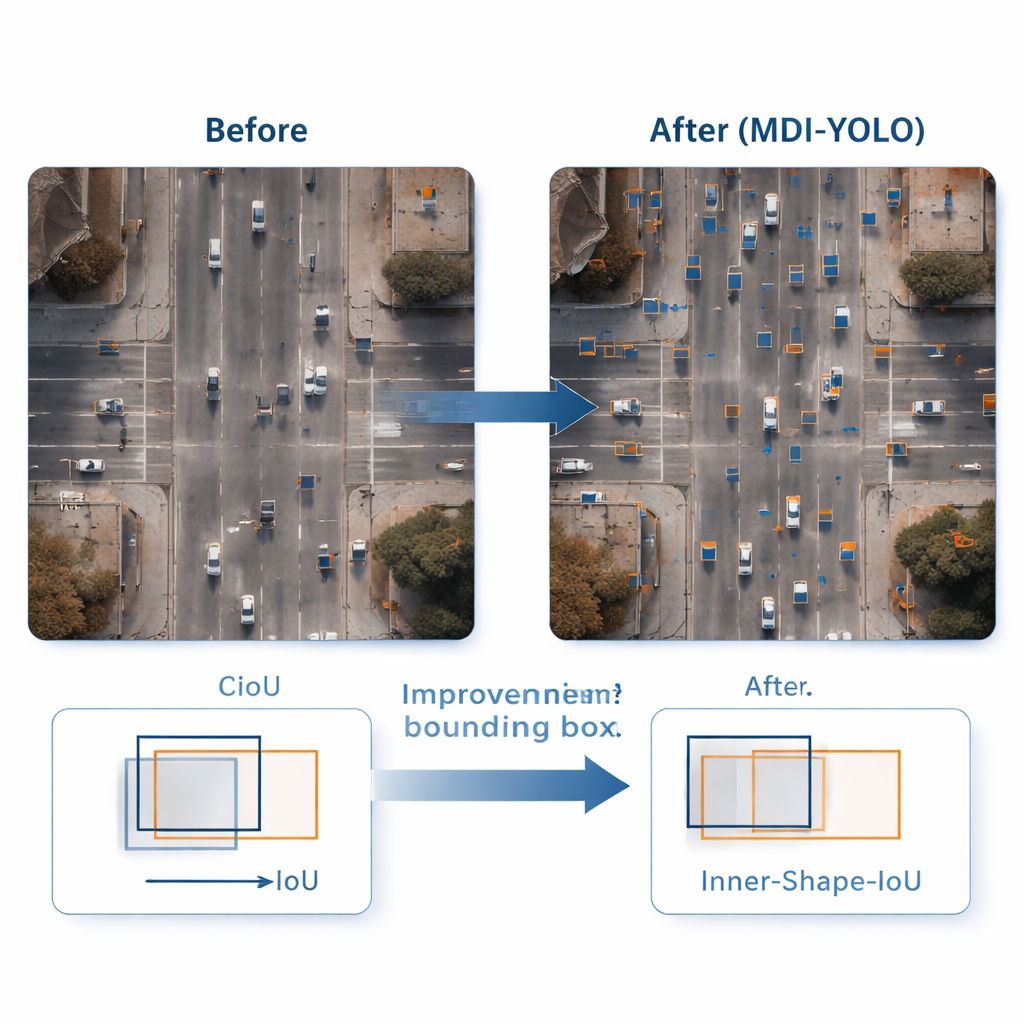
Precyzyjniejsze ramki wokół małych celów
Wykrycie obiektu to tylko połowa zadania; detektor musi też precyzyjnie go obrysować. Standardowe metody treningowe porównują przewidywane prostokąty z prawdziwymi przy użyciu współczynnika „nakładania się”, ale może on być mało czuły, gdy obiekty są małe lub mają nietypowy kształt. Autorzy zaprojektowali nową funkcję straty — Inner‑Shape‑IoU — która ocenia ramki nie tylko pod kątem stopnia nakładania, lecz także tego, jak dobrze ich kształt, rozmiar i obszar centralny pokrywają się z prawdziwym obiektem. Łącząc dwie uzupełniające się miary, karze ramki, które pasują jedynie krawędziami, a nie trafiają w rdzeń celu, co prowadzi do dokładniejszych obrysów — szczególnie dla małych, zatłoczonych lub wydłużonych obiektów.
Udowodnione korzyści bez dodatkowego balastu
Aby przetestować MDI‑YOLO, zespół przeprowadził eksperymenty na dwóch wymagających, publicznych benchmarkach: VisDrone2019, zawierającym nagrania z dronów miast i ruchu drogowego, oraz DOTAv1.0, dużej kolekcji scen lotniczych z wieloma małymi, gęsto rozmieszczonymi obiektami. Bez polegania na modelach wstępnie wytrenowanych, MDI‑YOLO poprawił standardowe wskaźniki dokładności o kilka punktów procentowych względem bazowego YOLOv8, zachowując prawie niezmienioną liczbę parametrów i utrzymując szybki czas inferencji. W porównaniu z szeregiem popularnych detektorów — od lekkich wariantów YOLO po cięższe systemy oparte na transformerach — oferował rzadkie połączenie wysokiej dokładności, niskich kosztów obliczeniowych i odporności w różnych scenach.
Co to oznacza w praktyce
Dla osób niebędących specjalistami najważniejszy wniosek jest taki, że MDI‑YOLO daje dronom i systemom teledetekcji ostrzejsze, bardziej niezawodne „oczy” bez konieczności stosowania dużych, energochłonnych komputerów. Poprzez inteligentne łączenie kontekstu globalnego, lokalnych detali, ukierunkowanej uwagi i bardziej wnikliwego sposobu trenowania ramek ograniczających, metoda ułatwia wykrywanie drobnych obiektów istotnych dla bezpieczeństwa, monitoringu i mapowania. Tego rodzaju wydajne, wysoko‑precyzyjne widzenie to kluczowy krok w kierunku bardziej zaawansowanych platform powietrznych, które mogą działać autonomicznie, szybko reagować i być szeroko wdrażane w realnym świecie.
Cytowanie: Shi, H., Wu, Y., Xu, Y. et al. MDI-YOLO a lightweight transformer-CNN-based multidimensional feature fusion model for small object detection. Sci Rep 16, 7233 (2026). https://doi.org/10.1038/s41598-026-38378-x
Słowa kluczowe: obrazowanie z dronów, wykrywanie małych obiektów, teledetekcja, YOLO, widzenie komputerowe