Clear Sky Science · pl
Przydział zasobów wspomagany przez cyfrowe bliźniaki za pomocą generatywnego uczenia przez naśladowanie w złożonych scenariuszach chmura‑krawędź‑urządzenie końcowe
Inteligentniejsze autostrady danych dla Internetu Rzeczy
W miarę jak miasta, fabryki i domy wypełniają się połączonymi czujnikami i urządzeniami, generują potoki danych, które trzeba przetwarzać szybko i niezawodnie. Wysyłanie wszystkiego do odległych serwerów chmurowych może być zbyt wolne, podczas gdy małe urządzenia na „krawędzi” często nie mają wystarczającej mocy obliczeniowej. W artykule przedstawiono nowy sposób automatycznego kierowania oraz przydzielania zasobów obliczeniowych, pamięci i sieci pomiędzy urządzeniami, pobliskimi serwerami edge i chmurą — tak aby inteligentne aplikacje działały szybko i stabilnie nawet wtedy, gdy warunki rzeczywiste są chaotyczne i nieprzewidywalne.
Dlaczego obecne metody mają trudności
Współczesne systemy często polegają na głębokim uczeniu ze wzmocnieniem, gdzie algorytm uczy się poprzez próbę i błąd, wykorzystując sygnały nagrody z otoczenia. W złożonych, zaszumionych sieciach te sygnały są jednak trudne do zdefiniowania i zmierzenia. Jeśli funkcja nagrody jest błędna lub zniekształcona przez zakłócenia, system może wyuczyć się zachowań niebezpiecznych lub marnotrawnych. Wiele istniejących metod zakłada też bogatą wiedzę wstępną o wzorcach ruchu i zachowaniu urządzeń, którą rzadko można uzyskać w działających sieciach przemysłowych. Na dodatek większość rozwiązań optymalizuje tylko jeden rodzaj zasobu naraz — na przykład moc obliczeniową — ignorując pamięć czy przepustowość sieci, mimo że wszystkie trzy współdziałają i decydują o rzeczywistej wydajności.
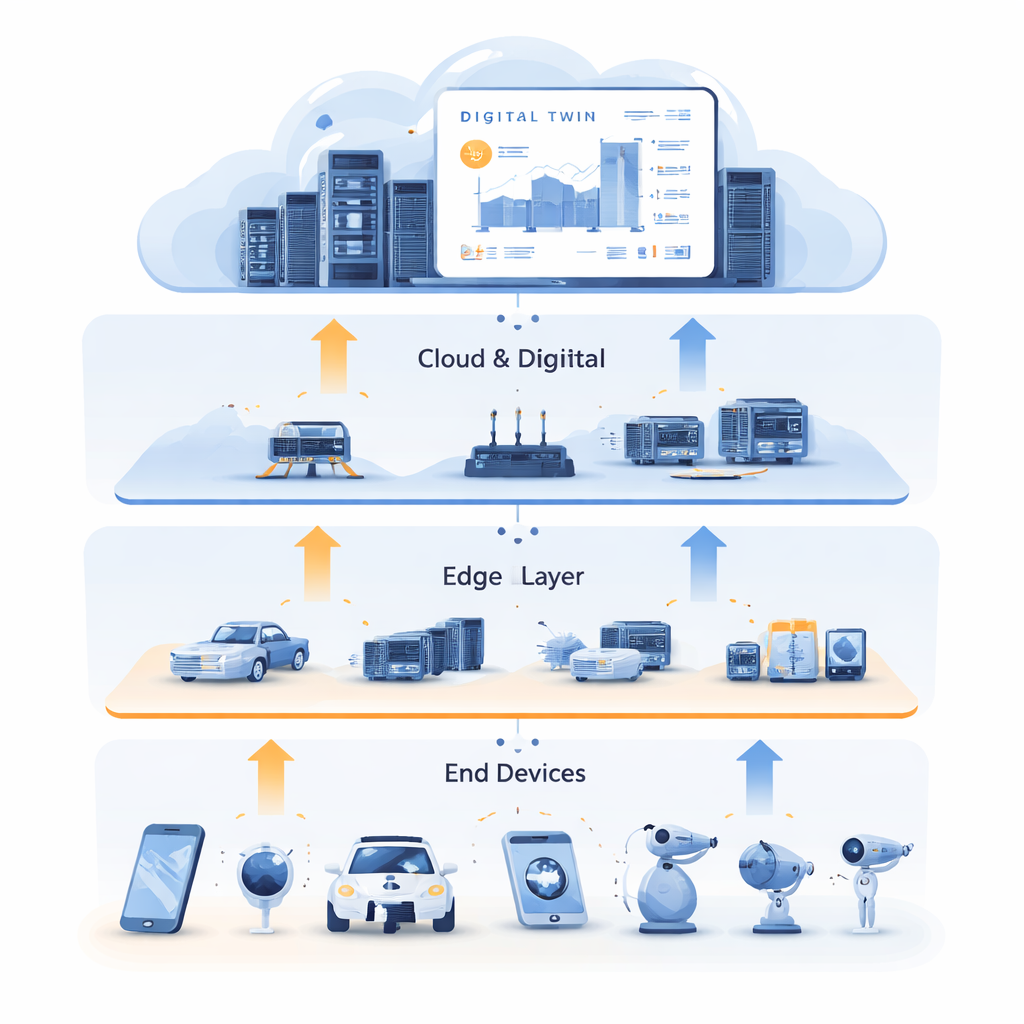
Uczenie się od cyfrowego sobowtóra
Aby przerwać ten impas, autorzy łączą przydział zasobów z technologią Cyfrowego Bliźniaka. Cyfrowy Bliźniak to szczegółowa wirtualna replika fizycznej sieci, utrzymywana w chmurze. Odzwierciedla stan serwerów edge, łączy i zadań w czasie, wykorzystując bogate historyczne dane z czujników i logów. W tym podejściu Cyfrowy Bliźniak to nie tylko panel monitorujący; staje się polem treningowym. System używa danych z przeszłości do generowania „eksperckich” przykładów dobrych decyzji, pokazujących, jak dzielić zadania między obliczenia a cache i gdzie je realizować, aby zminimalizować opóźnienia. Ten trening odbywa się offline, bez zakłócania usług na żywo, i wykorzystuje obfite zasoby obliczeniowe chmury do eksploracji wielu możliwych sytuacji.
Naśladownictwo zamiast próby i błędu
Zamiast uczyć się bezpośrednio z nagród, proponowany model E‑GAIL przyjmuje uczenie przez naśladowanie: agent stara się zachowywać jak ekspert. Najpierw autorzy tworzą wiele polityk eksperckich w ramach architektury Actor–Critic wzbogaconej warstwą NoisyNet. Wprowadzanie kontrolowanego hałasu do sieci decyzyjnej pozwala tym ekspertom doświadczyć szerokiego spektrum warunków — w tym zaburzeń imitujących rzeczywiste zakłócenia radiowe i zmienne obciążenia — dzięki czemu ich trajektorie są bardziej realistyczne. Następnie system łączy kilka trajektorii pojedynczych ekspertów w jedną referencyjną „multi‑ekspertową” trajektorię, wykorzystując narzędzia teorii gier. Poszukiwanie równowagi Nasha między ekspertami pozwala uniknąć konfliktów między nimi i wytworzyć strategię konsensusu obejmującą szerszy zakres możliwych scenariuszy.
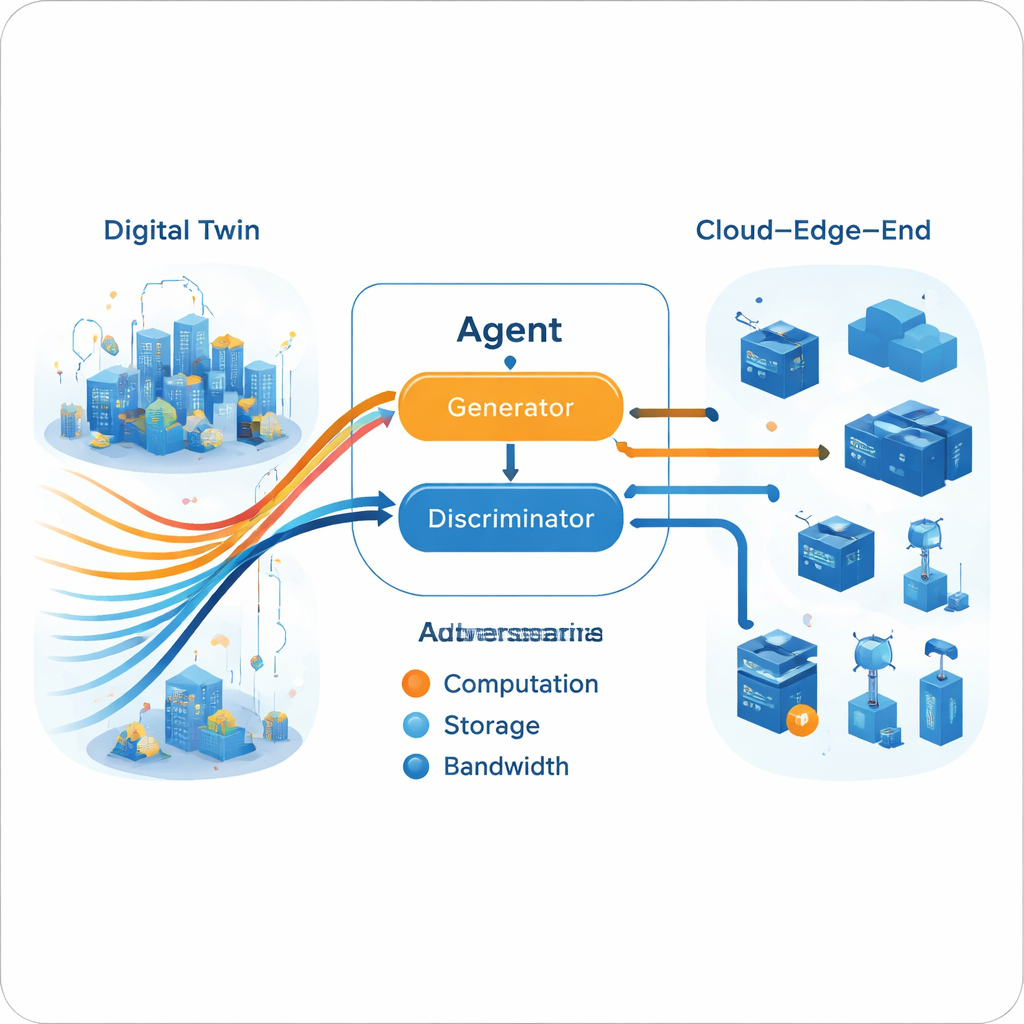
Generatywno‑adwersarialny silnik decyzji
Gdy multi‑ekspertowa trajektoria zostanie zbudowana w Cyfrowym Bliźniaku, agent działający na żywo uczy się ją naśladować w konfiguracji generatywno‑adwersarialnej, podobnej w duchu do sieci generujących obrazy. Generator proponuje działania przydziału zasobów na podstawie bieżącego stanu sieci, podczas gdy dyskryminator próbuje rozpoznać, czy sekwencja działań pochodzi od agenta, czy z trajektorii eksperckich. Z czasem ta adwersarialna gra zmusza generator do tworzenia decyzji, których dyskryminator nie potrafi odróżnić od zachowań ekspertów. Kluczowe jest to, że proces nie wymaga jawnej funkcji nagrody od środowiska rzeczywistego. Trening jest podzielony: ciężkie uczenie offline (w chmurze) dopracowuje ekspertów i generator, podczas gdy lżejsze aktualizacje online (na krawędzi) utrzymują model w zgodzie z bieżącymi warunkami, mieszcząc się w praktycznych ograniczeniach sprzętu edge.
Jak dobrze to działa?
Autorzy testują E‑GAIL przeciwko kilku popularnym bazom odniesienia, w tym głębokiemu Q‑learningowi, offloadingowi opartemu na teorii gier, zachłannym heurystykom, przetwarzaniu tylko w chmurze oraz losowemu przydziałowi. W wielu eksperymentach — przy zmieniającej się liczbie urządzeń końcowych, kanałów, mieszankach zadań, obciążeniach, rozmiarach danych, odległościach i wzorcach szumów — E‑GAIL konsekwentnie osiąga opóźnienia end‑to‑end bardzo bliskie tym z polityki eksperckiej i wyraźnie lepsze niż inne automatyczne metody. Dobrze adaptuje się, gdy zadania przesuwają się między obciążeniami obliczeniowymi a pamięciowymi, gdy sieć się rozrasta lub gdy nasilają się zakłócenia. Cyfrowy Bliźniak przyspiesza generowanie trajektorii eksperckich i poprawia ich jakość, podczas gdy fuzja multi‑ekspertów poszerza scenariusze, z którymi agent potrafi sobie poradzić bez konieczności ponownego pełnego treningu.
Co to oznacza dla systemów codziennego użytku
Dla nietechnicznego odbiorcy kluczowa wiadomość jest taka, że podejście to pozwala sieciom zarządzać sobą inteligentniej w obliczu niepewności. Zamiast ręcznie tworzyć reguły lub polegać na kruchej nauce przez próbę i błąd, E‑GAIL uczy się na podstawie bogatych, symulowanych doświadczeń dostarczonych przez Cyfrowego Bliźniaka i wielu doświadczonych „ekspertów”, których porady są pogodne matematycznie. Efektem jest mechanizm przydziału zasobów, który szybko decyduje, gdzie realizować zadania i gdzie przechowywać dane, utrzymując niskie czasy reakcji nawet w zmiennych warunkach. W przyszłych systemach przemysłowych i smart‑city takie samouczące się koordynatory mogłyby dyskretnie żonglować obliczeniami, pamięcią i przepustowością, czyniąc nasz połączony świat szybszym, bardziej niezawodnym i bardziej energooszczędnym.
Cytowanie: Zhang, X., Xin, M., Li, Y. et al. DT-aided resource allocation via generative adversarial imitation learning in complex cloud-edge-end scenarios. Sci Rep 16, 7657 (2026). https://doi.org/10.1038/s41598-026-38367-0
Słowa kluczowe: cyfrowy bliźniak, edge computing, uczenie przez naśladowanie, przydział zasobów, Przemysłowy Internet Rzeczy