Clear Sky Science · pl
Metoda fuzji ulepszania obrazów widzialnych i podczerwonych typu end-to-end w wielu skalach
Bardziej wyraźne widzenie nocne dla ludzi i maszyn
Każdy, kto próbował zrobić zdjęcie nocą, wie, jak szybko ciemność zabija szczegóły: sceny stają się ziarniste, rozmyte i pełne nienaturalnych barw. Tymczasem wiele krytycznych technologii — od kamer przy drogach i systemów bezpieczeństwa domowego po samochody autonomiczne i drony ratownicze — musi widzieć dokładnie w takich warunkach. W artykule przedstawiono nowy sposób łączenia zwykłych kolorowych kamer z kamerami na podczerwień („termowizyjnymi”), tak aby komputery, a ostatecznie także ludzie, mogły uzyskać jasne, szczegółowe obrazy świata nawet w warunkach niemal całkowitej ciemności.
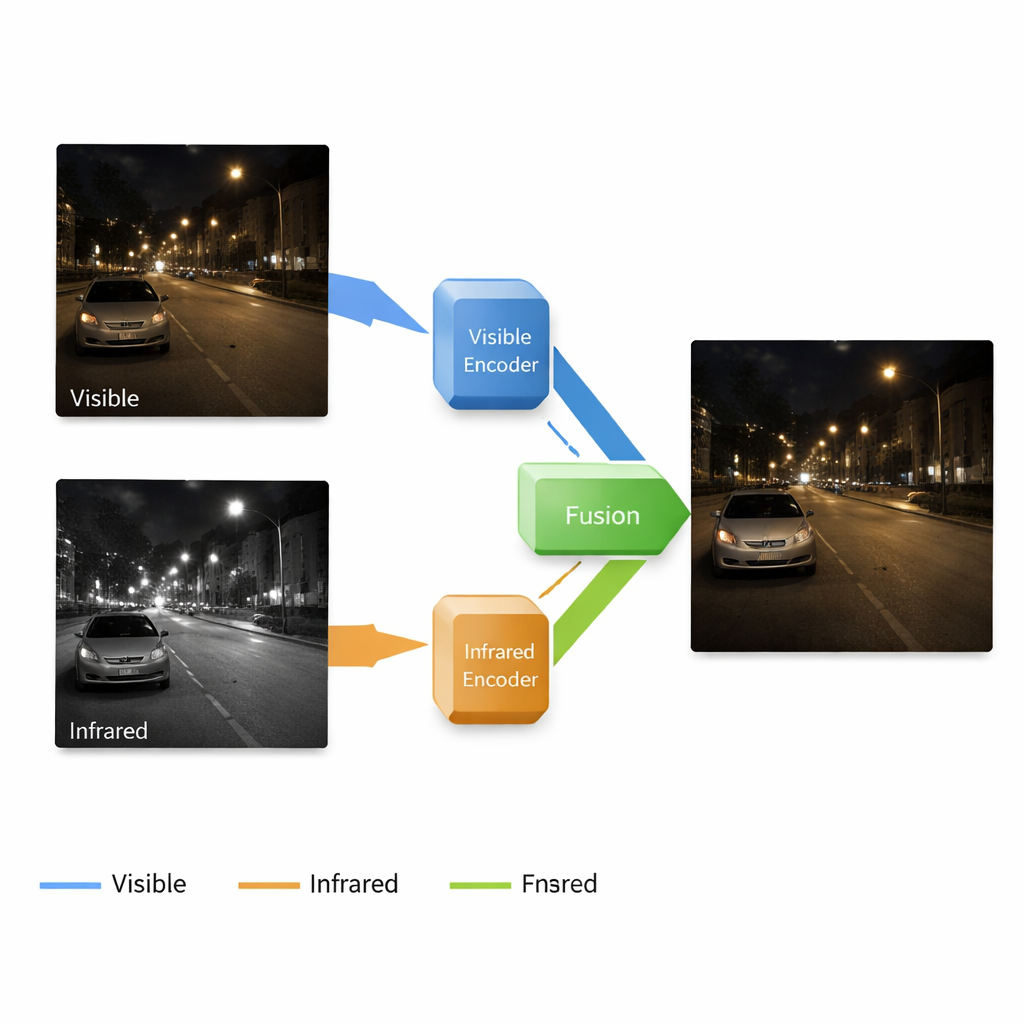
Dlaczego dwie kamery są lepsze niż jedna
Standardowe kamery rejestrują ten sam rodzaj światła, które widzimy oczami, dzięki czemu ich zdjęcia są łatwe do interpretacji dla ludzi, ale zawodzą, gdy światła brak: cienie pochłaniają szczegóły, pojawia się szum, a kolory się przesuwają. Kamery podczerwone działają odwrotnie: wykrywają wzory ciepła, ujawniając ludzi, zwierzęta i pojazdy w ciemności lub przez lekką mgłę, ale ich obrazy pozbawione są drobnych tekstur i naturalnego wyglądu. Badacze od dawna starają się połączyć te dwa widoki w pojedynczy obraz, który wyglądałby jak wyraźne zdjęcie kolorowe, a jednocześnie ujawniał ukryte, ciepłe obiekty. Istniejące metody często jednak traktują każdy etap — rozjaśnianie ciemnych obrazów, usuwanie szumu i włączanie informacji z podczerwieni — jako oddzielne zadania. Taki fragmentaryczny sposób może prowadzić do niezgodnych cech i niezadowalających wyników fuzji.
Jedna linia przetwarzania, która jednocześnie rozjaśnia i scala
Autorzy proponują system end-to-end, który jednocześnie poprawia i fuzjonuje obrazy w jednym ciągłym potoku. Opiera się on na sieci neuronowej z czterema głównymi elementami: jedna gałąź uczy się oczyszczać i rozjaśniać kolorowe zdjęcia przy słabym świetle, druga uczy się reprezentować scenę z kamery podczerwonej, blok fuzji łączy to, czego nauczyły się obie gałęzie, a dekoder rekonstruuje finalny obraz z tych zmieszanych sygnałów. Istotne jest to, że system działa w wielu skalach, od ogólnych kształtów po drobne tekstury. Płytkie warstwy zachowują krawędzie i detale powierzchni, takie jak cegły czy oznakowanie drogowe, podczas gdy głębsze warstwy wychwytują szersze struktury — budynki, samochody czy drzewa — oraz położenie ciepłych obiektów na obrazie z podczerwieni.
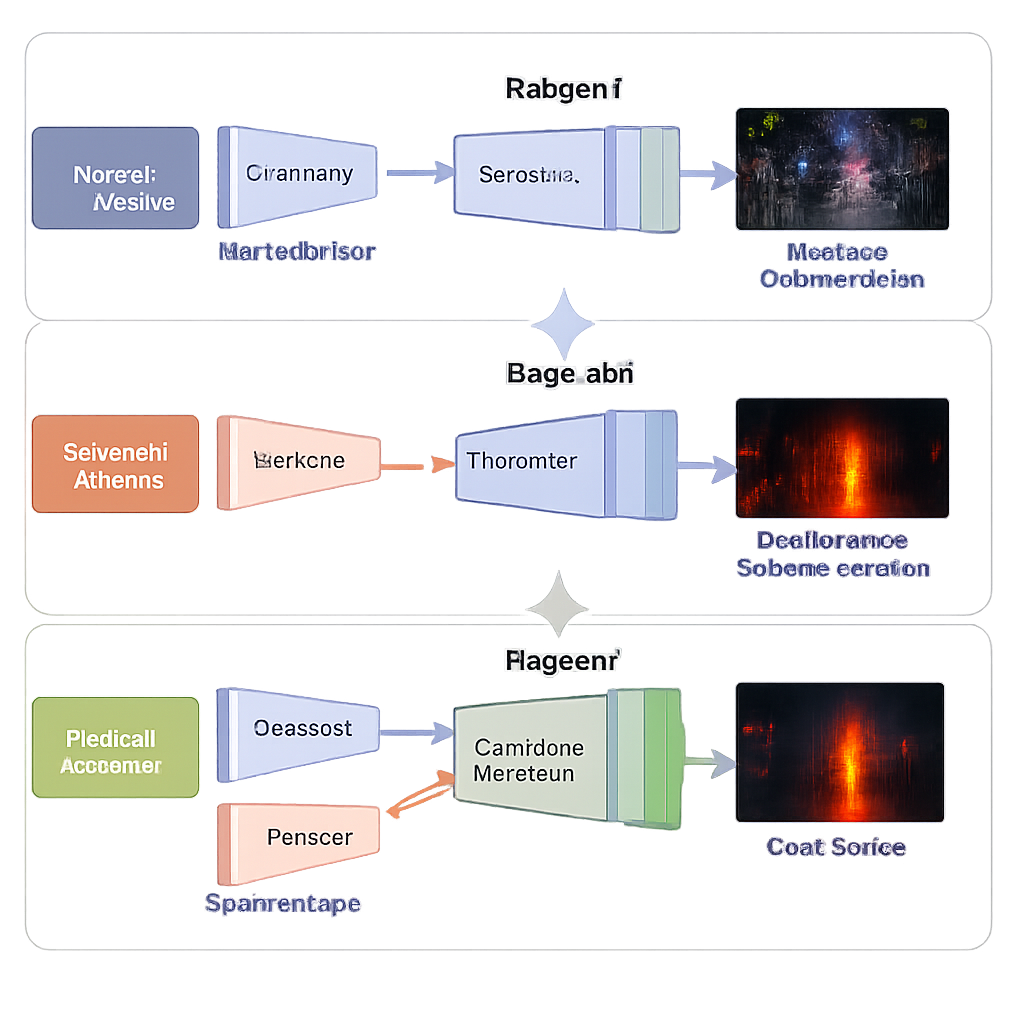
Trzy fazy uczenia zamiast jednego dużego skoku
Zamiast trenować cały system naraz, zespół stosuje strategię uczenia w trzech etapach zaprojektowaną pod kątem stabilności i dokładności. W pierwszym etapie sieć widzi tylko ciemne zdjęcia w świetle widzialnym i uczy się je rozjaśniać bez jakichkolwiek „idealnych” wzorców dostarczanych przez człowieka. Starannie dobrane funkcje straty popychają wynik w stronę naturalnej jasności, stabilnych kolorów, gładkich obszarów bez plamistego szumu i zachowanej tekstury. W drugim etapie ten sam dekoder jest ponownie wykorzystywany, podczas gdy nowa gałąź podczerwieni uczy się wiernie rekonstruować obrazy termalne, ucząc sieć, jak powinny wyglądać wzory ciepła. W trzecim etapie wszystkie te nauczone części zostają zamrożone, a trenowany jest jedynie blok fuzji, aby połączyć dwie reprezentacje w jeden, wysokiej jakości obraz, który jest jednocześnie jasny i bogaty informacyjnie.
Testy metody
Badacze ocenili swoje podejście na publicznych zbiorach danych zawierających sparowane obrazy widzialne i podczerwone wykonane w trudnych warunkach oświetleniowych, takich jak nocne ulice. Porównali je z kilkoma wiodącymi technikami fuzji, w tym opartymi na klasycznych przekształceniach obrazów, standardowych sieciach konwolucyjnych i bardziej złożonych modelach generatywnych. Ich metoda zazwyczaj dostarczała ostrzejsze detale, bardziej równomierne oświetlenie i wyraźniejsze cele termiczne, a także osiągała wyższe wyniki w miarach ilościowych takich jak zawartość informacji, ostrość krawędzi, podobieństwo strukturalne i kontrast. Dodatkowe eksperymenty, w których selektywnie usuwano kluczowe komponenty systemu, wykazały, że każda część — blok fuzji wieloskalowej, etapowe szkolenie i adaptacyjne ważenie cech widzialnych wobec podczerwonych — wnosi mierzalny wkład w ostateczną jakość.
Co to oznacza dla systemów widzenia w praktyce
Dla osób niebędących specjalistami w uproszczeniu: wniosek jest prosty — praca pokazuje, że jedna starannie wytrenowana sieć może jednocześnie rozjaśniać ciemne sceny i inteligentnie łączyć widoki termalne i kolorowe w jeden spójny obraz. Zespolone obrazy zachowują drobne tekstury, jednocześnie uwypuklając ciepłe obiekty, co czyni je znacznie bardziej użytecznymi do zadań takich jak nadzór nocny, wspomaganie jazdy czy rzeczywistość rozszerzona bądź wirtualna w przyćmionych środowiskach. Chociaż autorzy zauważają pewne pozostałe problemy — takie jak obniżony kontrast w bardzo jasnych obszarach i potrzeba szybszych, lżejszych modeli — ich podejście stanowi istotny krok w kierunku systemów kamer, które widzą niezawodnie po zmroku, w sposób naturalny i zrozumiały dla użytkowników.
Cytowanie: Xin, Y., Huang, J., Sun, C. et al. A multi-scale end-to-end visible and infrared image enhancement fusion method. Sci Rep 16, 7135 (2026). https://doi.org/10.1038/s41598-026-38323-y
Słowa kluczowe: ulepszanie obrazów przy słabym świetle, fuzja obrazów podczerwonych, widzenie nocne, obrazowanie wieloczujnikowe, wizja głębokiego uczenia