Clear Sky Science · pl
Przycinanie lasu drzew i ponowne próbkowanie dla problemu niezrównoważonych klas
Dlaczego rzadkie przypadki mają znaczenie w inteligentnych predykcjach
Wiele decyzji wspieranych przez sztuczną inteligencję opiera się na wykryciu rzadkiego zdarzenia: oszukańczej transakcji kartą, wczesnego sygnału choroby lub niebezpiecznej usterki maszyny. W takich sytuacjach istotne przypadki są znacznie mniej liczne niż zwykłe, a większość algorytmów uczących ma tendencję do ich pomijania. W artykule przedstawiono sposób, by sprawić, że jedna z popularnych metod, Random Forest, zwróci znacznie więcej uwagi na te rzadkie, ale kluczowe przypadki — jednocześnie czyniąc model smuklejszym i szybszym.
Problem nierównomiernych przykładów
Standardowe uczenie maszynowe działa najlepiej, gdy dane są dobrze zbalansowane — kiedy liczba przykładów dla każdego wyniku jest mniej więcej podobna. W rzeczywistości jednak wiele zadań dotyczy rzadkich zdarzeń. Na przykład tylko niewielka część badań obrazowych pokazuje guz, a tylko drobny odsetek transakcji jest oszustwem. Taka nierównowaga sprawia, że algorytm może wyglądać dobrze na papierze, przewidując przeważnie wynik dominujący, nawet jeśli wielokrotnie nie wykrywa rzadkiego przypadku. W miarę powiększania się różnicy między klasami dominującą i rzadką, granica decyzyjna modelu przesuwa się w stronę większości, a klasa rzadka staje się trudniejsza do rozpoznania.
Wyrównywanie skali za pomocą inteligentnego próbkowania
Naukowcy często próbują przywrócić równowagę danych przed trenowaniem modeli. Jedną opcją jest przycięcie klasy większościowej (under-sampling), wyrzucając część powszechnych przypadków, aby dopasować ich liczbę do rzadkich. Inną jest skopiowanie lub wygenerowanie dodatkowych rzadkich przykładów (over-sampling), zwiększając ich udział bez utraty oryginalnych danych. Trzecie, hybrydowe podejście łączy oba pomysły, redukując część przykładów większościowych i jednocześnie uzupełniając mniejszość. Każda taktyka ma swoje kompromisy: przycinanie może pozbawić model przydatnej informacji, podczas gdy duplikowanie przykładów może spowolnić trening i sprzyjać przeuczeniu. Autorzy korzystają ze wszystkich trzech strategii, aby stworzyć bardziej zrównoważone zbiory treningowe dopasowane do konkretnych danych.
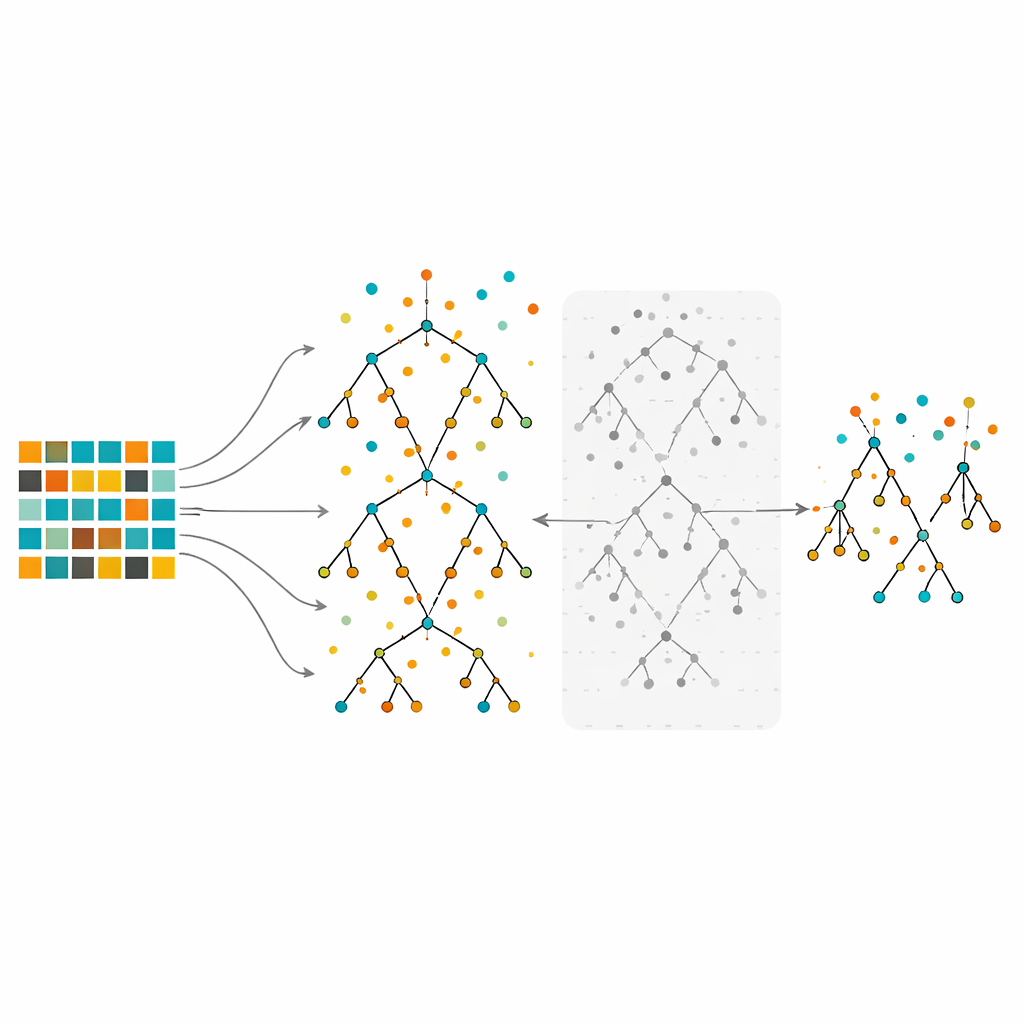
Nauczanie i przycinanie lasu drzew decyzyjnych
Badanie koncentruje się na Random Forest, metodzie zespołowej, która buduje wiele drzew decyzyjnych na nieco różnych wycinkach danych, a następnie łączy ich głosy. Random Forest jest znany z radzenia sobie ze złożonymi danymi i wskazywania, które cechy są najważniejsze. Jednak trenowany na silnie niezrównoważonych danych nawet duży las może faworyzować klasę większościową. W proponowanej metodzie autorzy najpierw przywracają równowagę danych przy użyciu under-samplingu, over-samplingu lub podejścia hybrydowego. Następnie rosną wiele drzew zgodnie z zwykłą procedurą Random Forest, ale z istotnym dodatkiem: zamiast zachowywać każde drzewo, oceniają je przy pomocy obserwacji out-of-bag — punktów danych, które nie zostały użyte do wyroszenia danego drzewa — i odrzucają połowę drzew o najgorszych wskaźnikach błędu. Ten krok przycinania daje mniejszy, bardziej selektywny las zbudowany z najbardziej wiarygodnych drzew.
Testowanie na wielu zbiorach danych z rzeczywistego świata
Aby ocenić skuteczność przyciętego lasu, autorzy przetestowali go na dziesięciu publicznie dostępnych zbiorach danych odzwierciedlających szerokie zastosowania — od pomiarów medycznych i biologicznych po filtrowanie spamu w poczcie i klasyfikację dźwięków. Każdy zbiór ma dwie klasy, z jedną wyraźnie rzadszą niż druga, i różnią się rozmiarem, liczbą cech oraz stopniem nierównowagi. Nowa metoda została porównana z kilkoma powszechnie stosowanymi podejściami: k-najbliższych sąsiadów, pojedynczym drzewem decyzyjnym, standardowym Random Forest, wariantem Balanced Random Forest oraz maszynami wektorów nośnych. W zależności od strategii próbkowania przycięty las konsekwentnie osiągał niższy błąd klasyfikacji niż alternatywy w większości zbiorów. Połączenie próbkowania hybrydowego z przycinaniem dawało najlepsze wyniki ogólne — zarówno pod względem dokładności, jak i stabilności wydajności we wszystkich dziesięciu zadaniach.
Ostre modele, które marnują mniej zasobów
Poza dokładnością podejście poprawia też efektywność. Poprzez usunięcie mniej skutecznych drzew końcowy zespół jest mniejszy i wymaga mniej obliczeń podczas trenowania i prognozowania, nie tracąc — a często zwiększając — zdolność do wykrywania rzadkich przypadków. Testy statystyczne potwierdzają, że przewagi nad konkurencyjnymi metodami nie wynikają z przypadku. Dla praktyków pracujących z niezrównoważonymi danymi praca ta pokazuje, że staranne zbalansowanie zbioru treningowego, a następnie przycięcie Random Forest na podstawie wydajności out-of-bag może dać modele zarówno bardziej dokładne, jak i bardziej wydajne. Mówiąc prościej, metoda pomaga naszym algorytmom zwracać należytą uwagę na rzadkie, ale ważne sygnały ukryte w morzu zwykłych przykładów.
Cytowanie: Faiz, N., Iftikhar, S., Jan, S. et al. Pruning tree forest and re-sampling for class imbalanced problem. Sci Rep 16, 8087 (2026). https://doi.org/10.1038/s41598-026-38320-1
Słowa kluczowe: nierównowaga klas, random forest, ponowne próbkowanie, uczenie maszynowe, metody zespołowe