Clear Sky Science · pl
Uczenie federacyjne dla heterogenicznych systemów elektronicznych kart zdrowia z efektywnym kosztowo wyborem uczestników
Dlaczego udostępnianie danych szpitalnych jest tak trudne
Współczesne szpitale gromadzą ogromne ilości informacji cyfrowych o pacjentach — od badań laboratoryjnych i parametrów życiowych po leki i zabiegi. W teorii łączenie tych zapisów z wielu placówek pozwoliłoby lekarzom tworzyć lepsze modele komputerowe przewidujące ryzyko lub wskazujące najbardziej obiecujące terapie. W praktyce jednak szpitale używają różnych systemów informatycznych, przechowują dane w niekompatybilnych formatach i muszą rygorystycznie chronić prywatność pacjentów oraz swoje budżety. W badaniu tym autorzy badają, jak pozwolić szpitalom uczyć się nawzajem bez kopiowania danych i bez nadmiernych wydatków.
Wspólne trenowanie bez udostępniania surowych zapisów
Autorzy opierają się na podejściu zwanym uczeniem federacyjnym, gdzie każdy szpital trenuje lokalny model na własnych danych pacjentów, a następnie udostępnia tylko aktualizacje modelu, nie surowe dane. Centralny „gospodarz” koordynuje ten proces i dąży do ulepszenia modelu predykcyjnego dla własnych potrzeb, na przykład prognozowania powikłań na oddziale intensywnej terapii. Inne szpitale, zwane podmiotami, uczestniczą w zamian za wynagrodzenie. Takie rozwiązanie unika przesyłania wrażliwych rekordów między instytucjami, ale rodzi dwa trudne pytania: jak radzić sobie z wieloma różnymi systemami zapisu oraz jak unikać płacenia partnerom, którzy tak naprawdę nie pomagają modelowi.
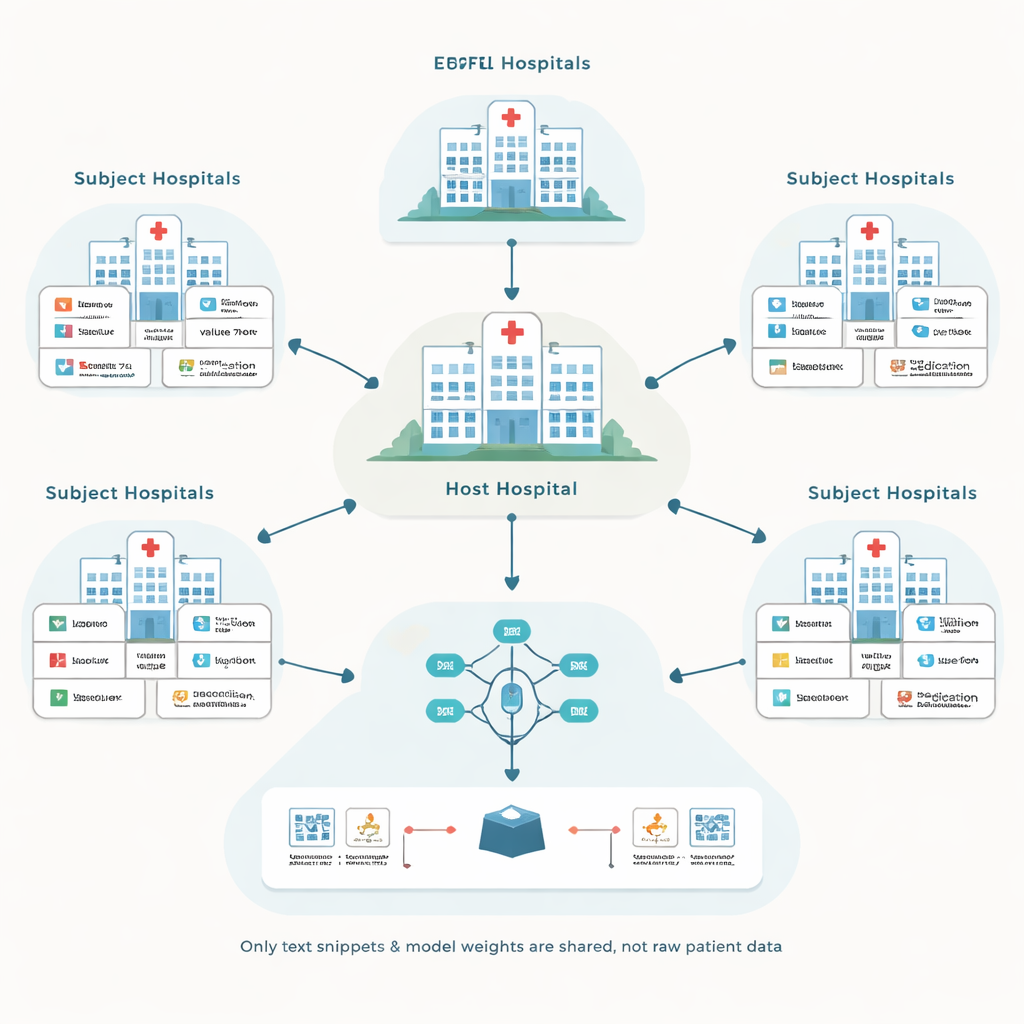
Przekształcanie nieuporządkowanych zapisów w wspólny język
Systemy elektronicznych kart zdrowia bardzo różnią się sposobem oznaczania i kodowania informacji. Jeden szpital może przechowywać wynik glukozy jako pewien kod liczbowy, podczas gdy inny użyje innego kodu dla tego samego badania. Tradycyjne rozwiązania próbują przekonwertować wszystko do jednego, starannie zaprojektowanego standardu, co jest kosztowne i wymaga wielu godzin pracy ekspertów. Zamiast tego proponowane rozwiązanie, nazwane EHRFL, przekształca każde zdarzenie medyczne w krótki fragment tekstu. Na przykład wpis z laboratorium dotyczący pomiaru glukozy staje się frazą typu „zdarzenie laboratoryjne glukoza wartość 70 mg/dL”. Ponieważ każdy szpital posiada już słowniki mapujące lokalne kody na czytelne nazwy, tę konwersję można zautomatyzować bez ręcznego dostrajania.
Budowanie profili pacjentów z tekstu
Gdy zdarzenia są zapisane jako tekst, EHRFL wykorzystuje nowoczesne modele przetwarzania języka, aby zamienić każde zdarzenie na wektor numeryczny, a następnie łączy wiele zdarzeń w pojedyncze „osadzenie pacjenta” — zwarty opis historii medycznej danej osoby w określonym przedziale czasu. Te osadzenia trafiają do warstwy predykcyjnej, która jednocześnie rozwiązuje kilka zadań klinicznych, takich jak prognozowanie śmierci w szpitalu czy uszkodzenia nerek po przyjęciu na intensywną terapię. Autorzy przeprowadzili uczenie federacyjne na pięciu dużych, rzeczywistych zbiorach danych z opieki krytycznej, obejmujących różne szpitale, okresy i systemy rejestracji. We wszystkich testowanych algorytmach, w tym powszechnie stosowanych metodach federacyjnych, modele trenowane z użyciem tego podejścia tekstowego konsekwentnie przewyższały modele szkolone wyłącznie na danych pojedynczego szpitala, mimo różnic w formatach danych.
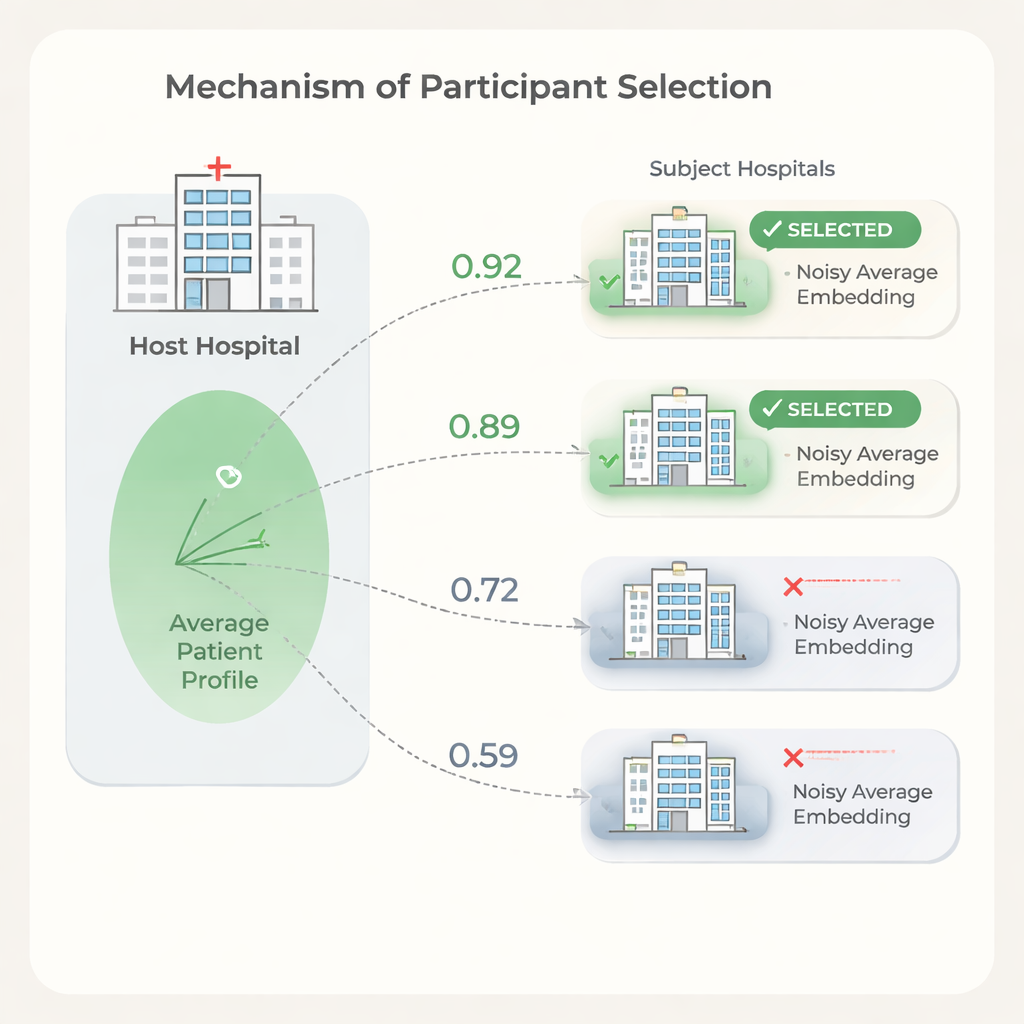
Wybór właściwych partnerów przy ochronie prywatności
Więcej szpitali nie zawsze oznacza lepsze wyniki. Niektóre placówki mają populacje pacjentów lub wzorce zapisu tak różne od gospodarza, że ich uwzględnienie może spowolnić trening lub nieznacznie pogorszyć wydajność, przy jednoczesnym wzroście kosztów. Aby temu zaradzić, autorzy proponują etap selekcji oparty na podobieństwie osadzeń pacjentów między szpitalami. Gospodarz najpierw trenuje model na własnych danych, udostępnia wagi modelu, a każdy kandydat używa ich do obliczenia osadzeń pacjentów. W celu ochrony prywatności każdy podmiot obcina skrajne wartości w swoich osadzeniach, uśrednia je do pojedynczego wektora, a następnie dodaje starannie skalibrowany szum losowy, zanim wyśle tylko tę zaszumioną średnią do gospodarza. Gospodarz porównuje swoją własną średnią z każdą średnią podmiotu przy użyciu prostych miar podobieństwa i wybiera tylko najbardziej podobne szpitale do pełnego, federacyjnego treningu.
Oszczędzanie pieniędzy bez utraty dokładności
Eksperymenty pokazują, że podobieństwo między średnimi osadzeniami pacjentów szpitali koreluje z tym, na ile dany szpital pomaga lub szkodzi wydajności predykcyjnej gospodarza. Wykorzystując ten sygnał do wyboru partnerów, gospodarz może odrzucić szpitale o niskim podobieństwie, jednocześnie zachowując lub nawet poprawiając jakość predykcji w porównaniu z użyciem wszystkich dostępnych placówek. Autorzy przedstawiają również model kosztów, pokazując, że ze względu na to, iż opłaty za korzystanie z danych i czas treningu rosną wraz z liczbą uczestniczących szpitali, nawet umiarkowane ograniczenie liczby partnerów może przynieść znaczne oszczędności. Jednocześnie etap selekcji jest lekki: model trenuje się raz, a każdy szpital wykonuje tylko proste obliczenia na pojedynczym uśrednionym wektorze.
Co to oznacza dla przyszłej AI w opiece zdrowotnej
Dla czytelników spoza dziedziny kluczowy wniosek jest taki, że szpitale mogą „uczyć się razem” bez łączenia surowych rekordów pacjentów, i robić to w sposób szanujący prywatność oraz ograniczenia budżetowe. Poprzez przetłumaczenie zróżnicowanych zapisów na wspólną formę tekstową, a następnie użycie podsumowań populacji pacjentów zabezpieczonych pod względem prywatności do wyboru kompatybilnych partnerów, EHRFL oferuje praktyczną receptę na budowanie modeli predykcyjnych dostosowanych do konkretnego szpitala. Choć badanie koncentruje się na danych z intensywnej opieki, te same pomysły można rozszerzyć na przychodnie ambulatoryjne, izby przyjęć, a nawet poza obszar medyczny tam, gdzie organizacje chcą współpracować nad lepszymi modelami bez rezygnacji z kontroli nad swoimi danymi.
Cytowanie: Kim, J., Kim, J., Hur, K. et al. Federated learning for heterogeneous electronic health record systems with cost effective participant selection. Sci Rep 16, 6876 (2026). https://doi.org/10.1038/s41598-026-38299-9
Słowa kluczowe: uczenie federacyjne, elektroniczne rekordy zdrowotne, prywatność pacjenta, predykcja kliniczna, sztuczna inteligencja w ochronie zdrowia