Clear Sky Science · pl
NeuroAction: neuroewolucyjne podejście do uczenia ze wzmocnieniem dla pojazdów autonomicznych
Dlaczego ważne są mądrzejsze style prowadzenia
Większość z nas wyobraża sobie samochody autonomiczne jako spokojnych, perfekcyjnie racjonalnych kierowców. Jednak dzisiejsze systemy zwykle dążą do jednego, stałego zestawu celów — na przykład unikania kolizji przy jednoczesnym szybkim dotarciu do celu — a ten balans jest ustalany przez inżynierów. NeuroAction, podejście opisane w tym artykule, ma na celu przybliżenie autonomicznych samochodów do ludzkiej elastyczności: możliwość wyboru spośród wielu bezpiecznych stylów jazdy, od ostrożnego „dziecko na pokładzie” po żwawą jazdę autostradową, bez potrzeby każdorazowego trenowania pojazdu na nowo.
Od uniwersalnych ustawień do wielu bezpiecznych opcji
Obecne systemy głębokiego uczenia ze wzmocnieniem do prowadzenia uczą się przez próbę i błąd: obserwują drogę, podejmują działania, takie jak skręt i przyspieszanie, i otrzymują pojedynczą wartościową nagrodę, która łączy różne cele, np. prędkość, bezpieczeństwo i pozycję w pasie. Aby dostosować system, inżynierowie muszą starannie zaprojektować tę jedną nagrodę. Jeśli nadmiernie podkreślą prędkość, samochód może jechać agresywnie; jeśli przesadzą z naciskiem na bezpieczeństwo, może poruszać się bardzo wolno. Zmiana preferencji później zwykle oznacza powrót do retrenowania dużej sieci neuronowej od zera, co jest powolne, pamięciochłonne i wrażliwe na ustawienia techniczne.
Podział jazdy na proste cele
NeuroAction rozwiązuje to, dzieląc zadanie prowadzenia na kilka wyraźnych celów zamiast jednego. W badaniu wirtualny kierowca samochodu oceniany jest niezależnie według trzech kryteriów: jak szybko porusza się w bezpiecznym zakresie, jak wiernie utrzymuje się w najbardziej prawym (zwykle bezpieczniejszym) pasie oraz jak dobrze unika kolizji. Zamiast łączyć je w jeden wynik, metoda traktuje je jako oddzielne miary. W praktyce każda możliwa polityka jazdy — sieć neuronowa przetwarzająca dane z czujników na decyzje o kierunku i prędkości — jest oceniana jednocześnie wzdłuż wszystkich trzech osi.
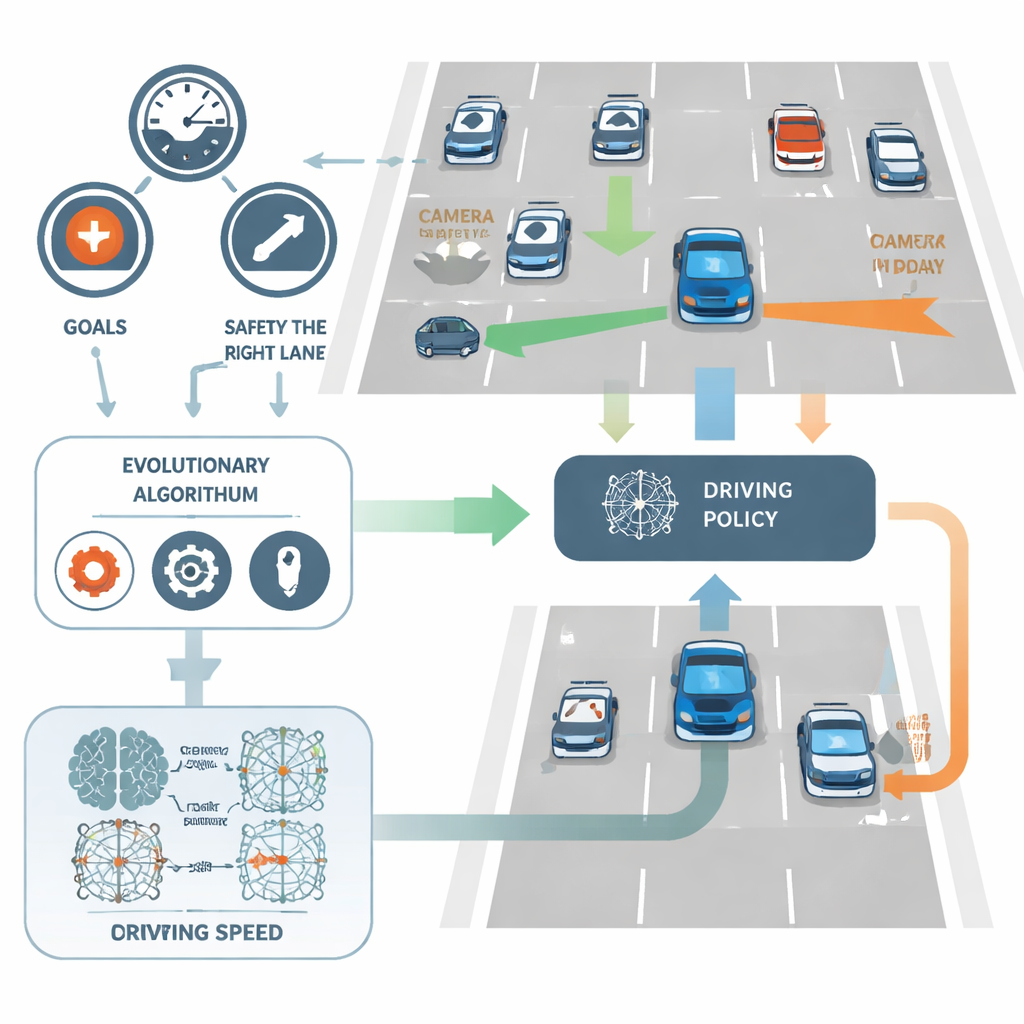
Pozwól ewolucji wyszukać lepszych kierowców
Zamiast dopracowywać wagi sieci standardową techniką wstecznej propagacji, NeuroAction wykorzystuje pomysły zapożyczone z ewolucji biologicznej. Tworzy się populację różnych polityk prowadzenia i testuje je w symulowanym środowisku autostradowym. Polityki, które osiągają dobre kompromisy między prędkością, dyscypliną pasa a bezpieczeństwem, są zachowywane i krzyżowane, podczas gdy gorsze są odrzucane. W wielu pokoleniach proces ewolucyjny odkrywa całą granicę silnych rozwiązań — zwaną frontem Pareto — gdzie żadnej polityki nie można poprawić w jednym celu bez poświęcenia przynajmniej jednego innego.
Porównanie uczenia ewolucyjnego i opartego na pochodnych
Naukowcy zastosowali NeuroAction w szeroko stosowanym symulatorze autostradowym 2D, używając standardowego agenta prowadzenia opartego na sieci neuronowej. Następnie optymalizowali parametry agenta za pomocą kilku ustalonych wielokryterialnych algorytmów ewolucyjnych, porównując, jak dobrze każdy z nich potrafi pokryć zakres pożądanych kompromisów. Kluczową miarą wydajności jest „hiperobjętość” odkrytego frontu, która uchwyca zarówno jakość, jak i różnorodność rozwiązań. Jeden z algorytmów, NSGA-II, osiągnął najlepsze ogólne pokrycie, podczas gdy jego bliski krewny, NSGA-III, dał szczególnie spójne wyniki przy powtórzonych uruchomieniach.
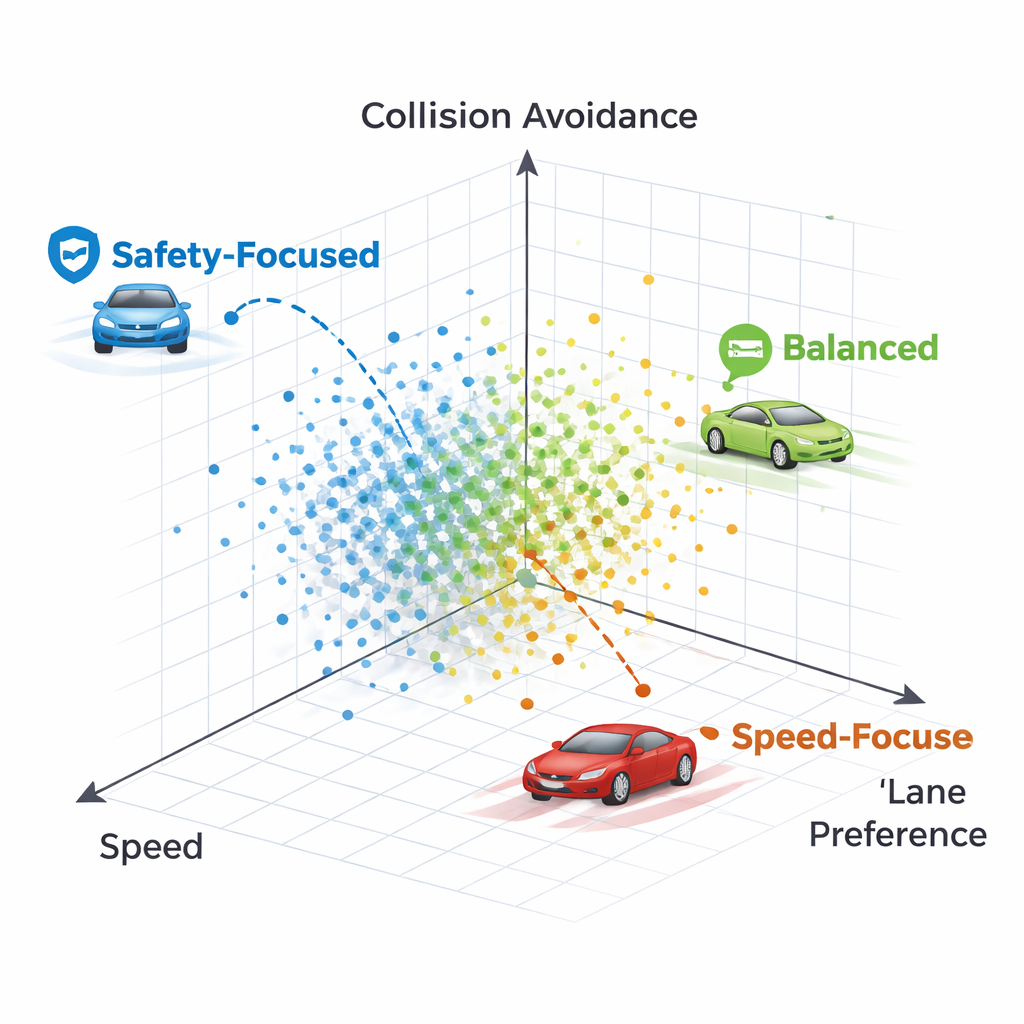
Jak wyglądają różne style prowadzenia
Poprzez analizę poszczególnych polityk z frontu Pareto autorzy pokazują, że każdy punkt odpowiada rozpoznawalnie innemu stylowi jazdy. Jedna polityka trzyma się mocno prawego pasa niemal za wszelką cenę, kosztem prędkości, aż w końcu zderza się z bardzo wolnym pojazdem przed sobą — strategia nadmiernie ostrożna, która przykłada zbyt dużą wagę do preferencji pasa. Inna polityka początkowo zmienia pasy, ale potem wraca do wolnego prawego pasa, utrzymując wyższą prędkość przy jednoczesnym unikaniu kolizji. Ogólnie metody te generują spektrum strategii — od konserwatywnych, trzymających pas kierowców po bardziej asertywnych, ale wciąż bezpiecznych podróżników — wszystkie dostępne jednocześnie bez retrenowania.
Co to znaczy dla przyszłych samochodów autonomicznych
Dla osoby niebędącej specjalistą główne przesłanie jest takie, że NeuroAction zamienia trenowanie samochodów autonomicznych w poszukiwanie wielu dobrych opcji zamiast jednego stałego zachowania. Umożliwia to wybór polityki jazdy dopasowanej do sytuacji — wolniej i maksymalnie bezpiecznie przy przewożeniu dzieci, szybciej, gdy się spieszysz — przy jednoczesnym zachowaniu ograniczeń bezpieczeństwa. Chociaż obecne eksperymenty prowadzone są w symulacji i używają uproszczonych celów, ramy te wskazują drogę ku bardziej adaptacyjnym, świadomym preferencji pojazdom autonomicznym, które mogą oferować spersonalizowane, a zarazem niezawodne style jazdy oparte na solidnych podstawach matematycznych.
Cytowanie: Aboyeji, E., Ajani, O.S., Fenyom, I. et al. NeuroAction: a neuroevolutionary approach to reinforcement learning for autonomous vehicles. Sci Rep 16, 7403 (2026). https://doi.org/10.1038/s41598-026-38269-1
Słowa kluczowe: autonomiczne prowadzenie, uczenie ze wzmocnieniem, algorytmy ewolucyjne, optymalizacja wielokryterialna, samochody autonomiczne