Clear Sky Science · pl
Dezintegracja tensorowa bez rangi za pomocą uczenia metrycznego
Odnajdywanie wzorców w morzu danych
Współczesna nauka tonie w złożonych danych: zestawach skanów medycznych, mapach aktywności mózgu, obrazach astronomicznych i symulacjach materiałów. Nadanie sensu tym danym często oznacza sprowadzenie ich do prostszych form bez utraty istotnych informacji. Niniejszy artykuł przedstawia nowy sposób osiągnięcia tego celu. Zamiast próbować wiernie odtworzyć każdy piksel, koncentruje się na uchwyceniu prawdziwych relacji między próbkami — który mózg przypomina który, jaki kształt galaktyki jest podobny do innego — tak aby powstała mapa danych odzwierciedlała znaczenie, a nie surowe detale.
Od odtwarzania obrazów do mierzenia podobieństwa
Tradycyjne narzędzia do upraszczania danych wielowymiarowych, znane jako dekompozycje tensorowe, działają trochę jak rozkład akordu na dźwięki. Faktoryzują blok danych na niewielką liczbę podstawowych wzorców i wag. Aby to zrobić, trzeba z góry określić, ile wzorców — „ranga” — można użyć, i oceniać sukces po tym, jak dobrze oryginalne dane da się odtworzyć. To idealne podejście do kompresji czy usuwania szumu, ale niekoniecznie najlepsze do zadań typu „czy te dwie twarze należą do tej samej osoby?” albo „czy ten skan mózgu pochodzi od osoby z autyzmem czy typowej?” — gdzie poprawne grupowanie ma większe znaczenie niż perfekcyjne odtworzenie.
Równolegle, głębokie uczenie spopularyzowało inne podejście: zamiast algebraicznie dekomponować tensor, uczyć kompaktowego kodu numerycznego, czyli osadzenia (embeddingu) za pomocą sieci neuronowej. Klasyczne autoenkodery wciąż skupiają się na rekonstrukcji. Ta praca odwraca cel. Proponuje ramy „bez rangi”, które nie ustalają rangi z wyprzedzeniem i nie dbają o idealne odtworzenie pikseli. Zamiast tego uczą miary odległości tak, aby punkty, które powinny być bliskie (ta sama osoba, ta sama diagnoza, ta sama klasa fizyczna) kończyły jako sąsiedzi w przestrzeni osadzeń, a punkty, które powinny być różne — były od siebie oddzielone.
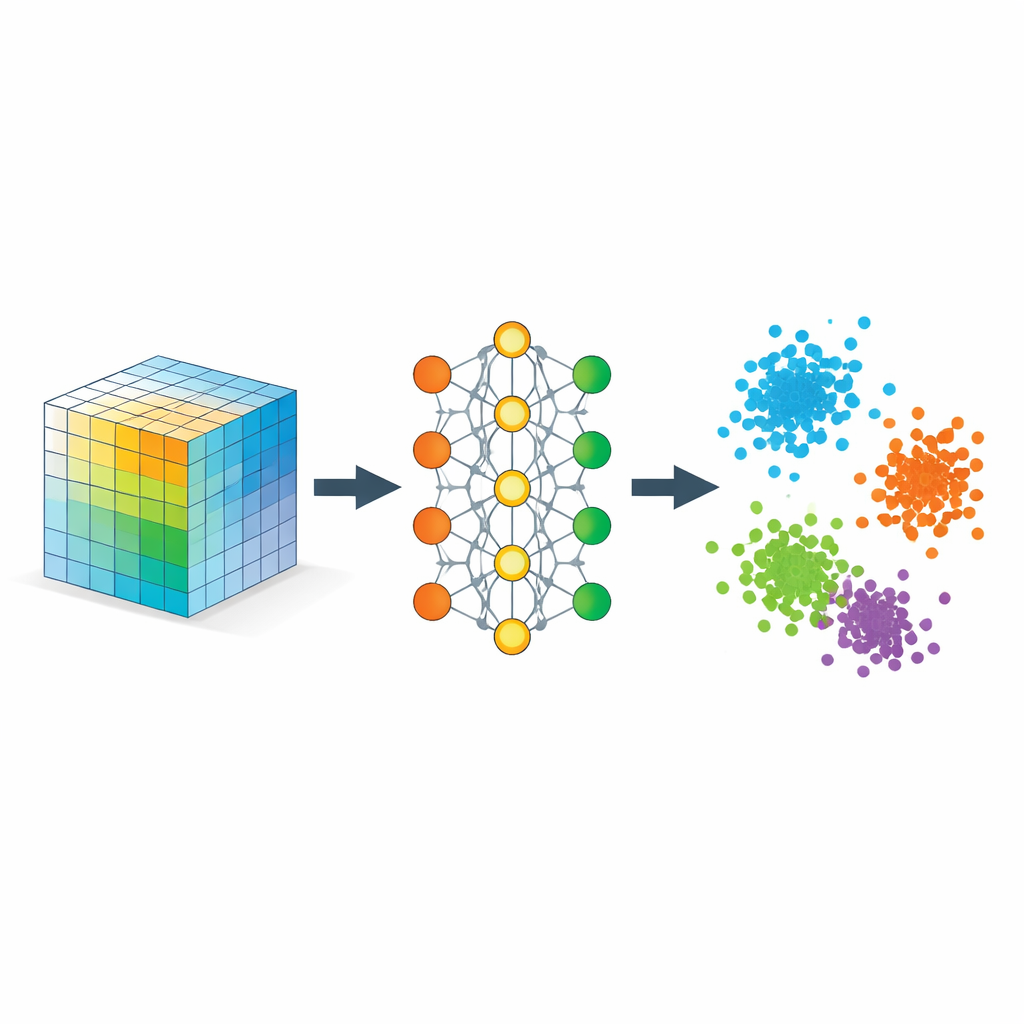
Nauczanie sieci, co powinno znaczyć „blisko”
Kluczowym składnikiem jest strategia zwana uczeniem metrycznym, zaimplementowana tutaj przez trójki przykładów: próbkę kotwiczną, próbkę pozytywną tej samej klasy i próbkę negatywną innego typu. Podczas treningu sieć jest nagradzana, gdy kotwica znajduje się bliżej próbki pozytywnej niż negatywnej o określony margines bezpieczeństwa. Wiele takich trójek sprawia, że ta prosta zasada formuje przestrzeń osadzeń tak, by odległości odzwierciedlały podobieństwo semantyczne, a nie surowe podobieństwo pikseli. Dodatkowe regularyzatory zachęcają sieć do równomiernego rozkładania informacji między wymiarami, uniknięcia skompresowania wszystkiego do linii oraz zachowania przybliżonych sąsiedztw lokalnych, tak aby punkty bliskie w danych oryginalnych pozostały bliskie po osadzeniu.
Matematycznie autorzy pokazują, że takie osadzenie zachowuje się jak elastyczna dekompozycja tensora, lecz bez z góry ustalonej rangi. Wyuczone współrzędne można interpretować jako czynniki w klasycznej dekompozycji tensora podobieństw, którego elementy mierzą, jak silnie różne części danych się pokrywają. Ponieważ model karze redundantne kierunki, skłania się ku efektywnemu wykorzystaniu wszystkich wymiarów osadzenia, pozwalając danym określić, ile znaczących komponentów jest potrzebnych. Równocześnie autorzy dostarczają gwarancji teoretycznych, że standardowe procedury treningowe zbieżają, a uzyskana geometria wiernie rozdziela klasy, nie zniekształcając przy tym nadmiernie istotnych lokalnych relacji.
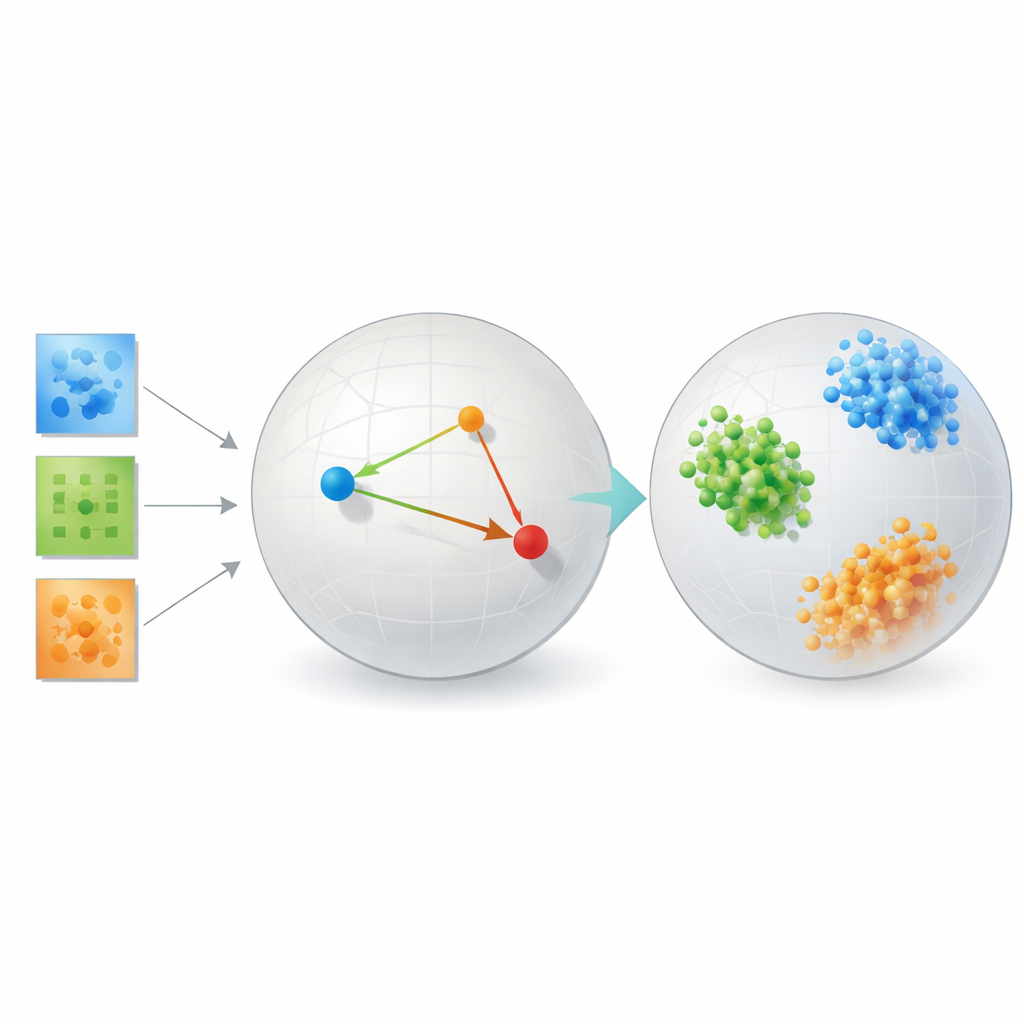
Testowanie metody
Aby pokazać, że podejście nie jest jedynie elegancką teorią, autor testuje je na kilku bardzo różnych problemach. W benchmarkach rozpoznawania twarzy wyuczone osadzenia grupują obrazy tej samej osoby w zwarte, dobrze rozdzielone klastry, znacznie przewyższając klasyczne metody takie jak analiza głównych składowych (PCA), popularne narzędzia wizualizacyjne jak t-SNE i UMAP oraz tradycyjne dekompozycje tensorowe bazujące na ustalonych rangach. W danych dotyczących łączności mózgu u osób z autyzmem i bez, metoda odkrywa przestrzeń, w której dwie grupy są czystszo rozdzielone niż przy użyciu narzędzi tensorowych ukierunkowanych na rekonstrukcję czy autoenkoderów, sugerując, że skupia się na klinicznie istotnych wzorcach interakcji między regionami mózgu.
Badanie obejmuje także kontrolowane symulacje kształtów galaktyk i struktur krystalicznych, gdzie „prawdziwe” kategorie są dokładnie znane. Tam ramy uczenia metrycznego niemal doskonale grupują syntetyczne galaktyki i kryształy według ich podstawowych typów fizycznych. We wszystkich tych zastosowaniach metoda konsekwentnie wymienia część wierności względem oryginalnego układu pikseli na reprezentację, w której podobieństwo i różnica pokrywają się z naukowym znaczeniem. Co ważne, osiąga to bez ogromnych zasobów danych i obliczeń często potrzebnych do trenowania modeli opartych na transformatorach, które miały trudności na tych stosunkowo niewielkich naukowych zbiorach danych.
Dlaczego to ma znaczenie dla przyszłych danych naukowych
Dla naukowców szukających wzorców w ograniczonych, wysokowymiarowych danych, ta praca oferuje atrakcyjną zmianę perspektywy. Zamiast zgadywać rangę i optymalizować rekonstrukcję, badacze mogą bezpośrednio zażądać osadzenia odzwierciedlającego relacje, na których im zależy: ta sama diagnoza, ta sama faza materiału, ta sama klasa astrofizyczna. Proponowane ramy uczenia metrycznego bez rangi pokazują, że takie osadzenia mogą być zarówno interpretowalne, jak i skuteczne, szczególnie gdy danych jest mało. Jak zaznacza autor, wyzwania pozostają — w tym radzenie sobie z niezrównoważeniem klas i skalowaniem do wielu kategorii — ale przesłanie jest jasne: w wielu problemach naukowych lepiej jest nauczyć dobrą miarę podobieństwa niż odtwarzać każdy szczegół oryginalnego sygnału.
Cytowanie: Bagherian, M. No-rank tensor decomposition via metric learning. Sci Rep 16, 8326 (2026). https://doi.org/10.1038/s41598-026-38221-3
Słowa kluczowe: uczenie metryczne, dekompozycja tensora, uczenie reprezentacji, redukcja wymiarów, analiza danych naukowych