Clear Sky Science · pl
Modelowanie sprzężenia degradacji w sieci sterowanej VLM do fuzji obrazów w podczerwieni i świetle widzialnym świadomej degradacji
Ostrzejsza widoczność nocą w zaszumionym świecie
Współczesne kamery widzą w ciemności, rejestrują ciepło i pilnują drogi za nas — ale ich obrazy często są dalekie od ideału. Lampy uliczne powodują efekty olśnienia, cienie pochłaniają detale, a sensory dodają plamisty szum. W pracy tej przedstawiono nowy sposób łączenia zwykłego kolorowego wideo z termicznymi obrazami podczerwonymi, tak by końcowy widok był czytelniejszy i bardziej niezawodny, nawet gdy oba sygnały wejściowe są silnie zdegenerowane. Metoda ta może uczynić systemy autonomicznych pojazdów, nadzoru i inne inteligentne kamery bardziej odpornymi w sytuacjach, w których najbardziej ich potrzebujemy: w nocy, w złej pogodzie i w złożonych scenach rzeczywistych.
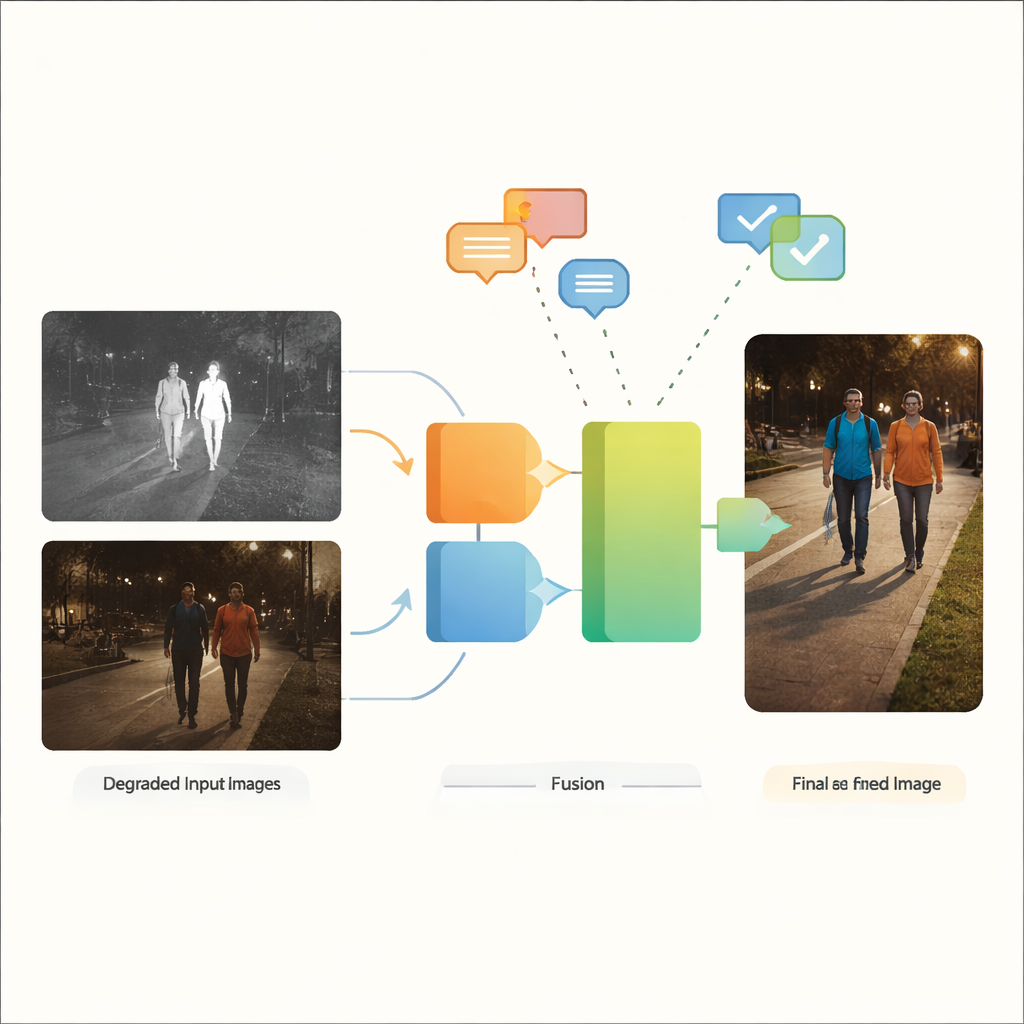
Dlaczego dwa „oczy” są lepsze niż jedno
Kamera światła widzialnego rejestruje bogate kolory i tekstury, do których przyzwyczajeni są ludzie, ale ma problemy przy słabym świetle, silnym olśnieniu i głębokich cieniach. Kamery podczerwieni z kolei wykrywają ciepło i łatwo wyróżniają ciepłe obiekty, takie jak ludzie czy pojazdy w ciemności, choć ich obrazy często wyglądają płasko i pozbawione są drobnych szczegółów. Fuzja obrazów w podczerwieni i świetle widzialnym ma na celu połączenie najlepszych cech obu: ostrych konturów gorących obiektów z podczerwieni z kontekstowymi detalami i kolorem światła widzialnego. Tradycyjnie jednak większość metod fuzji zakłada, że oba obrazy wejściowe są już czyste i wysokiej jakości — co słabo odpowiada rzeczywistości ulic, miast i zakładów przemysłowych, gdzie rozmycie, szum, słabe oświetlenie i prześwietlenia są regułą, a nie wyjątkiem.
Kiedy wstępne przetwarzanie zawodzi
Obecne systemy zazwyczaj radzą sobie ze słabymi obrazami w dwóch oddzielnych etapach. Najpierw osobne narzędzia poprawiające rozjaśniają sceny, redukują szum lub korygują kontrast. Dopiero potem sieć fuzji łączy ulepszone obrazy. To dwuetapowe podejście ma kilka wad. Zmusza inżynierów do wybierania i strojenia różnych narzędzi poprawczych dla każdego typu defektu i każdego sensora, co sprawia, że przepływy pracy są kruche i złożone. Co ważniejsze, wszelkie informacje utracone lub zniekształcone w samodzielnym kroku oczyszczania nie mogą być potem odzyskane przez etap fuzji. Niektóre nowsze badania wprowadziły specjalne sieci dostrojone do jednego typu degradacji lub używały modeli sterowanych językowo, aby obsługiwać jedną złą modalność na raz. Gdy jednak oba obrazy — podczerwieni i widzialny — są zdegenerowane, często w różny sposób, te strategie nadal silnie zależą od ręcznego wstępnego przetwarzania i mają trudności z mieszanymi, rzeczywistymi warunkami.
Sieć fuzji, która rozumie degradację
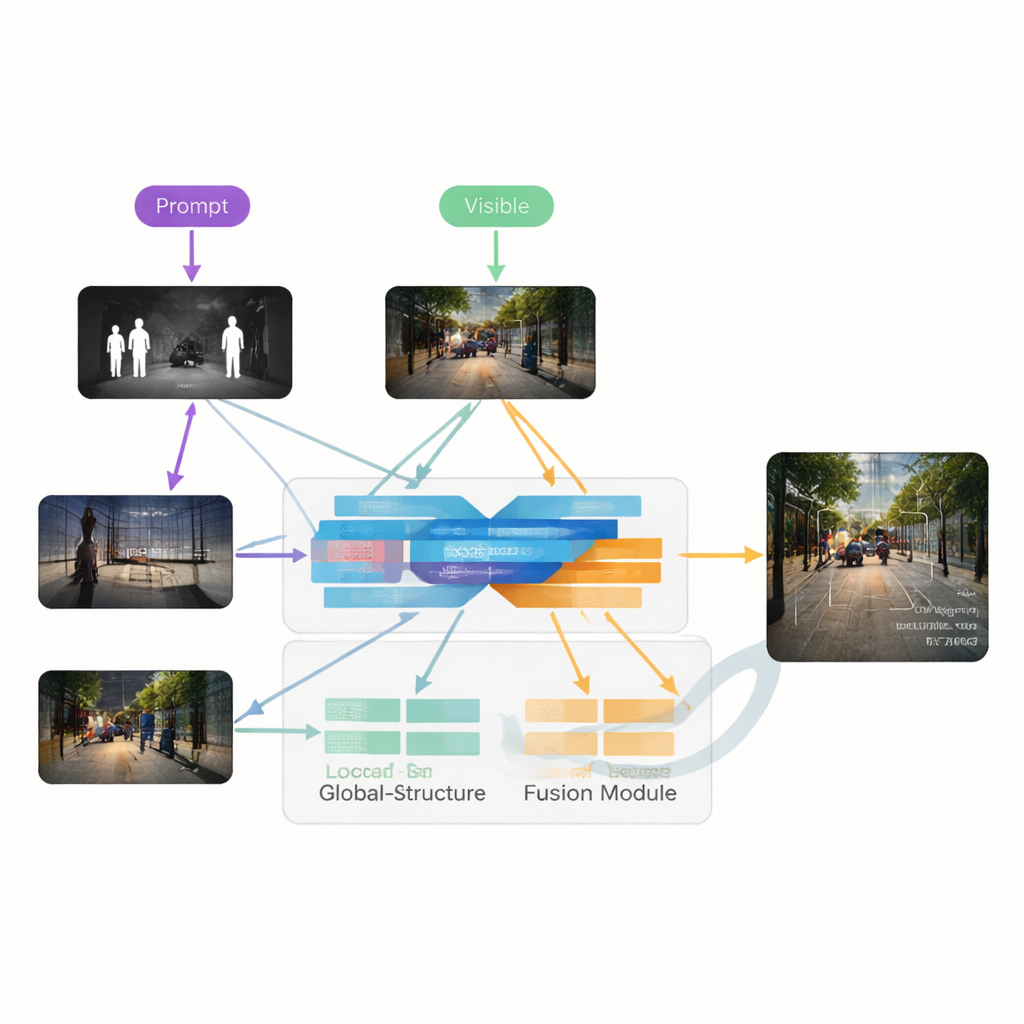
Autorzy proponują VGDCFusion — nowe ramy uczenia głębokiego, które wplata obsługę degradacji bezpośrednio w proces fuzji. Kluczowy pomysł polega na poinformowaniu sieci, słowami, jakiego rodzaju problemów ma się spodziewać, a następnie wykorzystaniu tej wiedzy na każdym etapie ekstrakcji i łączenia cech. Krótkie tekstowe podpowiedzi opisują zadanie (fuzja podczerwieni i widzialnego) oraz konkretne występujące problemy, takie jak słabe oświetlenie, prześwietlenie, niski kontrast czy szum. Potężny model wizja–język — podobny duchem do systemów takich jak CLIP — przekształca te podpowiedzi w zwarte deskryptory numeryczne. Deskryptory te kierują dwiema głównymi blokami: Specific-Prompt Degradation-Coupled Extractor (SPDCE), działającym oddzielnie na każdej modalności, oraz Joint-Prompt Degradation-Coupled Fusion (JPDCF), który łączy informacje między modalnościami, jednocześnie uwzględniając, jaki rodzaj degradacji pozostał.
Jak działa prowadzony proces fuzji
W każdym module SPDCE wskazówki pochodzące z podpowiedzi kierują sieć ku cechom istotnym i z dala od artefaktów. Wieloskalowe warstwy splotowe analizują małe sąsiedztwa, by zachować krawędzie i faktury, podczas gdy warstwy Transformer przechwytują strukturę i kontekst w większej skali. Razem uczą się uwypuklać, na przykład, ważne sygnatury cieplne w zaszumionej klatce podczerwieni lub słabe oznakowania drogowe w niedoświetlonym obrazie widzialnym, jednocześnie tłumiąc szum sensora i defekty oświetleniowe. Równolegle moduły JPDCF pobierają oczyszczone cechy z obu gałęzi i łączą je, także pod nadzorem podpowiedzi. Używają uwagi przestrzennej i kanałowej, aby podkreślić informacyjne regiony, przefiltrować pozostałą degradację i scalić uzupełniające się wskazówki — na przykład wyrównać jasny kontur pieszego z podczerwieni z kolorem i strukturą tła z kamery widzialnej — zanim zrekonstruują złączony, trójkanałowy obraz wyjściowy.
Testy metody
Aby wykazać przydatność, zespół ocenił VGDCFusion na kilku publicznych zestawach danych, które zawierają niedoświetlone i prześwietlone obrazy widzialne oraz zaszumione lub niskokontrastowe obrazy w podczerwieni. Porównali swoją metodę z szeregiem najnowocześniejszych technik fuzji obejmujących autoenkodery, sieci splotowe, generatywne sieci przeciwstawne i Transformatory. Przy użyciu standardowych miar jakości obrazu VGDCFusion konsekwentnie generował obrazy z ostrzejszymi krawędziami, lepszym kontrastem i bardziej naturalnymi kolorami, nawet gdy konkurencyjnym metodom przyznano przewagę w postaci starannie wyregulowanego wstępnego przetwarzania. Nowe podejście poprawiło kluczowe metryki średnio o około 15% w silnie zdegradowanych scenariuszach. Gdy złącowane obrazy podawano do popularnego systemu detekcji obiektów, także uzyskano wyższą dokładność wykrywania niż przy użyciu samych obrazów podczerwieni lub widzialnych albo innych sieci fuzji.
Czystsza wizja dla bezpieczniejszych systemów
Mówiąc prosto, praca pokazuje, że poinformowanie sieci fuzji obrazów o rodzajach spodziewanych problemów wizualnych — i pozwolenie jej na jednoczesne naprawianie i łączenie w jednym ściśle powiązanym kroku — może dać czyściejsze, bardziej informacyjne obrazy niż traktowanie poprawy i fuzji jako odrębnych zadań. Poprzez sprzężenie modelowania degradacji z procesem fuzji i użycie wskazówek sterowanych językowo na każdej warstwie, VGDCFusion potrafi dostosować się do zróżnicowanych i mieszanych form degradacji obrazu bez ciągłego ręcznego strojenia. Tego typu inteligentna, świadoma degradacji fuzja może pomóc przyszłym systemom widzenia, od autonomicznych samochodów po kamery bezpieczeństwa, lepiej widzieć w nieporządnych, niedoskonałych warunkach świata rzeczywistego.
Cytowanie: Zhao, J., Zhang, T. & Cui, G. A VLM guided network coupling degradation modeling for degradation aware infrared and visible image fusion. Sci Rep 16, 8249 (2026). https://doi.org/10.1038/s41598-026-38181-8
Słowa kluczowe: fuzja obrazu w podczerwieni i świetle widzialnym, obrazowanie w słabym świetle, modele wizja-język, degradacja obrazu, percepcja w autonomicznej jeździe