Clear Sky Science · pl
Hybrydowe, warstwowe podejście ensemble do wieloetykietowego wykrywania emocji w tekście
Dlaczego czytanie emocji w tekście ma znaczenie
Każdego dnia ludzie wylewają swoje uczucia w postach w mediach społecznościowych, recenzjach i wiadomościach. Ukryte w tym potoku słów są wczesne sygnały problemów ze zdrowiem psychicznym, narastającej mowy nienawiści oraz reakcji społecznych na kryzysy i katastrofy. Komputery jednak zazwyczaj widzą jedynie „pozytywny” lub „negatywny” nastrój, pomijając mieszankę emocji, które ludzie często wyrażają jednocześnie. Ten artykuł opisuje nowe podejście do nauczenia maszyn rozpoznawania wielu emocji w jednym fragmencie tekstu, i to nie tylko po angielsku, lecz także w językach, które rzadko korzystają z zaawansowanej sztucznej inteligencji.
Wyjście poza proste pozytywne lub negatywne
Tradycyjne narzędzia analizy sentymentu przypominają tępe termometry: potrafią stwierdzić, czy nastrój jest dobry czy zły, ale nie rozpoznają, czy ktoś odczuwa złość, strach, nadzieję czy ulgę jednocześnie. Autorzy twierdzą, że zrozumienie tej bogatszej palety emocji ma kluczowe znaczenie dla zastosowań takich jak reagowanie na katastrofy, wsparcie terapeutyczne i obsługa klienta. Na przykład wiadomość łącząca strach i poczucie pilności może wymagać natychmiastowej reakcji, podczas gdy komunikat mieszający smutek i optymizm może potrzebować innego rodzaju wsparcia. Ujmowanie równoległego występowania wielu emocji — znane jako wykrywanie emocji wieloetykietowe — jest więc ważnym krokiem ku systemom bardziej wrażliwym i świadomym ludzkich uczuć.
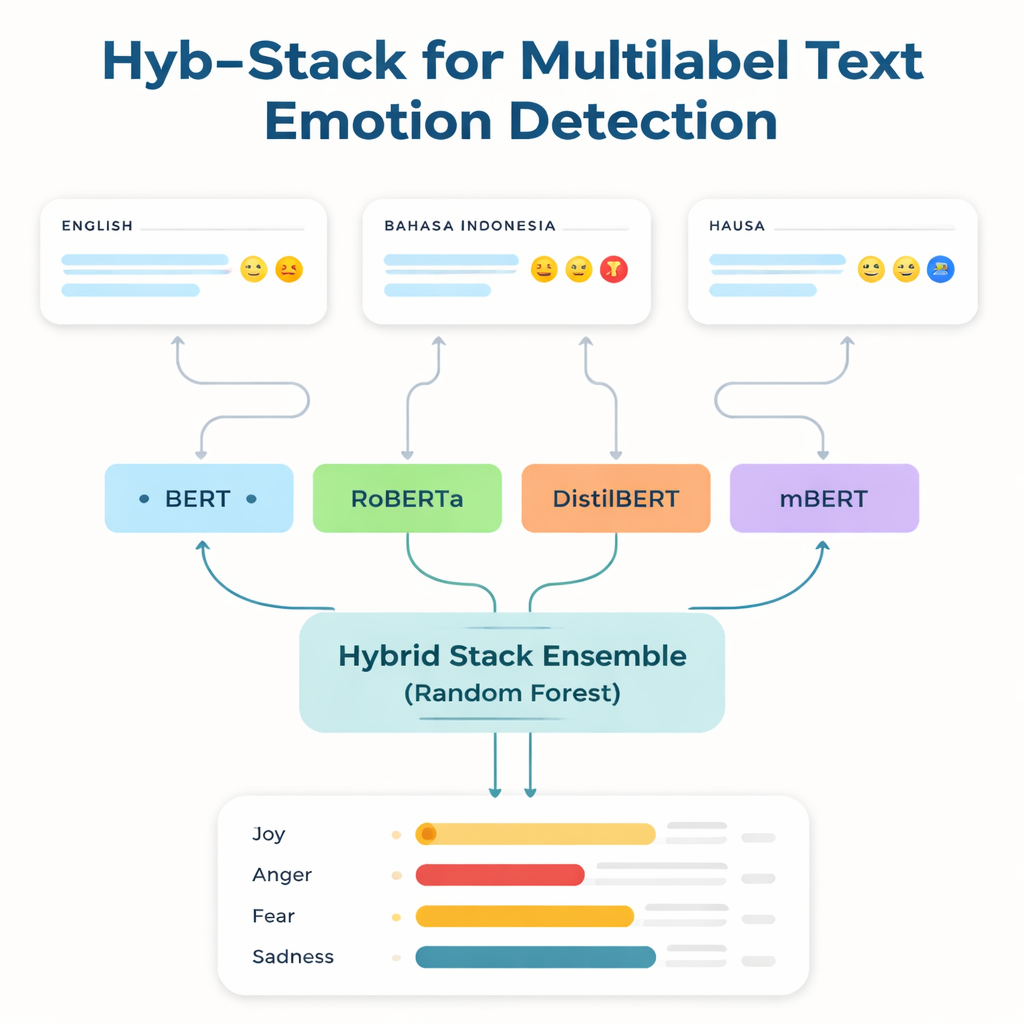
Nadanie głosu pomijanym językom
Większość zaawansowanych technologii językowych jest trenowana i dostrajana na danych anglojęzycznych i kilku innych powszechnie używanych językach. Mówcy języków o ograniczonych zasobach — tych z niewielką ilością danych oznaczonych i nielicznymi narzędziami cyfrowymi — są często pomijani. Aby sprostać tej luki, badacze skupili się na trzech zbiorach danych: znanym angielskim benchmarku emocji; kolekcji Bahasa Indonesia skoncentrowanej na języku obraźliwym i nienawiści; oraz zupełnie nowym korpusie tweetów w języku Hausa, który stworzyli, nazwanym HaEmoC_V1. Zbiór Hausa obejmuje ponad dwanaście tysięcy starannie oczyszczonych i anotowanych tweetów, z których każdy oznaczono jednym lub kilkoma z jedenastu emocji, takich jak złość, radość, zaufanie, pesymizm i oczekiwanie. Eksperci sprawdzili etykiety, a wyniki zgodności pokazały, że anotacje są zarówno spójne, jak i rzetelne.
Połączenie kilku inteligentnych czytelników w jedno
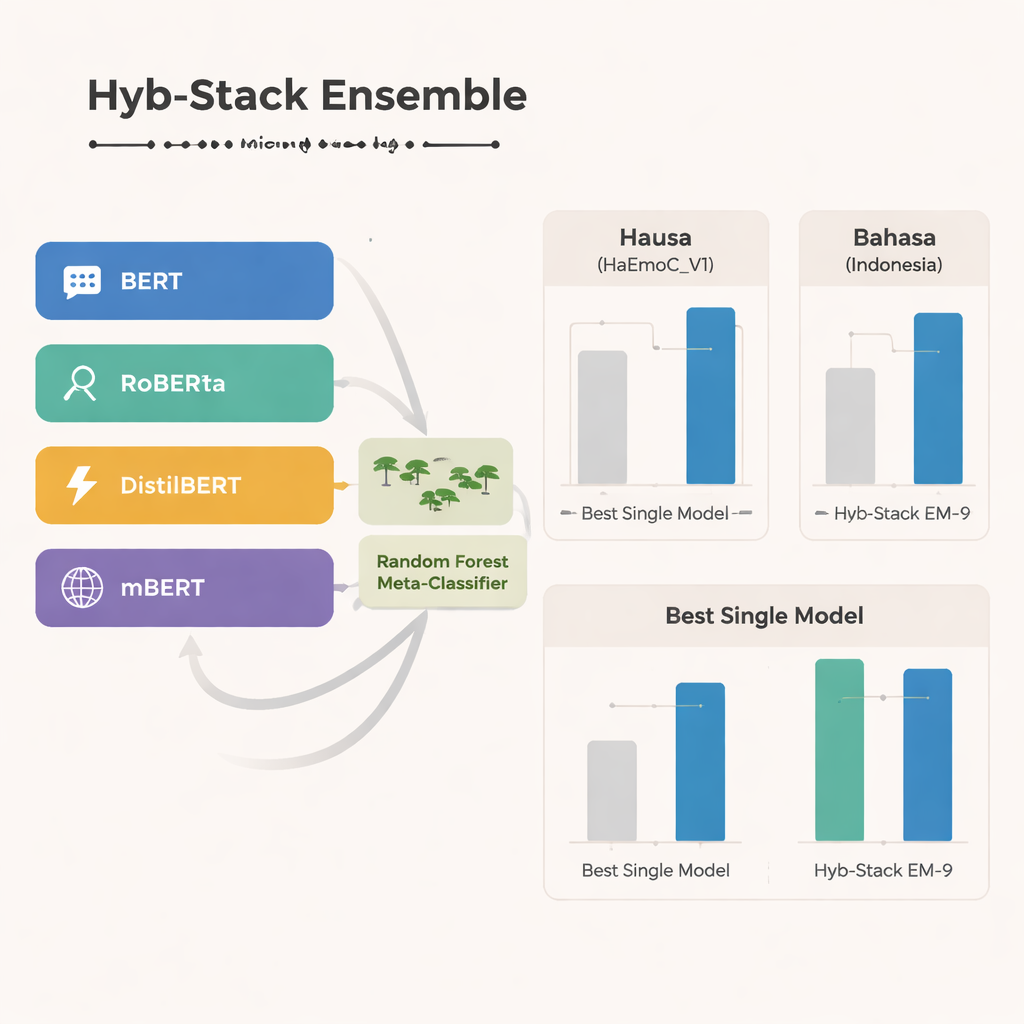
W sercu badania znajduje się Hyb-Stack, hybrydowy, warstwowy ensemble — rodzaj „komitetu ekspertów” dla języka. Cztery zaawansowane modele oparte na transformerach (BERT, RoBERTa, DistilBERT i wielojęzyczny mBERT) są każdy dostrajane, aby wykrywać sygnały emocjonalne w tekście. Zamiast polegać na jednym modelu, Hyb-Stack pozwala wszystkim na przewidywanie, a następnie przekazuje ich wewnętrzne wyniki do decydenta drugiego poziomu: klasyfikatora Random Forest. Ten meta-klasyfikator uczy się, jak ważyć różne mocne strony każdego modelu, wychwytując złożone wzorce współwystępowania emocji. Zespół testuje też prostsze metody ensemble, które jedynie uśredniają prognozy, z wagami opartymi lub nieopartymi na wcześniejszej wydajności, aby sprawdzić, czy bardziej złożone stackowanie rzeczywiście się opłaca.
Jak dobrze działa podejście hybrydowe
We wszystkich trzech językach wyróżnia się wielojęzyczny mBERT jako najsilniejszy pojedynczy model, szczególnie dobrze radzący sobie na nowo zbudowanych danych Hausa i zbiorze Bahasa Indonesia dotyczącego mowy nienawiści. Jednak hybrydowy ensemble osiąga jeszcze lepsze wyniki. Jedna specyficzna kombinacja — nazwana EM-9, łącząca BERT, DistilBERT i mBERT w ramach Hyb-Stack — konsekwentnie daje najlepsze rezultaty. Osiąga wyższe wartości F1, powszechnie stosowanej miary dokładności, niż którykolwiek pojedynczy model lub proste uśrednianie, przy największych przyrostach widocznych w niskozasobowych zbiorach Hausa i Bahasa Indonesia. Szczegółowe analizy błędów pokazują, że pozostałe pomyłki zwykle występują między blisko spokrewnionymi emocjami, takimi jak radość kontra zaskoczenie czy smutek kontra strach, co odzwierciedla naturalną nieostrość ludzkich uczuć, a nie wyraźne awarie systemu.
Co to oznacza dla systemów w praktyce
Dla ogólnego czytelnika główny wniosek jest taki, że połączenie kilku modeli AI w przemyślany sposób może pomóc komputerom dokładniej czytać emocje w tekście, szczególnie w językach długo pomijanych przez technologię. Budując wysokiej jakości korpus emocji w języku Hausa i pokazując, że hybrydowe ensemble przewyższają pojedyncze modele i proste schematy głosowania, autorzy demonstrują praktyczną drogę do bardziej inkluzywnych, emocjonalnie wyczulonych narzędzi. Przyszłe prace rozszerzą podejście na subtelniejsze odcienie emocji, język mieszany, emotikony i kolejne niedostatecznie reprezentowane języki, z celem tworzenia systemów, które potrafią wyczuć nie tylko czy ludzie są szczęśliwi czy smutni, ale także jak i dlaczego tak się czują — bez względu na język, jakim się posługują.
Cytowanie: Adamu, H., Azmi Murad, M.A. & Nasharuddin, N.A. A hybrid stacked ensemble learning framework for multilabel text emotion detection. Sci Rep 16, 7714 (2026). https://doi.org/10.1038/s41598-026-38172-9
Słowa kluczowe: wykrywanie emocji, wielojęzyczne NLP, uczenie zespołowe, modele transformerowe, języki o ograniczonych zasobach