Clear Sky Science · pl
Wydajne obliczenia i projekt architektury szybkiego podwójnej precyzji mnożnika według metody wedyjskiej
Dlaczego szybsze przetwarzanie liczb ma znaczenie
Za każdym razem, gdy oglądasz strumień wideo, korzystasz z nawigacji w telefonie lub pozwalasz systemowi AI analizować obrazy medyczne, specjalizowany sprzęt komputerowy wykonuje dyskretnie miliardy drobnych obliczeń na sekundę. Duża część tych operacji to mnożenia na liczbach zmiennoprzecinkowych — standardowy sposób reprezentowania wartości rzeczywistych, takich jak 3,14159. Artykuł bada sprytniejszy sposób budowy jednego z tych podstawowych bloków: szybkiego, energooszczędnego mnożnika, który czerpie z idei starożytnej matematyki wedyjskiej, aby przyspieszyć nowoczesny sprzęt cyfrowy.
Od starożytnych trików matematycznych do współczesnych układów
Arytmetyka zmiennoprzecinkowa stanowi podstawę przetwarzania sygnałów cyfrowych, obróbki obrazu, łączności i akceleratorów uczenia głębokiego. Standardowe mnożniki muszą obsługiwać szerokie słowa binarne — 64 bity dla podwójnej precyzji — i robić to szybko, nie marnując przy tym powierzchni układu ani energii. Tradycyjne podejścia, takie jak Booth, Karatsuba czy mnożniki tablicowe, godzą kompromisy między szybkością, rozmiarem sprzętu i złożonością projektu. Matematyka wedyjska, system 16 klasycznych reguł arytmetycznych rozwinięty w Indiach, zawiera metodę mnożenia nazwaną Urdhva Tiryakbhyam, czyli „pionowo i ukośnie”. Tworzy ona częściowe produkty w sposób wysoce równoległy, co może zmniejszyć liczbę pośrednich kroków i potrzebny sprzęt. Badacze niedawno zaadaptowali te idee do układów cyfrowych, ale istniejące projekty wciąż niosą narzut przy operacjach zmiennoprzecinkowych o podwójnej precyzji.
Co wyróżnia ten nowy mnożnik
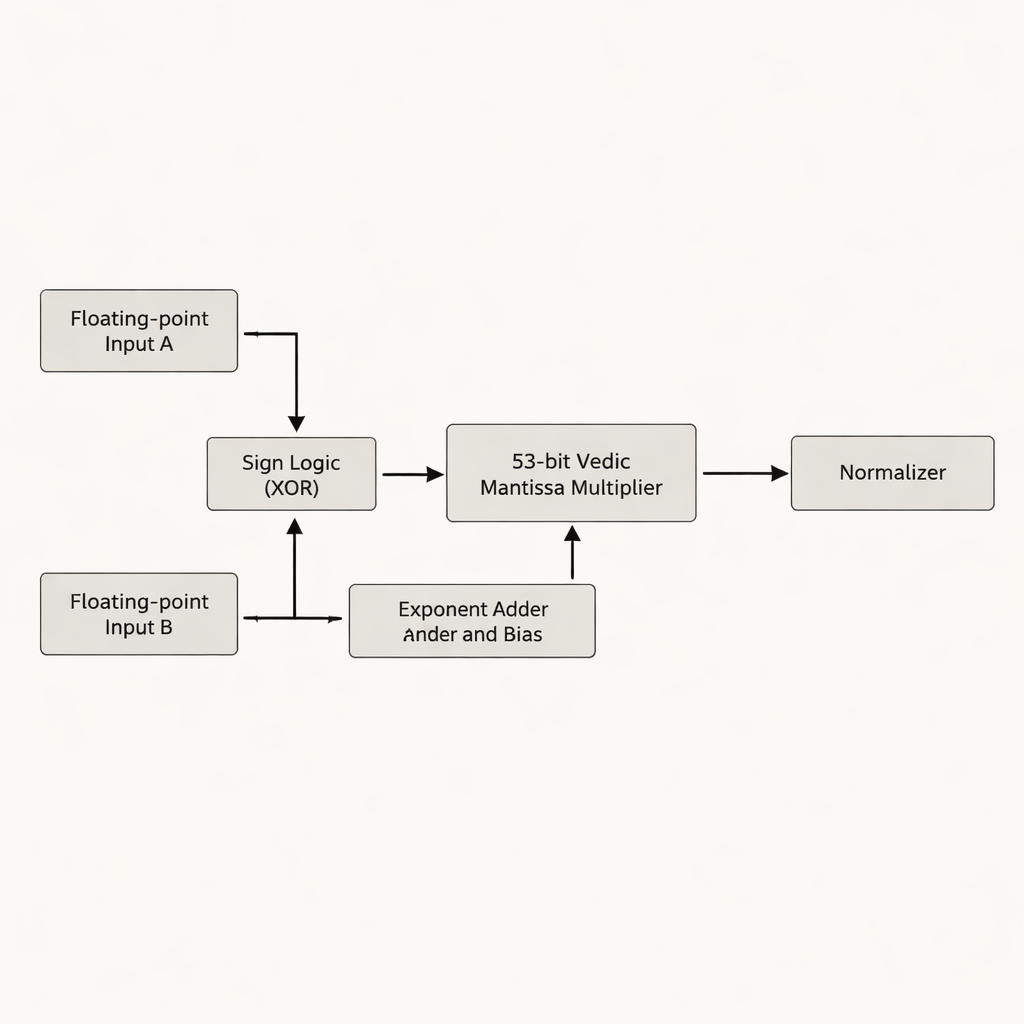
Autorzy proponują mnożnik zmiennoprzecinkowy podwójnej precyzji skupiony na mantysie — części liczby zmiennoprzecinkowej zawierającej większość cyfr znaczących. Zamiast dopasowywać 52-bitową mantysę do 54 bitów, jak robiło wiele wcześniejszych rozwiązań, pracują z rzeczywistą 53-bitową efektywną mantysą, unikając marnowania „pustych” bitów, które zapełniają dodatkowe miejsce i okablowanie na układzie. Rdzeń projektu stanowi 53-bitowy mnożnik wedyjski oparty na Urdhva Tiryakbhyam, ułożony w hierarchię mniejszych bloków: jednostki 3-bitowe tworzą jednostki 6-bitowe, które budują 12-bitowe, 13-bitowe, 26-bitowe i 52-bitowe bloki, wszystkie łączone w końcowym etapie 53-bitowym. Architektura dzieli pracę na trzy główne fazy — obliczanie znaku, dodawanie i przesunięcie wykładnika oraz mnożenie mantysy z następną normalizacją — zgodnie z normą IEEE-754, jednocześnie redukując zbędne obwody.
Bloki o rozmiarach pierwszorzędnych dla czystszego sprzętu
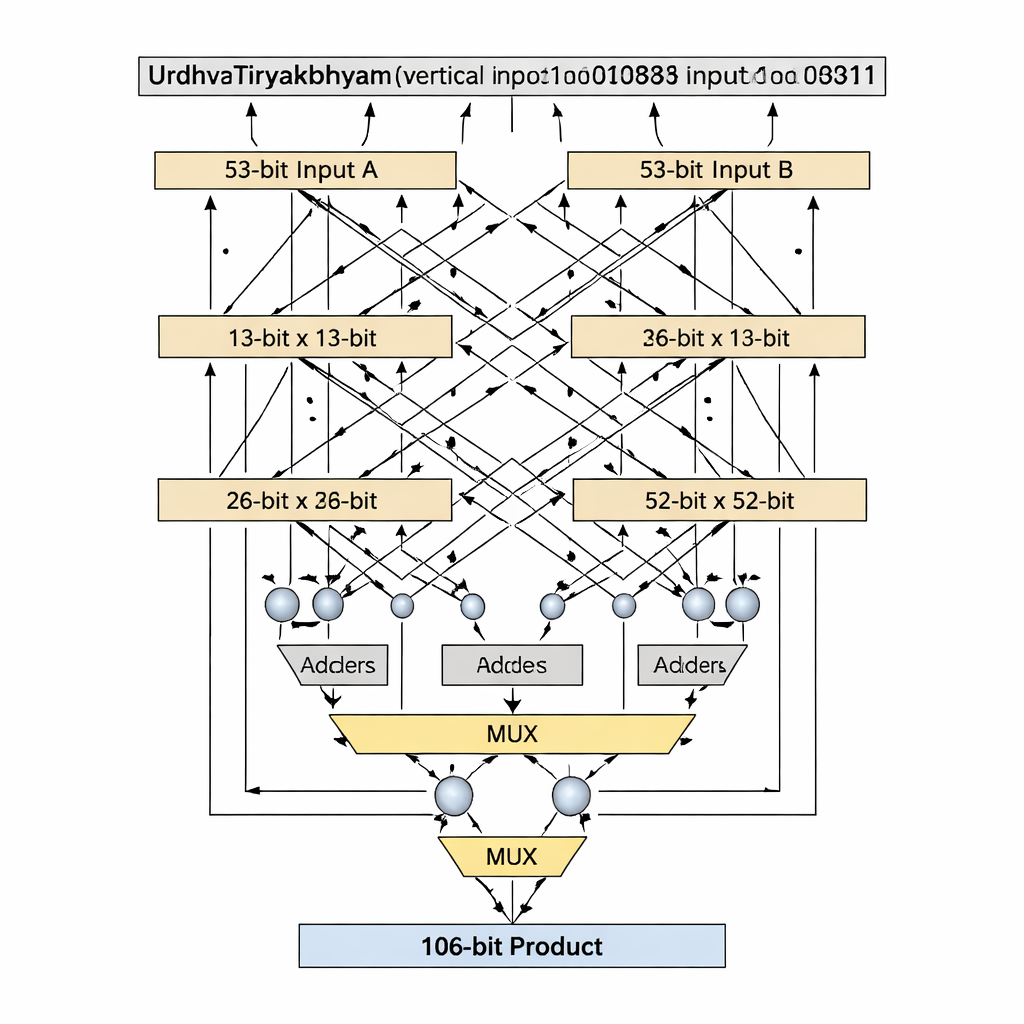
Kluczową innowacją jest sposób, w jaki projekt radzi sobie z szerokościami bitów będącymi liczbami pierwszymi, takimi jak 13 i 53, które nie dzielą się równo na równe bloki. Standardowe dekompozycje wedyjskie zakładają równomierne podziały wejść, co staje się nieporęczne lub marnotrawne dla długości pierwszorzędnych. Autorzy wprowadzają algorytm „prime-bit”, który sprytnie wykorzystuje mniejszy (n−1)-bitowy mnożnik wedyjski oraz dodawacze, multipleksery i jedną dodatkową bramkę logiczną, aby emulować n-bitowy mnożnik bez dopasowywania długości. Dla etapu 13-bitowego wejścia dzielone są na sekcje 1-bitową i 12-bitową; częściowe produkty tworzone są przy użyciu 12-bitowego mnożnika wedyjskiego, selekcji warunkowej (przez multipleksery) w oparciu o najbardziej znaczące bity oraz niewielkiej liczby dodawaczy. Ten sam wzorzec skaluje się do 53 bitów z rdzeniem 52-bitowym. Dostosowana dekompozycja skraca ścieżkę krytyczną — najdłuższy łańcuch logiki, który sygnał musi pokonać — przy jednoczesnym utrzymaniu niskiej liczby elementów logicznych.
Zmierzony wzrost prędkości, oszczędność miejsca i energii
Projekt został opisany w języku opisu sprzętu Verilog i zaimplementowany na programowalnej macierzy bramek Xilinx Zynq (FPGA) przy użyciu narzędzi Vivado. W porównaniu bloków Vedyjskich o szerokościach 13, 26, 52, 53 i 64 bitów, proponowana jednostka 53-bitowa wykazuje korzystny kompromis między opóźnieniem, wykorzystaniem logiki (tablice LUT i piny I/O) oraz szacowanym poborem mocy. W porównaniu z wcześniejszymi mnożnikami podwójnej precyzji opartymi na Booth, Karatsuba i innych układach wedyjskich, nowa architektura znacząco redukuje najgorsze opóźnienie i ilość zasobów FPGA, bez zwiększania złożoności otaczającej logiki zmiennoprzecinkowej. Ponieważ mnożenie mantys jest szybsze, a głębokość logiki mniejsza, aktywność przełączania spada, co sugeruje lepszy iloczyn mocy i opóźnienia, chociaż bezpośrednie porównania energetyczne między technologiami są trudne do przeprowadzenia.
Wpływ na AI i przetwarzanie sygnałów
Aby przetestować projekt w rzeczywistym obciążeniu, autorzy zintegrowali swój wedyjski mnożnik podwójnej precyzji z silnikiem splotowym w sieci splotowej (Convolutional Neural Network), gdzie operacje mnożenia i akumulacji dominują w czasie wykonania. Zastąpienie konwencjonalnych mnożników IEEE-754 i wcześniejszych układów wedyjskich nowym projektem skróciło opóźnienie w splotach, zmniejszyło pobór mocy i skróciło czas inferencji, przy zachowaniu tej samej dokładności klasyfikacji. Podobne korzyści spodziewane są w innych zadaniach intensywnie obliczeniowych, takich jak filtrowanie cyfrowe, wykrywanie krawędzi czy przetwarzanie obrazów medycznych, gdzie szybsze mnożniki bezpośrednio zwiększają przepustowość i pozwalają urządzeniom działać chłodniej lub na mniejszych bateriach.
Co to oznacza dla codziennej technologii
Mówiąc prościej, artykuł pokazuje, że zapożyczenie sprytnego pomysłu mnożenia z matematyki wedyjskiej i staranne dopasowanie go do współczesnych formatów binarnych może dać mnożnik mniejszy, szybszy i bardziej energooszczędny niż standardowe rozwiązania. Ten ulepszony blok budulcowy może zostać wpleciony w procesory, układy do przetwarzania sygnałów i akceleratory AI, prowadząc do szybszej analizy danych, bardziej responsywnych urządzeń i potencjalnie niższego zużycia energii w systemach od smartfonów po skanery medyczne. Autorzy opisują także przyszłe kierunki, w tym logikę odwracalną dla jeszcze niższego zużycia energii oraz integrację z większymi jednostkami przetwarzającymi, sugerując, że to połączenie starożytnej arytmetyki i nowoczesnego sprzętu dopiero się rozwija.
Cytowanie: Kumar, A.S., Sahitya, G., Kusuma, R. et al. Efficient computation and design of high speed double precision Vedic multiplier architecture. Sci Rep 16, 7364 (2026). https://doi.org/10.1038/s41598-026-38147-w
Słowa kluczowe: Mnożnik wedyjski, Arytmetyka zmiennoprzecinkowa, Projekt FPGA, Przetwarzanie sygnałów cyfrowych, Splotowe sieci neuronowe