Clear Sky Science · pl
Zastosowanie rojowych głębokich sieci neuronowych i modeli zespołowych do rekonstrukcji danych o przewodności właściwej
Dlaczego wypełnianie braków w danych ma znaczenie
Wody przybrzeżne to pierwsza linia zetknięcia działalności ludzkiej z oceanem. Naukowcy śledzą zasolenie tych wód mierząc tzw. przewodność właściwą, co pomaga wykrywać wycieki zanieczyszczeń, zmiany w dopływie wód słodkich oraz długoterminowe przemiany środowiskowe. Jednak czujniki zawodzą, burze wyłączają zasilanie, a urządzenia mają swoje ograniczenia. Efektem są frustrujące luki w kluczowych zapisach — dokładnie wtedy, gdy zarządzający i badacze najbardziej potrzebują ciągłych danych. W tym badaniu postawiono praktyczne pytanie: czy współczesna sztuczna inteligencja może wiarygodnie „naprawić” takie przerwane zapisy, aby decyzje dotyczące obszarów przybrzeżnych opierały się na pełnych, godnych zaufania informacjach?
Obserwując oddech Zatoki
Badacze skupili się na Zatoce Meksykańskiej, jednym z największych ekosystemów morskich na świecie i regionie pod dużą presją przemysłową oraz rolniczą. Wykorzystali pomiary z pięciu stacji US Geological Survey w rejonie rzeki Pascagoula i Mullet Lake, z których każda rejestrowała co 15 minut zasolenie (poprzez przewodność właściwą), temperaturę i poziom wody. Jedna stacja, oznaczona jako E, miała około 5% braków w danych o przewodności — dokładnie taki problem, z jakim zmagają się rzeczywiste sieci monitorujące. Dane z czterech sąsiednich stacji tworzyły rodzaj środowiskowej siatki bezpieczeństwa: nawet gdy stacja E „oślepła”, pozostałe nadal obserwowały. Główną ideą było nauczenie modeli komputerowych, jak wszystkie pięć stacji „oddycha” razem, tak by luki w jednym miejscu można było wnioskować na podstawie pełnych zapisów z pozostałych.
Testowanie inteligentnych algorytmów
Aby rozwiązać ten problem, zespół zebrał zestaw dziesięciu różnych podejść modelowych. Na jednym biegunie znalazły się znane narzędzia, takie jak wieloraka regresja liniowa, które próbują określić zależności prostoliniowe między zmiennymi wejściowymi i wyjściowymi. W środku znalazły się bardziej elastyczne modele, jak klasyczne sieci neuronowe, systemy logiki rozmytej oraz specjalna sieć typu long short‑term memory (LSTM) często używana do danych czasowych. Zastosowano także samoorganizującą się metodę zwaną group method of data handling (GMDH) oraz jej nieliniowy wariant (NGMDH), potrafiący samodzielnie budować wielowarstwowe formuły. Wreszcie wykorzystano metody oparte na drzewach: pojedynczy model drzewa decyzyjnego (CART) oraz dwa podejścia „zespołowe” — Random Forest i XGBoost — które łączą wiele drzew, aby podjąć ostateczną decyzję, podobnie jak panel ekspertów głosujący nad odpowiedzią.
Głębokie uczenie zasilane rojem
Uczenie głębokich sieci neuronowych bywa trudne: ich liczne parametry łatwo utknąć w nieoptymalnych konfiguracjach. Aby je ulepszyć, autorzy sparowali LSTM i NGMDH z nową metodą optymalizacyjną inspirowaną wirującą wodą, nazwaną turbulent flow of water‑based optimization (TFWO). W tym schemacie każdy możliwy zestaw parametrów modelu wyobrażany jest jako „cząstka” poruszająca się w wzorcu przypominającym wir w przestrzeni rozwiązań. W wielu cyklach cząstki są kierowane ku obszarom dającym mniejsze błędy predykcji. To rojowe poszukiwanie sprawiło, że obie klasy sieci były zauważalnie dokładniejsze niż ich standardowe wersje, zmniejszając średnie błędy o około 6–11 procent. Mimo to nawet te ulepszone modele głębokie ostatecznie zostały przewyższone przez metody oparte na drzewach.
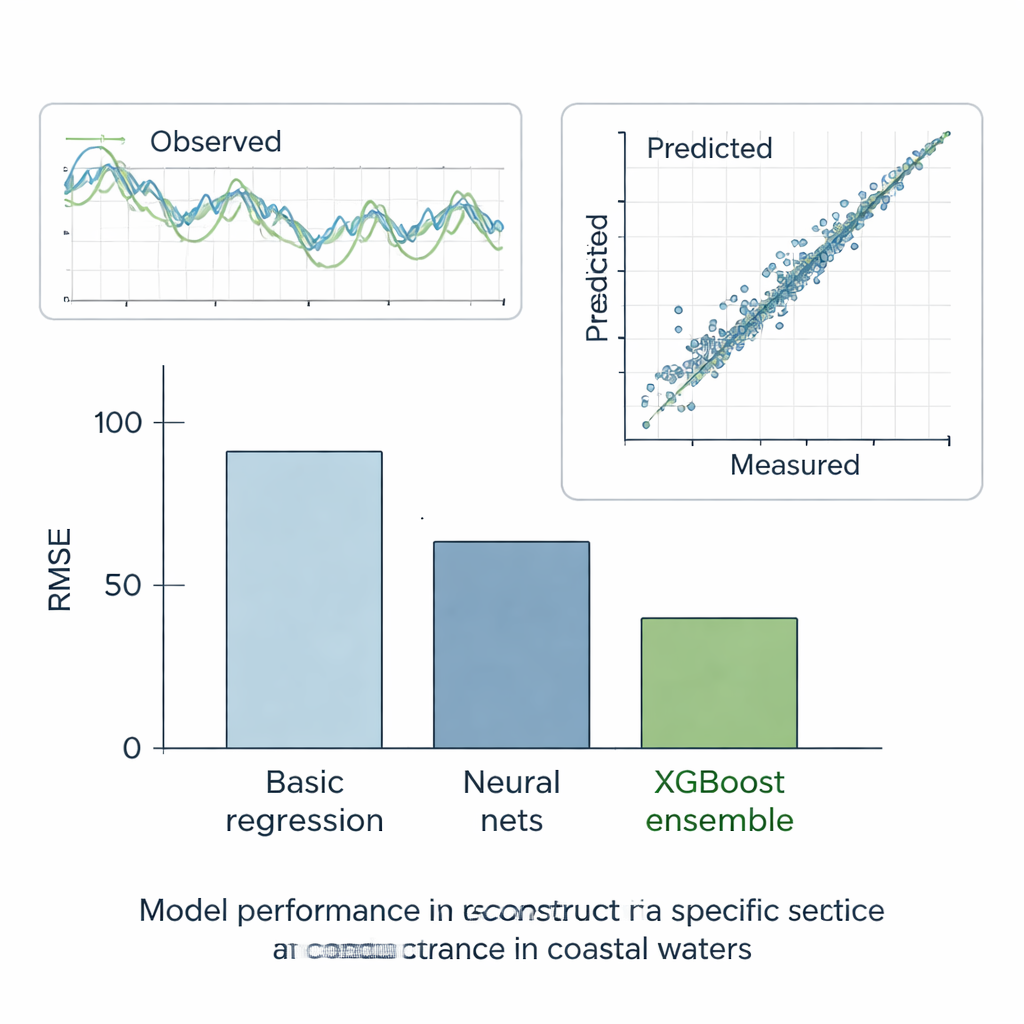
Zwycięstwo modeli zespołowych
Autorzy rygorystycznie przetestowali wszystkie metody w sześciu scenariuszach. W pięciu „co by było gdy” celowo ukrywali fragmenty w przeciwnie kompletnych zapisach i oceniali, jak dobrze każdy model potrafi odtworzyć brakujące wartości. W ostatnim, rzeczywistym przypadku poprosili modele o wypełnienie faktycznych braków na stacji E, używając danych sąsiadów. W tych testach najprostsza metoda prostoliniowa wypadła najgorzej, podczas gdy standardowe modele uczenia maszynowego radziły sobie znacznie lepiej, redukując błąd mniej więcej o połowę. Drzewa decyzyjne, które automatycznie dzielą dane na bardziej jednorodne grupy, przyniosły dalszą poprawę. Jednak wyraźnym zwycięzcą okazał się ensemble XGBoost: przez budowanie setek drzew, z których każde koryguje błędy poprzednich, osiągnął wyjątkowo niski błąd i niemal doskonałe dopasowanie przewidywanych i zmierzonych wartości przewodności właściwej. Jego rekonstrukcje dokładnie odwzorowywały obserwowane szeregi czasowe i reprodukowały ogólne właściwości statystyczne zapisów jakości wody.
Co to oznacza dla wybrzeży i nie tylko
Dla osób niebędących specjalistami przesłanie jest proste: starannie zaprojektowana sztuczna inteligencja potrafi wiarygodnie wypełniać brakujące fragmenty zapisów jakości wód przybrzeżnych, zwłaszcza gdy dostępne są dane z pobliskich stacji dających kontekst. Choć zaawansowane sieci neuronowe są potężne, to badanie pokazuje, że metody zespołowe oparte na drzewach, takie jak XGBoost, są jeszcze dokładniejsze i w praktyce mogą być najlepszym wyborem do naprawy zbiorów danych środowiskowych. Dysponując solidnymi narzędziami do wypełniania luk, naukowcy mogą lepiej śledzić subtelne zmiany zasolenia przybrzeża, identyfikować zdarzenia zanieczyszczeniowe i wspierać decyzje zarządcze bez bycia wytrąconym z równowagi przez nieuchronne awarie czujników. Te same strategie można adaptować do wielu innych problemów inżynieryjnych i środowiskowych, gdzie strumienie danych są bogate, hałaśliwe i sporadycznie niekompletne.
Cytowanie: Mahdavi-Meymand, A., Sulisz, W. & Nandan Bora, S. Application of swarm-based deep neural networks and ensemble models for reconstruction of specific conductance data. Sci Rep 16, 7292 (2026). https://doi.org/10.1038/s41598-026-38136-z
Słowa kluczowe: jakość wód przybrzeżnych, przewodność właściwa, uczenie maszynowe, rekonstrukcja brakujących danych, XGBoost