Clear Sky Science · pl
Techniki budowy i zaawansowanej ekstrakcji grafu wiedzy opartego na dużych modelach językowych
Mądrzejsze mapy do złożonych decyzji
Współczesne decyzje w obszarach o wysokiej stawce — takich jak operacje na dużą skalę, zarządzanie infrastrukturą czy reagowanie kryzysowe — wymagają szybkiego zrozumienia ogromnych ilości rozproszonych informacji. Instrukcje, strumienie danych z czujników, raporty i symulacje opisują fragmenty obrazu, ale rzadko są zorganizowane w sposób użyteczny dla ludzi lub systemów komputerowych. W artykule przedstawiono sposób przekształcenia tej pofragmentowanej wiedzy w żywe «mapy wiedzy» napędzane przez duże modele językowe, dzięki czemu planiści i analitycy mogą zadawać lepsze pytania i otrzymywać szybsze, bardziej wiarygodne odpowiedzi.
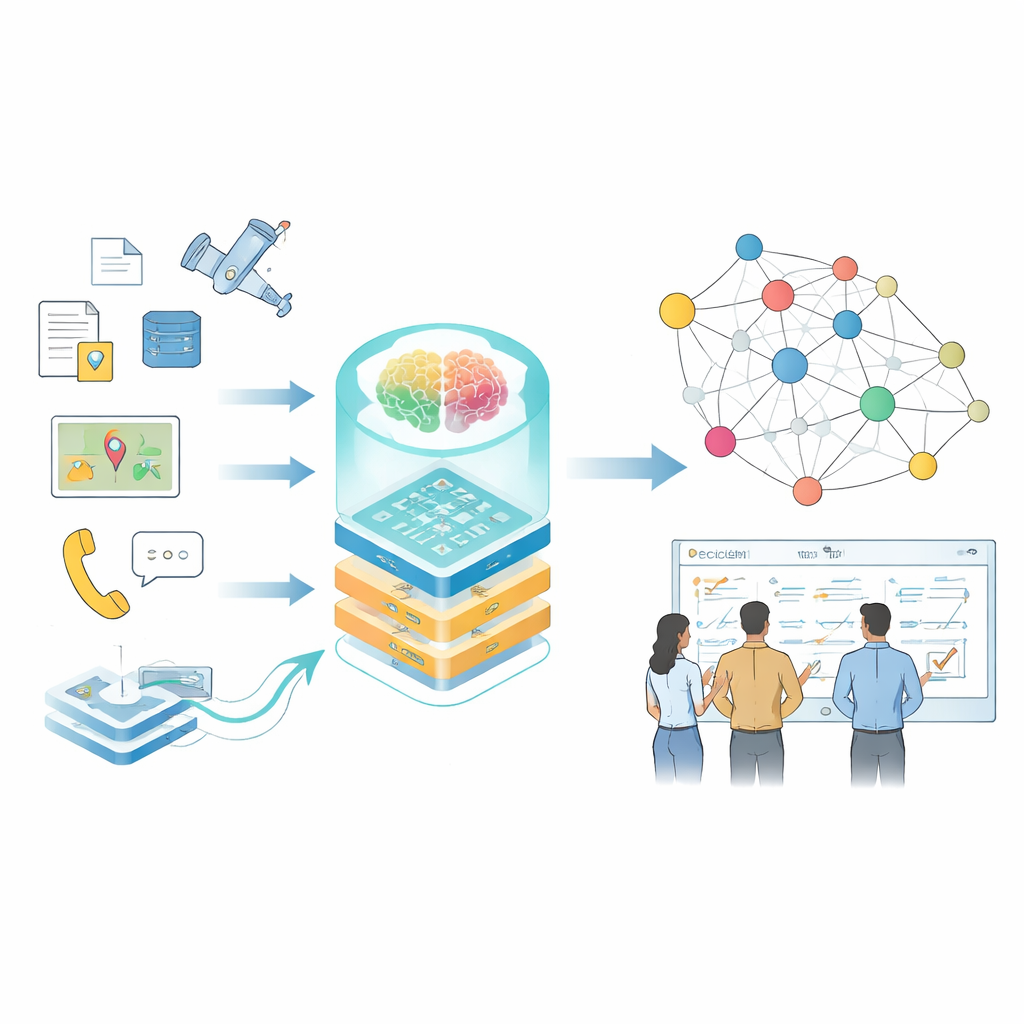
Od rozsianych faktów do połączonej wiedzy
Autorzy koncentrują się na grafach wiedzy — sposobie reprezentacji informacji jako sieci połączonych faktów: kto zrobił co, z jakim systemem, w jakich warunkach. W codziennych zastosowaniach takie grafy napędzają już wyszukiwarki czy systemy rekomendacyjne, ale specjalistyczne dziedziny stawiają trudniejsze wyzwania: dane są wrażliwe, terminologia gęsta, formaty wahają się od swobodnych raportów po logi z czujników, a warunki zmieniają się szybko. Tradycyjne narzędzia oparte na regułach pisanych ręcznie lub małych modelach mają trudności z nadążaniem, a modele ogólnego przeznaczenia często błędnie interpretują terminy techniczne lub pomijają subtelne relacje istotne dla decyzji w świecie realnym.
Nauczanie dużych modeli językowych nowej specjalizacji
Aby temu sprostać, badanie dopracowuje potężny model bazowy za pomocą starannie zaprojektowanego, specyficznego dla domeny zestawu danych. Zestaw ten czerpie z komunikatów dowodzenia, instrukcji obsługi sprzętu, scenariuszy symulowanych oraz literatury eksperckiej. Zanim jakikolwiek materiał trafi do modelu, jest silnie desensytyzowany: konkretne współrzędne stają się względnymi lokalizacjami, nazwy jednostek zamieniane są na ogólne kody, a wrażliwa logika jest częściowo maskowana przy zachowaniu ogólnych wzorców. Dane przechowywane są w ustrukturyzowanym formacie opisującym szerszą sytuację, konkretne zadania (takie jak planowanie, priorytetyzacja zagrożeń czy odpowiadanie na pytania) oraz powiązania między nimi. Ta struktura pozwala modelowi uczyć się nie tylko pojedynczych faktów, lecz także tego, jak różne zadania dzielą kontekst.
Warstwy adaptacji dla różnych zadań
Zamiast ponownego trenowania każdego parametru modelu językowego — co jest kosztowne i ryzykowne — autorzy stosują technikę zwaną adaptacją niskiego rzędu, zorganizowaną w kilka warstw, z których każda skupia się na innym aspekcie problemu. Jedna warstwa przechwyci podstawową terminologię i pojęcia, inna osadzi zasady operacyjne i ograniczenia, a trzecia wyspecjalizuje się w dostosowaniu do konkretnych zadań, takich jak planowanie czy ocena zagrożeń. Osobny komponent kontrolny, sieć „trasująca”, analizuje każdy fragment wejścia i decyduje, jaką kombinację tych lekkich adapterów model powinien zastosować. Ten projekt pozwala systemowi sprawnie przełączać się między zadaniami, zachowując jednocześnie ogólne zdolności językowe i wiedzę specyficzną dla domeny.
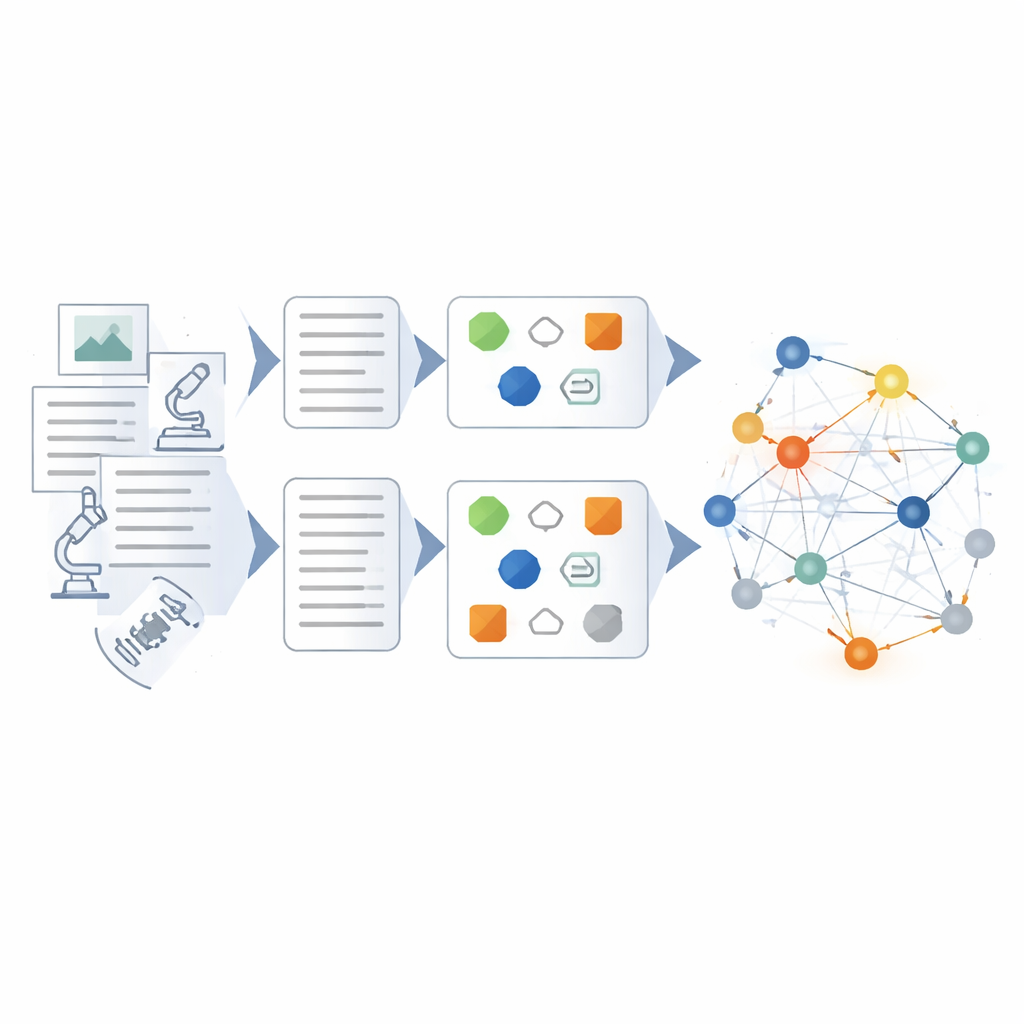
Budowanie i weryfikacja sieci wiedzy
Na szczycie dostrojonego modelu autorzy projektują hybrydowy pipeline do budowy samego grafu wiedzy. Najpierw surowe dane są czyszczone i standaryzowane, aby terminy i formaty były spójne. Następnie metody oparte na regułach i szablony stworzone przez ekspertów wydobywają oczywiste byty i zdarzenia. Dopracowany model językowy przejmuje bardziej złożone zadania: skracanie chaotycznych raportów do zwięzłych streszczeń, identyfikowanie kluczowych aktorów i sprzętu oraz wnioskowanie relacji, takich jak łańcuchy przyczynowo‑skutkowe czy koordynacja między jednostkami. Każdy wydobyty fakt jest oceniany z kilku perspektyw — jak dobrze pasuje do znanych wzorców, jak silnie łączy się z innymi faktami oraz czy zgadza się ze ścieżkami wieloetapowego rozumowania w grafie. Tylko wyniki o wysokim poziomie ufności są dodawane, a te o niskiej ufności oznaczane do przeglądu.
Udowodnione zyski w dokładności i niezawodności
Zespół ocenia swoje podejście na trzech podstawowych zadaniach odzwierciedlających potrzeby praktyczne: odpowiadanie na złożone pytania dotyczące reguł i wyposażenia, proponowanie planów działania dla danej sytuacji oraz klasyfikowanie różnych scenariuszy zagrożeń pod względem powagi. W tych zadaniach model dostosowany systematycznie przewyższa znane systemy ogólnego przeznaczenia, w tym modele graniczne trenowane na znacznie bardziej ogólnych danych. Odpowiada na większą liczbę pytań poprawnie, generuje bardziej realistyczne plany i dokładniej ocenia zagrożenia. Powstały graf wiedzy jest zarówno rozległy, jak i gęsto połączony — ponad 90 procent zapisanych faktów przechodzi surowe kontrole ufności i pomaga planistom szybciej podejmować trafne decyzje.
Dlaczego to ma znaczenie w przyszłości
Dla czytelnika niebędącego specjalistą kluczowy przekaz jest taki, że modele językowe można przekształcić z gładkich „rozmówców” w ostrożnych, wyspecjalizowanych analityków — jeśli trenuje się je na odpowiednich danych, ogranicza wyraźnymi regułami i stale kontroluje jakość. Praca pokazuje, jak osiągnąć to w wrażliwej, szybko zmieniającej się dziedzinie, jednocześnie chroniąc informacje prywatne. Ramy te nie tylko organizują rozproszoną wiedzę w użyteczną sieć, ale także utrzymują tę sieć aktualną i godną zaufania, oferując wzorzec dla przyszłych systemów wspierających decyzje w każdej dziedzinie, gdzie trafne podejmowanie złożonych decyzji ma kluczowe znaczenie.
Cytowanie: Peng, L., Yang, P., Juexiang, Y. et al. The construction and refined extraction techniques of knowledge graph based on large language models. Sci Rep 16, 8104 (2026). https://doi.org/10.1038/s41598-026-38066-w
Słowa kluczowe: graf wiedzy, duży model językowy, wsparcie decyzji, dostosowanie do domeny, desensytyzacja danych