Clear Sky Science · pl
Generowanie granicznych próbek testowych do testerów losowości za pomocą inteligentnej optymalizacji i algorytmów ewolucyjnych
Dlaczego prawie-losowe ma znaczenie dla bezpieczeństwa codziennego użytku
Za każdym razem, gdy robisz zakupy online, odblokowujesz telefon czy wysyłasz prywatną wiadomość, niewidzialne matematyczne kości są rzucane, by chronić Twoje dane. Te „kości” przyjmują postać długich ciągów rzekomo losowych bitów używanych jako klucze kryptograficzne. Jeśli te bity są choćby nieznacznie mniej losowe niż powinny być, zdeterminowani napastnicy mogą czasem wykryć wzorce do wykorzystania. Artykuł bada nowy sposób wytwarzania „prawie-losowych” sekwencji testowych — danych, które wyglądają na niezwykle losowe, ale ukrywają drobne wady — tak by inżynierowie mogli rzetelnie przeciążyć urządzenia chroniące nasze cyfrowe życie.
Kiedy liczby losowe nie są wystarczająco losowe
Nowoczesne systemy bezpieczeństwa opierają się na dwóch typach generatorów liczb losowych. Prawdziwe generatory losowości czerpią z nieprzewidywalnych zjawisk fizycznych, takich jak szum elektroniczny czy fluktuacje kwantowe, podczas gdy generatory pseudolosowe używają algorytmów, które rozszerzają krótkie, losowe ziarna na długie ciągi. W praktyce jakość obu rodzajów ostatecznie zależy od fizycznego źródła nieprzewidywalności, zwanego źródłem entropii. Niestety, rzeczywiste źródła entropii są podatne: zmiany temperatury, starzenie się sprzętu czy błędy projektowe mogą po cichu zmniejszyć ich losowość. Aby wykryć takie problemy, organy standaryzacyjne, jak NIST, definiują zestawy testów statystycznych sprawdzających, czy wychodzące bity wyglądają wystarczająco losowo. Urządzenia coraz częściej wbudowują „testerów losowości w czasie rzeczywistym”, którzy monitorują własne wyjście podczas działania. Jednak brakowało dobrego sposobu na wygenerowanie realistycznych, trudnych do wykrycia przypadków awarii, by sprawdzić, czy te wbudowane kontrolery rzeczywiście działają.
Projektowanie sekwencji, które ledwie nie przechodzą testów losowości
Z punktu widzenia testera trywialne awarie — na przykład wyjścia składające się z samych zer — są łatwe do wykrycia. Prawdziwe wyzwanie stanowią przypadki brzegowe: sekwencje niemal nieodróżnialne od idealnej losowości, które jednak nieznacznie nie przechodzą jednego lub kilku testów statystycznych. Autorzy koncentrują się na pięciu klasycznych testach analizujących różne aspekty wzorców bitów, w tym częstość występowania zer i jedynek, zachowanie par bitów, rozkład pewnych krótkich wzorców, korelacje bitów z ich przesuniętymi kopiami oraz długości przebiegów identycznych bitów. Dla każdego testu definiują „strefę brzegową”: wąski pas, w którym dane jedynie nieznacznie naruszają zwykłe progi akceptacji. Wytworzenie długiej sekwencji, która jednocześnie trafia we wszystkie te wąskie pasma, jest skrajnie nieprawdopodobne przypadkowo, ponieważ testy oddziałują ze sobą w skomplikowany, nieliniowy sposób. Tutaj wkracza optymalizacja i sztuczna inteligencja.
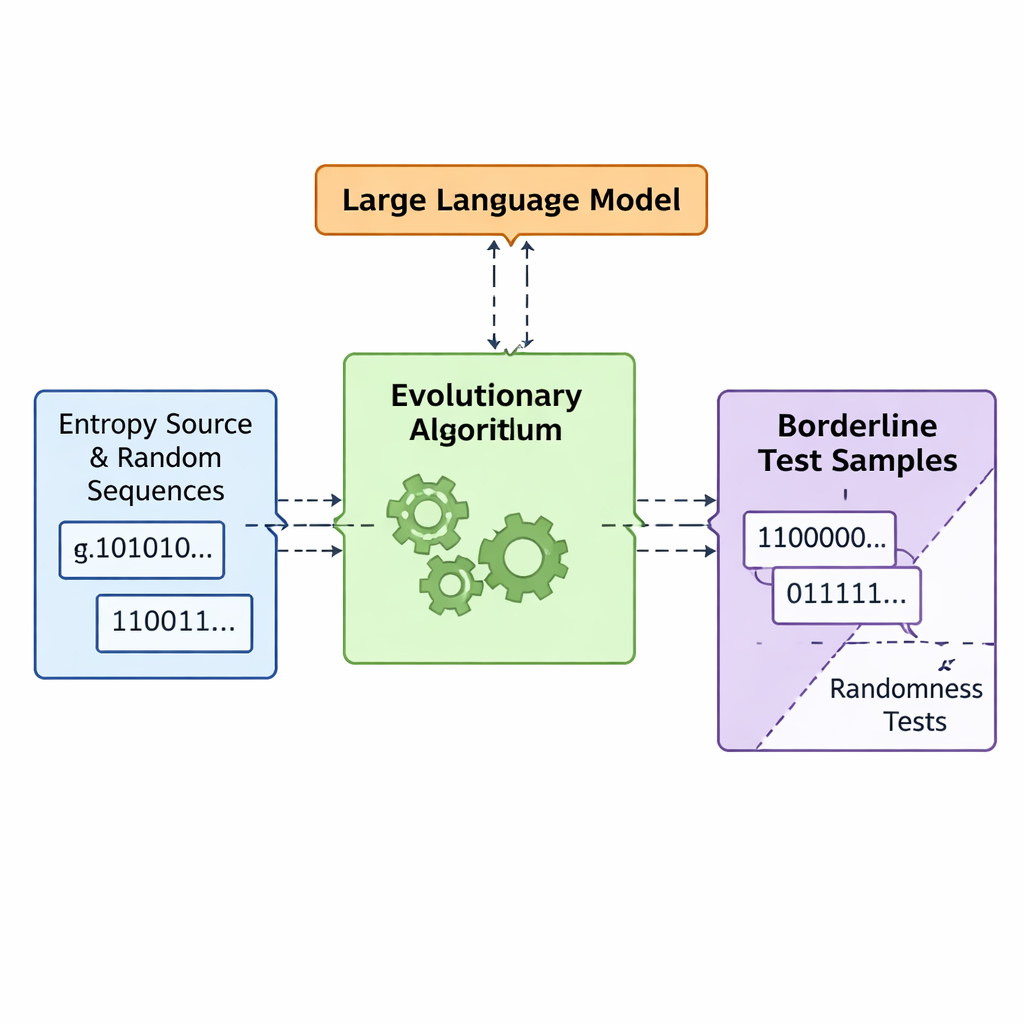
Pozwól ewolucji i modelom językowym współprojektować złą losowość
Zespół przedstawia ramy nazwane APAM‑IGLLM, które traktują generowanie sekwencji jako problem optymalizacji w wysokim wymiarze. Każda kandydacka sekwencja to ciąg bitów, a jej „przystosowanie” mierzy, jak blisko znajduje się ona stref brzegowych pięciu testów. Algorytm genetyczny wielokrotnie mutuje i rekombinuje te sekwencje, zatrzymując te, które zbliżają się do docelowego regionu. Na to nakłada się duży model językowy (LLM), który pełni rolę swego rodzaju trenera strategicznego. W każdej generacji analizuje statystyki zbioru i krótkoterminową historię, a następnie sugeruje, jak dostosować wewnętrzne pokrętła — wagi i współczynniki skalujące decydujące, jak silnie każdy test wpływa na funkcję przystosowania. To tworzy pętlę sprzężenia zwrotnego: algorytm genetyczny eksploruje przestrzeń możliwych sekwencji, podczas gdy LLM steruje poszukiwaniem tak, by wyniki wszystkich pięciu testów zbiegały się ku maleńkiemu przecięciu, gdzie sekwencje są ledwie nielosowe.
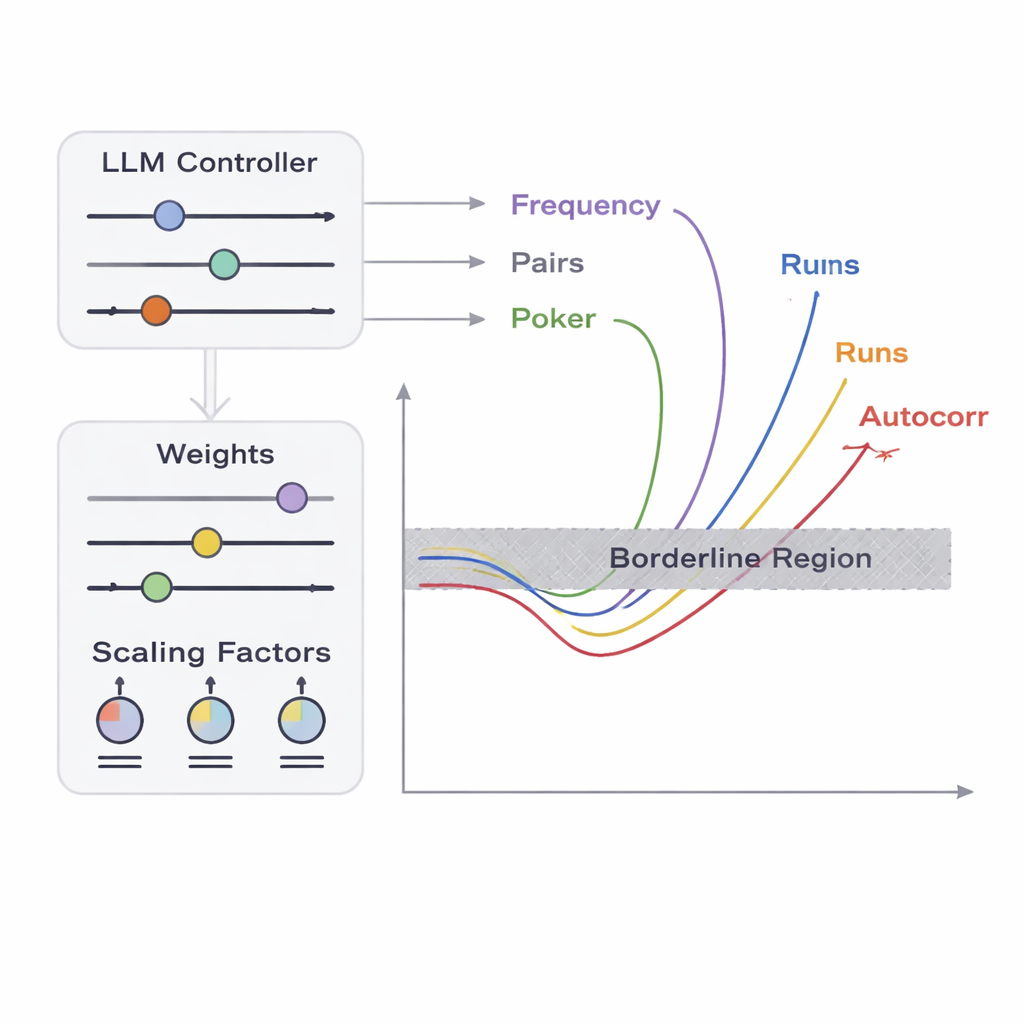
Jak blisko doskonałej losowości mogą wyglądać wadliwe dane?
Aby sprawdzić, czy ich sztuczne wady wyglądają realistycznie, autorzy porównują wygenerowane sekwencje z powszechnie używanymi punktami odniesienia. Obliczają zarówno entropię Shannona, jak i min‑entropię — miary tego, jak nieprzewidywalny wydaje się każdy bajt — i znajdują wartości rzędu 7,6–8 bitów na bajt, bardzo bliskie teoretycznemu maksimum 8 i podobne do komercyjnych źródeł losowości w sprzęcie oraz publicznego beacona losowości NIST. Uruchamiają też pełny zestaw testów statystycznych NIST SP 800‑22 i obserwują, że ich sekwencje brzegowe przechodzą i nie przechodzą testów w niemal tym samym wzorcu co autentyczne, wysokiej jakości dane losowe. Innymi słowy, dla standardowych narzędzi te próbki wyglądają zasadniczo normalnie, choć zostały celowo zaprojektowane tak, by znajdować się blisko wielu progów awarii. Czyni to z nich idealne „antagonistyczne” wejścia do sprawdzania, jak odporne są wbudowane testery losowości.
Co to oznacza dla bezpieczeństwa w świecie rzeczywistym
Z punktu widzenia laika praca ta oferuje nowy sposób sprawdzania bezpieczeństwa maszynerii liczb losowych, która leży u podstaw szyfrowania. Zamiast testować urządzenia tylko za pomocą wyraźnie uszkodzonej lub wyraźnie zdrowej losowości, inżynierowie mogą teraz zasypywać je starannie przygotowanymi, prawie‑dobrymi sekwencjami, które naśladują subtelne usterki sprzętowe lub dryf środowiskowy. Jeśli tester losowości w czasie rzeczywistym nie wykryje tych przypadków brzegowych, sygnalizuje to potencjalną ślepą plamę, którą należy usunąć przed wdrożeniem urządzenia w systemach bankowych, komunikacji bezpiecznej czy blockchain. Poprzez użycie poszukiwań ewolucyjnych kierowanych przez model językowy, autorzy dostarczają praktyczne narzędzie do generowania takich wymagających danych testowych, pomagając przesunąć ukryte fundamenty bezpieczeństwa cyfrowego w stronę wyższej niezawodności.
Cytowanie: Gao, P., Zhang, B., Wang, Z. et al. Generating borderline test samples for randomness testers via intelligent optimization and evolutionary algorithms. Sci Rep 16, 7268 (2026). https://doi.org/10.1038/s41598-026-38020-w
Słowa kluczowe: generatory liczb losowych, źródła entropii, algorytmy ewolucyjne, duże modele językowe, testy kryptograficzne