Clear Sky Science · pl
Fuzzy C-means clustering based vertical container stacking in container terminals
Dlaczego inteligentniejsze układanie kontenerów ma znaczenie
Każdego roku prawie miliard zunifikowanych metalowych skrzyń — kontenerów — przepływa przez porty morskie na całym świecie. Szybkie załadunek i rozładunek tych skrzyń jest kluczowe dla utrzymania przepływu towarów i ograniczania kosztów. A jednak zadziwiająco prosty problem spowalnia operacje: kiedy potrzebny kontener jest zakopany pod niewłaściwymi, dźwigi muszą przestawiać stosy, tracąc czas i paliwo. W pracy tej przedstawiono nowy, oparty na danych sposób układania kontenerów według masy, który ogranicza kosztowne przestawienia, przyspieszając i stabilizując pracę portu bez potrzeby dodatkowej przestrzeni czy sprzętu.
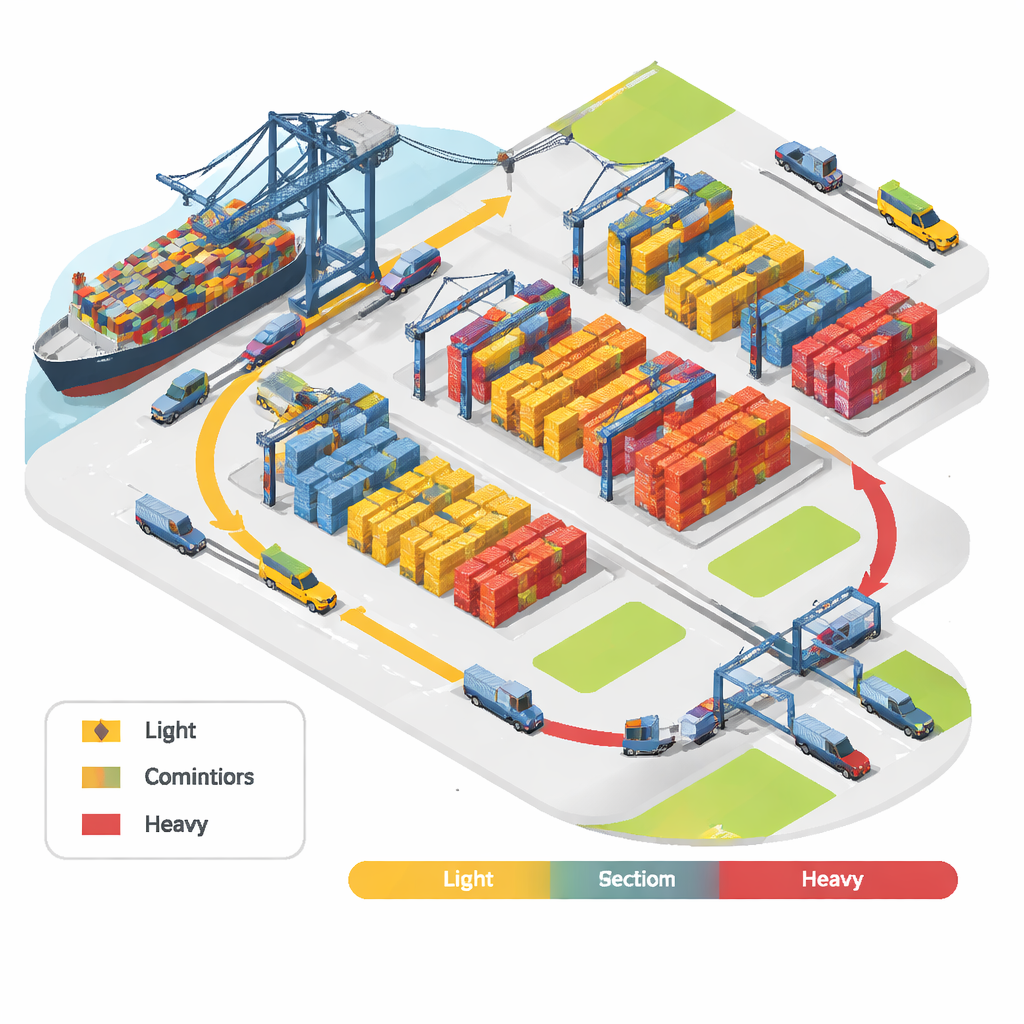
Ukryty problem bałaganu w stosach
Składy kontenerów z daleka wyglądają uporządkowanie, lecz kolejność, w jakiej kontenery trzeba załadować i rozładować, jest silnie niepewna. Kontenery wychodzące przyjeżdżają na terminal przed statkiem, a ich ostateczna kolejność załadunku zależy od zasad stabilności statku i zmieniających się planów rozmieszczenia. Cięższe kontenery zazwyczaj idą niżej w ładowni, lżejsze wyżej. Jednak gdy kontenery przybywają, operatorzy często nie wiedzą, czy dana skrzynia będzie ostatecznie „ciężka” czy „lekka” w kontekście całego ładunku. Tradycyjne strategie próbują priorytetować ciężkie kontenery lub przypisywać stałe kategorie wagowe, ale to łatwo może się zemścić: kontener uznany jednego dnia za ciężki może być następnego traktowany jako średni, co wymusza dodatkowe przestawienia przy załadunku statku.
Pionowe stosy i dlaczego równowaga wagowa się liczy
Porty stosują różne sposoby rozmieszczania kontenerów: obok siebie w rzędach (poziomo), grupując według podobnego typu w kolumnach (pionowo), albo hybrydowo. Niniejsze badanie skupia się na pionowym układaniu, gdzie kontenery o podobnych cechach umieszczane są w tej samej kolumnie-stosie. Układ pionowy jest atrakcyjny, ponieważ ułatwia dostęp do kontenera o z grubsza odpowiednim zakresie mas bez konieczności ruszania zbyt wielu innych. W praktyce liczba kontenerów w poszczególnych przedziałach wagowych zmienia się jednak z rejsu na rejs. Jeśli grupy wagowe definiuje się za pomocą sztywnych progów — powiedzmy co 5 ton — wiele kontenerów leżących blisko granic trafia do różnych stosów mimo niemal identycznej wagi. To zwiększa zróżnicowanie wag w stosach i zmniejsza korzyści z układu pionowego.
Pozwolić danym wyznaczać granice
Autorzy proponują nową strategię nazwaną Fuzzy C-means-based Vertical Sequence Stacking (FVSS). Zamiast z góry ustalać granice każdej grupy wagowej, metoda analizuje historyczne dane wagowe ze statków na tej samej trasie i pozwala algorytmowi rozmytego grupowania odnaleźć naturalne klastry. „Rozmyte” oznacza, że waga kontenera może częściowo przynależeć do kilku grup, co odzwierciedla brak ostrych granic między na przykład średnią a ciężką kategorią. Algorytm wybiera, ile klastrów najlepiej pasuje do danych z przeszłości danego statku i identyfikuje centrum wagowe dla każdego klastra. Plac jest następnie wstępnie podzielony na liczbę stosów proporcjonalną do liczby kontenerów, które zwykle przypadają na każdą grupę wagową, a każdemu stosowi przypisuje się wagę referencyjną opartą na tych centrach.
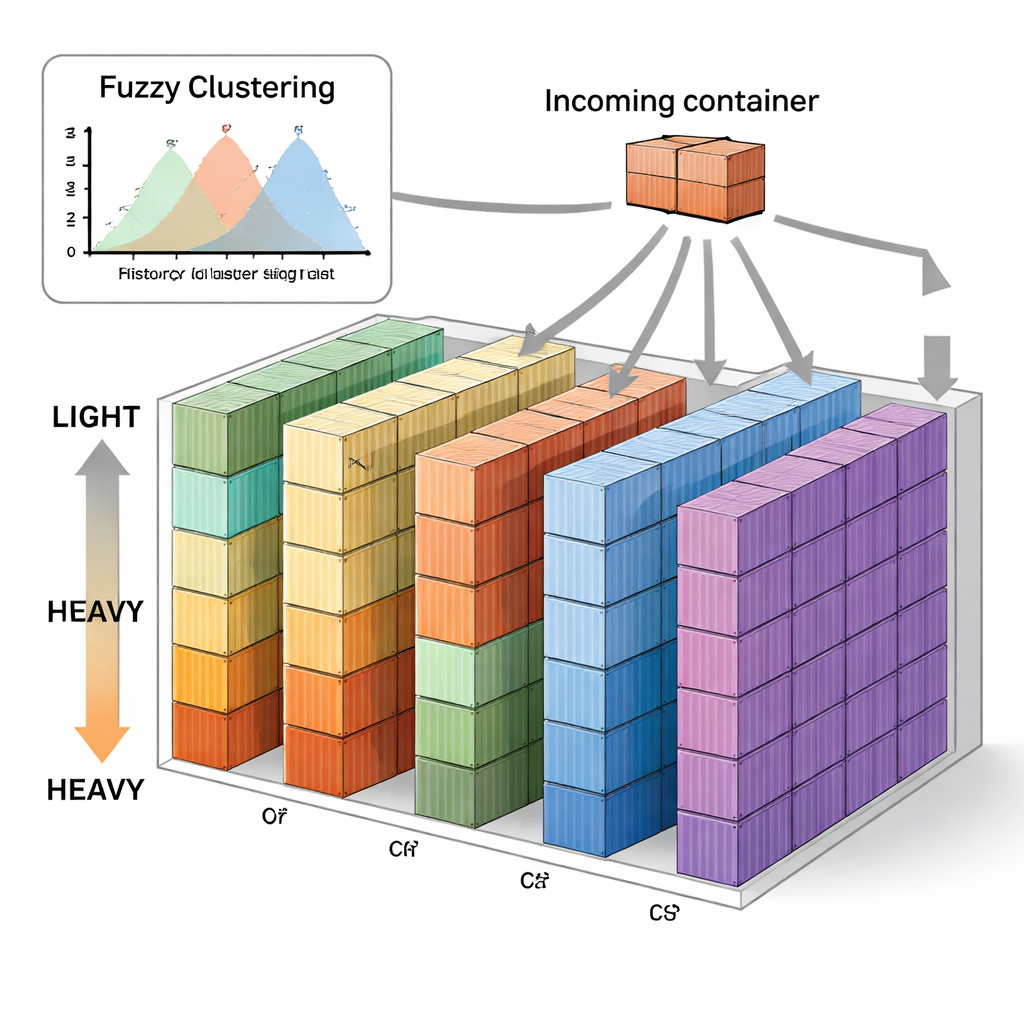
Proste reguły do decyzji w czasie rzeczywistym
Gdy plac zostanie w ten sposób skonfigurowany, codzienne operacje przebiegają według prostej reguły. Wraz z przybyciem każdego kontenera jego przybliżona klasa wagowa określana jest za pomocą rozmytych klastrów. Jeśli w stosach zarezerwowanych dla tej klasy jest wolne miejsce, kontener trafia tam. Gdy te stosy są pełne lub dostępnych jest kilka opcji, system wybiera stos, którego waga referencyjna jest najbliższa rzeczywistej wadze kontenera. W miarę upływu czasu delikatnie kieruje to kontenery o podobnej wadze do tych samych stosów bez potrzeby skomplikowanej optymalizacji czy stałego trenowania modeli uczenia maszynowego. Autorzy przetestowali podejście na dziesięciu miesiącach rzeczywistych danych z terminalu kontenerowego w Busan w Korei, porównując je z kilkoma znanymi metodami, w tym losowym układaniem, strategią hybrydową poziomo–pionowo oraz wcześniejszymi technikami opartymi na mieszankach Gaussa i uczeniu online.
Co wyniki oznaczają dla portów
Kluczowym wskaźnikiem w badaniu była zmienność wag kontenerów wewnątrz każdego stosu — mniejsze rozproszenie oznacza łatwiejsze znalezienie odpowiednich kontenerów podczas załadunku statku przy mniejszej liczbie przestawień. Dla wielu statków i dwóch konfiguracji placu (5 i 10 stosów) strategia FVSS zmniejszyła wariancję wag znacznie bardziej niż konkurencyjne podejścia, z poprawą sięgającą do 78% w porównaniu z losowym układaniem i istotnymi korzyściami względem innych zaawansowanych metod. Co istotne, wydajność pozostała wysoka nawet gdy badacze celowo zniekształcali wagi kontenerów, by naśladować błędy i zmiany w ostatniej chwili. Dla operatorów portowych oznacza to możliwość płynniejszej pracy dźwigów i krótszych czasów obsługi statków dzięki zautomatyzowanemu, ale przejrzystemu zestawowi reguł, który można łatwo aktualizować po zakończeniu kolejnych rejsów, bez inwestycji w rozbudowaną infrastrukturę obliczeniową czy skomplikowane systemy uczące się.
Cytowanie: Lee, S., Lee, SH., Choi, S.C. et al. Fuzzy C-means clustering based vertical container stacking in container terminals. Sci Rep 16, 6891 (2026). https://doi.org/10.1038/s41598-026-37994-x
Słowa kluczowe: terminale kontenerowe, układanie na placu, rozmyte grupowanie, logistyka morska, efektywność operacyjna