Clear Sky Science · pl
Korygowanie zaszumionych etykiet przez destylację porównawczą: podejście adaptacji dziedziny
Dlaczego bałagan w danych staje się rosnącym problemem
Nowoczesna sztuczna inteligencja rozwija się dzięki danym, lecz te dane często są błędne, niekompletne lub niespójnie oznaczone. Gdy etykiety są zaszumione — na przykład zdjęcie kota oznaczone jako pies — systemy uczące się mogą zostać wprowadzone w błąd, tracąc na dokładności i niezawodności. Ten artykuł zajmuje się tym praktycznym problemem: jak trenować systemy rozpoznawania obrazów, które wciąż działają dobrze nawet jeśli etykiety treningowe są wadliwe, a obrazy pochodzą z różnych środowisk, na przykład sklepów internetowych versus zdjęć z rzeczywistego świata.
Uczenie się między różnymi światami
W praktyce modele AI często uczą się w „źródłowym” świecie, gdzie etykiety są starannie sprawdzane, a następnie muszą działać w „docelowym” świecie, gdzie etykiety są rzadkie i podatne na błędy. Na przykład obiekty biurowe fotografowane w studiu są uporządkowane i poprawnie oznaczone, podczas gdy zdjęcia tych samych przedmiotów z kamerek internetowych lub codzienne zdjęcia są chaotyczne i niespójnie tagowane. Tradycyjne metody adaptacji dziedziny próbują zmniejszyć tę przepaść przez wyrównanie ogólnych statystyk obu światów. Jednak zwykle zakładają, że etykiety w zbiorze docelowym, jeśli są dostępne, są poprawne — ryzykowne założenie, które zawodzi w rzeczywistych zastosowaniach z etykietami tworzonymi przez tłum, niskiej jakości sensorami czy automatycznymi narzędziami adnotacji.
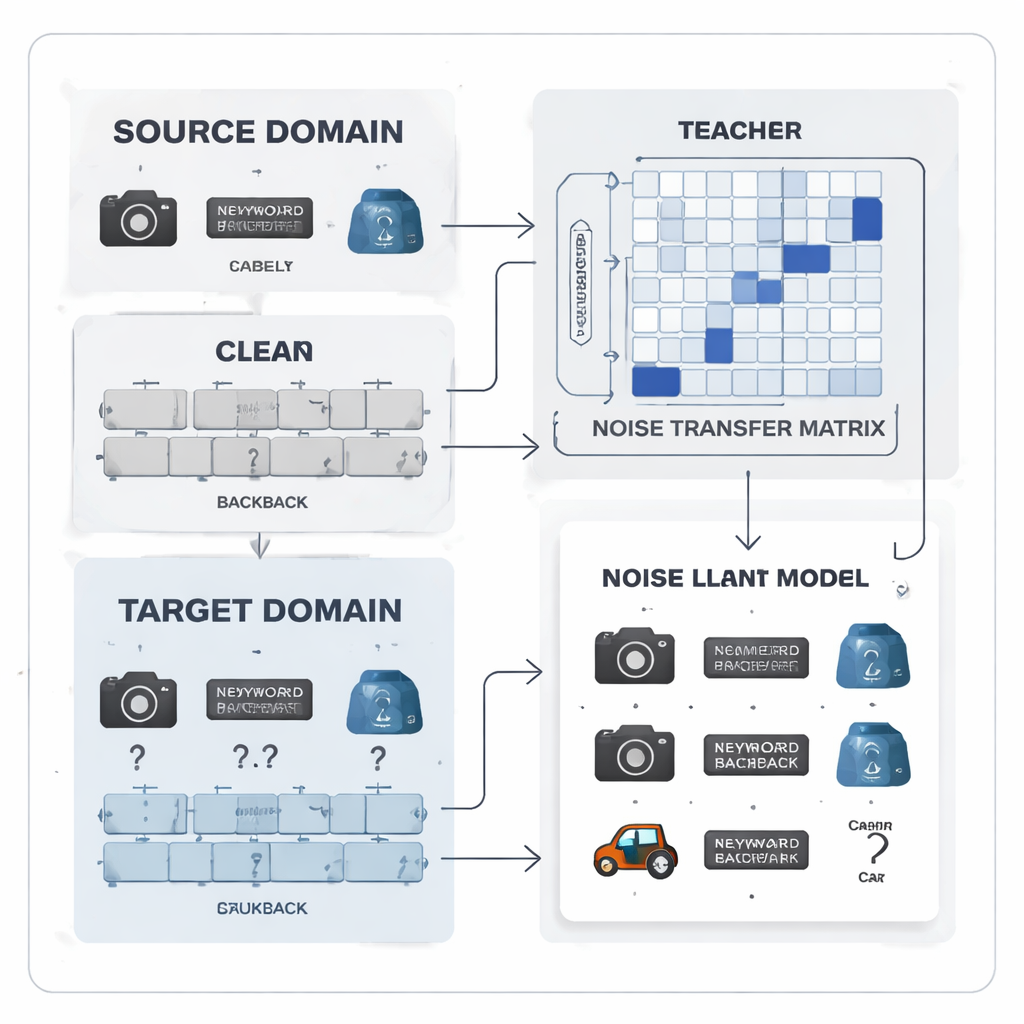
Przekształcanie błędów etykiet w wzorzec możliwy do nauki
Autorzy proponują traktować szum etykiet nie jako przypadkowy chaos, lecz jako wzorzec możliwy do nauki. Wprowadzają „macierz transferu szumu”, tablicę opisującą, jak prawdopodobne jest, że każda prawdziwa klasa zostanie błędnie oznaczona jako inna. Zamiast szacować tę macierz z garstki idealnych „kotwicowych” przykładów — co jest nierealistyczne, gdy etykiety są zaszumione i klasy niezrównoważone — macierz jest uczona bezpośrednio podczas treningu. Aby przyspieszyć naukę, metoda buduje „protokoły” kategorii, uśrednione odciski cech dla każdej klasy wyodrębnione przez silny, wstępnie wytrenowany model. Podobieństwo między tymi prototypami służy do zainicjowania macierzy, tak że kategorie łatwe do pomylenia, np. podobne narzędzia biurowe, są od początku silniej powiązane, dając systemowi wczesną zdolność do korygowania etykiet.
Współpraca nauczyciela i ucznia dla czyściejszych sygnałów
W centrum systemu znajduje się para sieci neuronowych nauczyciel–uczeń. Nauczyciel bazuje na dużym modelu wizji uczonym samodzielnie (self‑supervised), który pozyskał bogate cechy wizualne z masy niesygnalizowanych danych. Uczeń to lżejsza sieć, która musi dobrze działać na zaszumionych danych docelowych. Nauczyciel generuje miękkie wyniki predykcji, które ujawniają, jak klasy są powiązane; z tych wyników metoda konstruuje macierz korelacji klas podsumowującą, które etykiety mają tendencję do współwystępowania. Ta macierz działa jako przewodnik, nakłaniając macierz transferu szumu do bardziej realistycznych korekt. Jednocześnie uczeń uczy się naśladować zachowanie nauczyciela poprzez proces znany jako destylacja, a uczenie kontrastowe zachęca obie sieci, by nadawały podobne wewnętrzne reprezentacje różnym augmentowanym widokom tego samego obrazu i odrębne reprezentacje różnym obiektom.
Utrzymywanie stabilności korekt i unikanie nadmiernej pewności
Pozwolenie macierzy transferu szumu na swobodne zmiany mogłoby uczynić ją niestabilną lub nadmiernie wrażliwą na obserwacje odstające. Aby temu zapobiec, autorzy stosują matematyczny trik oparty na rozkładzie wartości osobliwych (SVD), który rozbija macierz na podstawowe kierunki rozciągania. Poprzez karanie ogólnego „wolumenu” wynikającego z tych kierunków, metoda zniechęca do ekstremalnych zniekształceń, które wzmacniałyby szum. Kolejny problem pojawia się, gdy model staje się zbyt pewny siebie, przypisując niemal całą prawdopodobieństwo jednej klasie; przy tak ostrych predykcjach trudno jest skorygować błędne etykiety. Aby to rozwiązać, metoda dodaje formę regularizacji entropii opartą na entropii Tsallisa, która utrzymuje prawdopodobieństwa predykcji bardziej wygładzonymi. Ułatwia to macierzy transferu szumu częściowe przekierowywanie masy prawdopodobieństwa z niepoprawnej klasy do bardziej prawdopodobnych alternatyw.
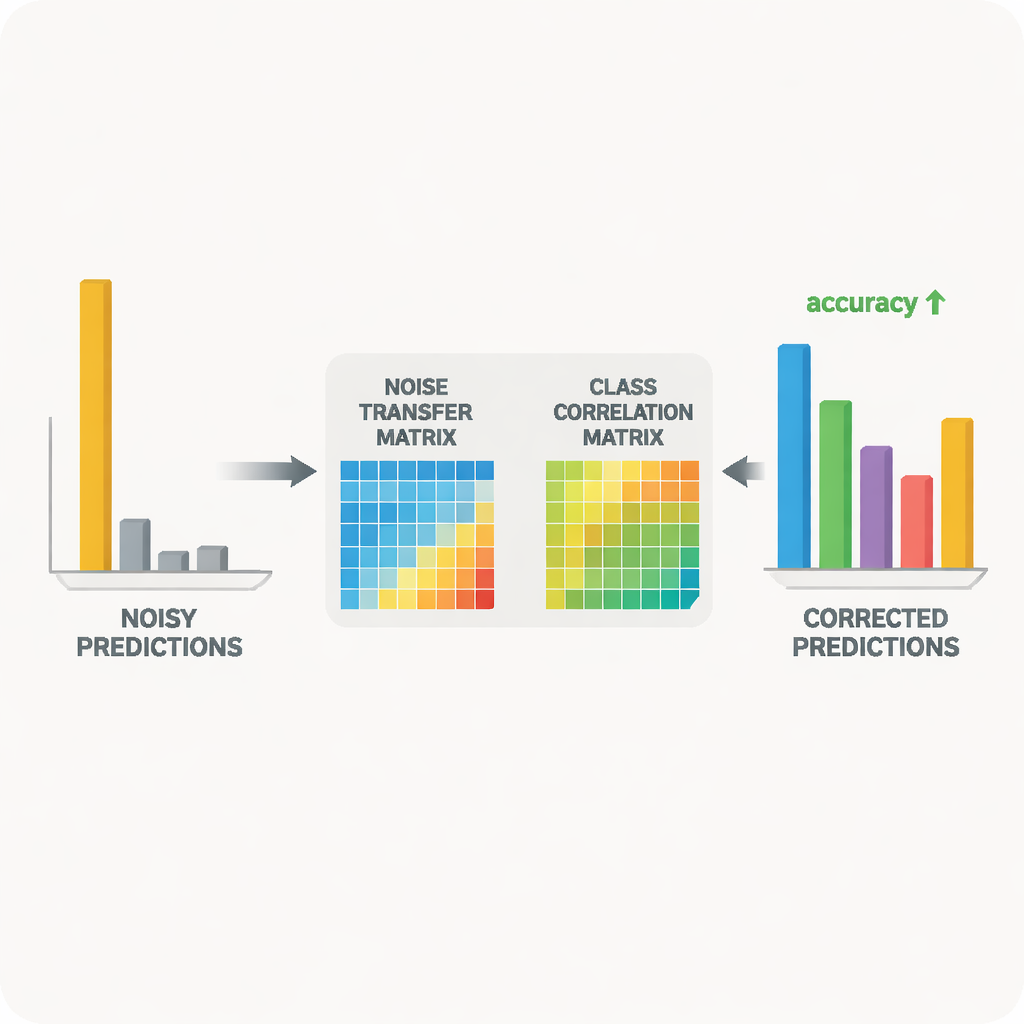
Weryfikacja pomysłu na rzeczywistych zbiorach obrazów
Badacze przetestowali swoje podejście na dwóch powszechnie stosowanych benchmarkach do rozpoznawania obiektów między dziedzinami: Office‑31 i Office‑Home, które zawierają obrazy codziennych przedmiotów biurowych w różnych stylach, takich jak zdjęcia produktowe, grafiki i rzeczywiste migawki. W różnych zadaniach „trenuj na jednym stylu, testuj na innym” ich metoda dorównała lub przewyższyła wiodące algorytmy, szczególnie w najtrudniejszych przypadkach, gdzie przesunięcie między dziedzinami jest największe. Szczegółowe badania wykazały, że każdy składnik — kontrola wolumenu macierzy szumu, przewodnictwo korelacji klas oraz wygładzanie entropii — wnosił mierzalne korzyści. Wizualizacje wyuczonej macierzy i przestrzeni cech potwierdziły, że w trakcie treningu błędnie oznaczone przykłady były stopniowo przesuwane w kierunku prawidłowych kategorii, a rozkłady obrazów źródłowych i docelowych ulegały lepszemu wyrównaniu.
Co to oznacza dla codziennych systemów AI
Dla niespecjalisty kluczowy wniosek jest taki, że ta praca sprawia, iż modele AI są bardziej wyrozumiałe wobec błędów ludzkich i maszynowych w etykietowaniu danych, zwłaszcza gdy modele muszą przenosić się z czystych warunków laboratoryjnych do bardziej chaotycznych środowisk rzeczywistych. Dzięki jawnej nauce, w jaki sposób etykiety mają tendencję do błędów, oraz wykorzystaniu potężnego modelu‑nauczyciela do kierowania korekt, metoda potrafi oczyścić zaszumione sygnały treningowe i dostarczyć dokładniejsze, bardziej odporne klasyfikatory. Choć podejście wymaga dodatkowych obliczeń, wskazuje na przyszłość, w której duże, niedoskonałe zbiory danych zbierane „w naturze” można bezpieczniej i skuteczniej wykorzystać, zmniejszając zależność od żmudnej ręcznej adnotacji.
Cytowanie: Feng, Y., Liu, J. & Zhong, H. Correcting noisy labels via comparative distillation: a domain adaptation approach. Sci Rep 16, 7422 (2026). https://doi.org/10.1038/s41598-026-37935-8
Słowa kluczowe: zaszumione etykiety, adaptacja dziedziny, destylacja wiedzy, klasyfikacja obrazów, uczenie półnadzorowane