Clear Sky Science · pl
Ryzykowno-czułe podwójne krytyki dystrybucyjne z lambdowym dolnym przedziałem ufności dla ciągłego sterowania w uczeniu przez wzmacnianie
Nauczanie robotów ostrożności
Wiele z najbardziej imponujących dziś robotów i programów do gier opiera się na uczeniu przez wzmacnianie — procesie uczenia metodą prób i błędów, w którym agenci programowi zdobywają doświadczenie poprzez otrzymywane nagrody. Jednak ci agenci często gonią za możliwie najwyższym wynikiem, ignorując ryzyko swoich decyzji, co prowadzi do niestabilnego uczenia i okazjonalnych awarii. W artykule zaproponowano metodę nazwaną TDC-λ (Twin Distributional Critics with a Lambda Lower Confidence Bound), która uczy takie agenty nie tylko celowania wysoko, ale też zachowania rzetelnego poziomu bezpieczeństwa podczas nauki.
Dlaczego stabilność ma znaczenie w maszynach uczących się
Standardowe algorytmy do ciągłego sterowania, takie jak szeroko stosowane TD3 i Soft Actor–Critic (SAC), pozwoliły robotom biegać, skakać i utrzymywać równowagę w złożonych symulatorach. Jednak te metody zwykle oceniają każdą akcję za pomocą jednej liczby: oszacowania, ile nagrody przyniesie ona w dłuższej perspektywie. Ten prosty wynik może wprowadzać w błąd, gdy proces uczenia jest hałaśliwy, powodując, że system przecenia wartość niektórych akcji. Efektem jest krzywa uczenia, która może wyglądać dobrze średnio, ale wachania między uruchomieniami są duże — co stanowi problem, jeśli ten sam algorytm ma sterować maszynami fizycznymi lub systemami krytycznymi dla bezpieczeństwa.
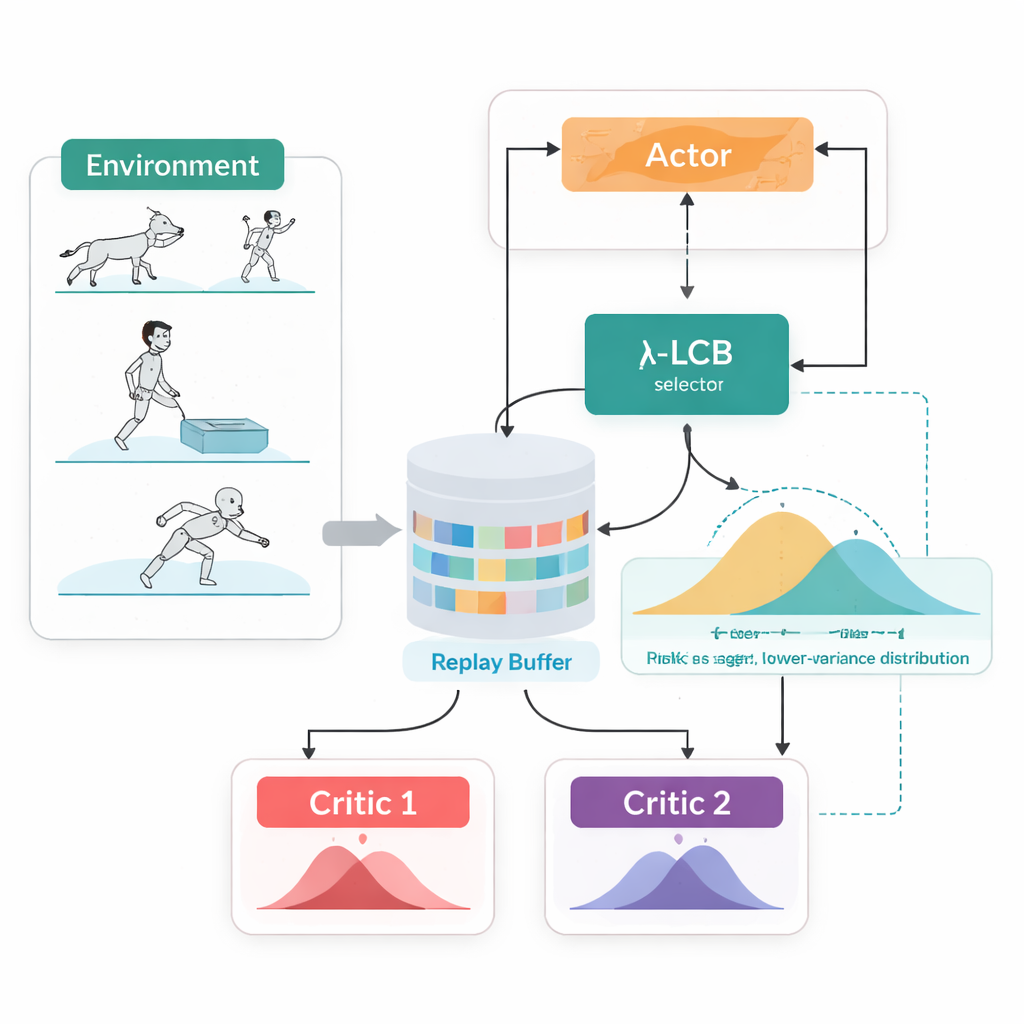
Patrzenie na pełne przyszłe rozkłady, nie pojedyncze liczby
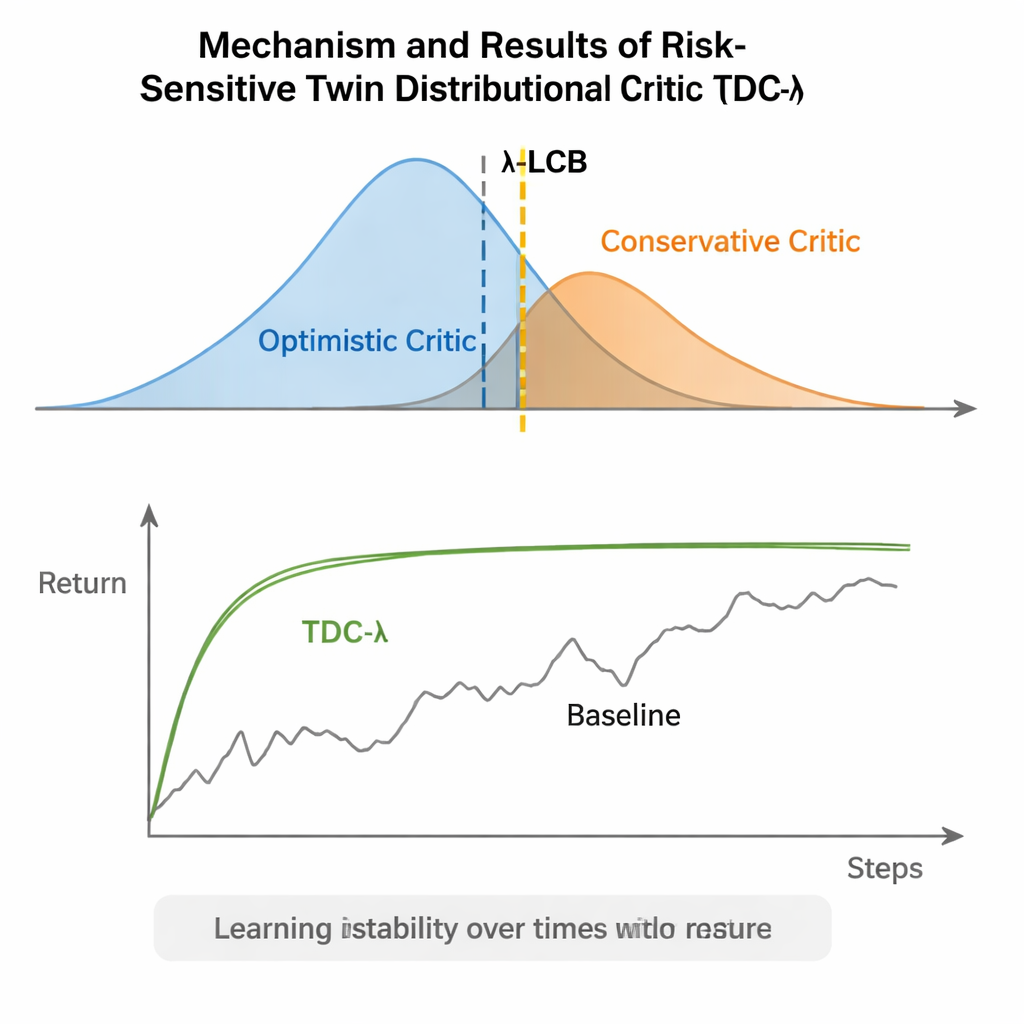
TDC-λ rozwiązuje ten problem, zmieniając sposób, w jaki agent ocenia swoją przyszłość. Zamiast przewidywać jedynie oczekiwaną nagrodę dla każdej akcji, uczy dwóch oddzielnych „krytyków”, z których każdy zwraca pełny rozkład możliwych przyszłych zwrotów. Z tych rozkładów algorytm oblicza nie tylko wynik średni, lecz także, jak bardzo rozproszone są możliwości. To rozproszenie odzwierciedla niepewność lub ryzyko. Korzystając z prostej reguły, ujętej jako dolny przedział ufności, TDC-λ wybiera krytyka, który przewiduje bezpieczniejszy wynik: taki, który może być nieco mniej optymistyczny, ale jest poparty bardziej spójnymi dowodami. Jedna regulacja — parametr ryzyka λ — płynnie dostraja, jak ostrożna jest ta selekcja: przy λ równym zero zachowanie przypomina konwencjonalny TD3, a wraz ze wzrostem λ staje się bardziej konserwatywne.
Jedna pętla treningowa, dwa sposoby działania
Kolejną praktyczną cechą TDC-λ jest to, że wspiera zarówno deterministyczne, jak i stochastyczne sposoby wyboru akcji w jednym spójnym schemacie. Podczas treningu można wybrać klasyczną politykę deterministyczną lub politykę Gaussowską ze zmiękczeniem tanh, która próbuje akcji losowo, wspierając eksplorację. Niezależnie od wyboru, podwójne krytyki dystrybucyjne są trenowane w ten sam sposób, a ewaluacja zawsze używa deterministycznej średniej akcji. Ten projekt wykorzystuje wcześniejsze obserwacje, że deterministyczne zachowanie w fazie testowej często daje wyniki równie dobre lub lepsze niż losowanie, przy jednoczesnym zachowaniu bogatych, sprzyjających eksploracji polityk podczas uczenia.
Przetestowanie metody
Autorzy ocenili TDC-λ na pięciu popularnych zadaniach benchmarkowych MuJoCo, gdzie symulowane roboty takie jak HalfCheetah, Hopper, Ant, Walker2d i Humanoid muszą nauczyć się poruszać sprawnie. W tych zadaniach nowa metoda osiągnęła porównywalną lub lepszą ostateczną wydajność niż silne punkty odniesienia, w tym TD3, DDPG, SAC oraz zaawansowane podejście oparte na przepływach zwane MEOW, przy czym konsekwentnie wykazywała niższą zmienność między powtórzeniami. W trudniejszych, wyższo-wymiarowych zadaniach, takich jak Humanoid, nieco wyższe wartości λ — oznaczające bardziej ostrożne estymaty docelowe — prowadziły do najlepszych długoterminowych zwrotów i najciaśniejszych pasm wydajności. Dodatkowe eksperymenty w innych symulatorach (PyBullet i NVIDIA Isaac) oraz diagnostyka śledząca zmienność sygnału uczenia wzmocniły wniosek, że TDC-λ czyni uczenie bardziej stabilnym bez spowalniania go.
Proste pokrętło dla bezpieczniejszego uczenia
Mówiąc prosto, TDC-λ daje systemom uczenia przez wzmacnianie „margines bezpieczeństwa” przy decydowaniu, ile ufać własnemu optymizmowi. Poprzez uczenie pełnych rozkładów możliwych wyników, a następnie preferowanie bezpieczniejszego krytyka za pomocą pokrętła λ, algorytm redukuje gwałtowne wahania w trakcie treningu, zachowując jednocześnie wysoką końcową wydajność. Dla praktyków to praktyczny sposób budowania bardziej niezawodnych sterowników dla robotów i innych systemów ciągłego sterowania: zacznij od umiarkowanie konserwatywnego λ i dostosuj go w zależności od tego, jak niestabilny wydaje się proces uczenia. Szersze przesłanie jest takie, że staranne kształtowanie celów, z których agent się uczy — jego docelowych estymat — może dostarczyć dużej części odporności często przypisywanej bardziej złożonym architekturom, czyniąc zaawansowane uczenie przez wzmacnianie bardziej stabilnym i dostępnym.
Cytowanie: Osman, O., Yalcin Kavus, B., Karaca, T.K. et al. Risk sensitive twin distributional critics with a lambda lower confidence bound for continuous control reinforcement learning. Sci Rep 16, 6699 (2026). https://doi.org/10.1038/s41598-026-37910-3
Słowa kluczowe: uczenie przez wzmacnianie, ciągłe sterowanie, uczenie wrażliwe na ryzyko, krytyki dystrybucyjne, robotyka