Clear Sky Science · pl
Zrównoważone i interpretowalne prognozowanie chorób serca: podejście wspomagające decyzje kliniczne dla zastosowań biomedycznych w opiece zdrowotnej
Dlaczego ważne są mądrzejsze badania serca
Choroby serca są główną przyczyną zgonów na świecie, a wielu ludzi dowiaduje się o ryzyku dopiero po poważnym zdarzeniu, takim jak zawał. Lekarze już zbierają proste pomiary — takie jak wiek, ciśnienie krwi, poziom cholesterolu i podstawowe wyniki badań — jednak przekucie tych informacji w szybkie i wiarygodne tak/nie dotyczące choroby serca jest trudne. W badaniu tym analizuje się nowy typ modelu komputerowego, który potrafi uczyć się na podstawie tych rutynowych wartości, przewidywać, kto prawdopodobnie ma chorobę serca z bardzo wysoką dokładnością, i co kluczowe — wyjaśniać swoje rozumowanie w sposób zrozumiały dla lekarzy.
Rosące obciążenie chorobami serca
Co roku choroby układu krążenia zabijają około 18 milionów osób na świecie. Wiele z tych zgonów można by uniknąć, gdyby pacjenci o wysokim ryzyku zostali wykryci wcześniej i leczeni szybciej. Tradycyjne testy diagnostyczne mogą być inwazyjne, kosztowne lub niewystarczająco dokładne w przypadkach granicznych. Równocześnie szpitale gromadzą teraz ogromne ilości danych cyfrowych o pacjentach — od wieku i płci po ciśnienie krwi, cholesterol i podstawowe odczyty z badań serca. Przekształcenie tego zalewu informacji w jasne i wiarygodne oszacowania ryzyka stało się jedną z największych szans — i wyzwań — współczesnej medycyny.
Od czarnych skrzynek do przejrzystych pomocników
W ostatnich latach sztuczna inteligencja pokazała obiecujące wyniki w wykrywaniu subtelnych wzorców w danych medycznych, których ludzie mogą nie dostrzegać. Jednak wiele potężnych modeli zachowuje się jak „czarne skrzynki”: mogą być dokładne, ale trudno wyjaśnić, dlaczego podjęły daną decyzję. Brak przejrzystości stanowi problem w medycynie, gdzie lekarze muszą uzasadniać diagnozy i wybory terapeutyczne. Autorzy wypełniają tę lukę, projektując system prognozowania chorób serca oparty na jednowymiarowej splotowej sieci neuronowej (1D CNN). W przeciwieństwie do starszych metod wymagających ręcznego definiowania, których cech szukać, ta sieć automatycznie odkrywa użyteczne wzorce w standardowych pomiarach pacjentów, a jednocześnie jest zaprojektowana tak, by być wystarczająco efektywną dla klinik o ograniczonych zasobach obliczeniowych.
Jak model uczy się z rutynowych badań
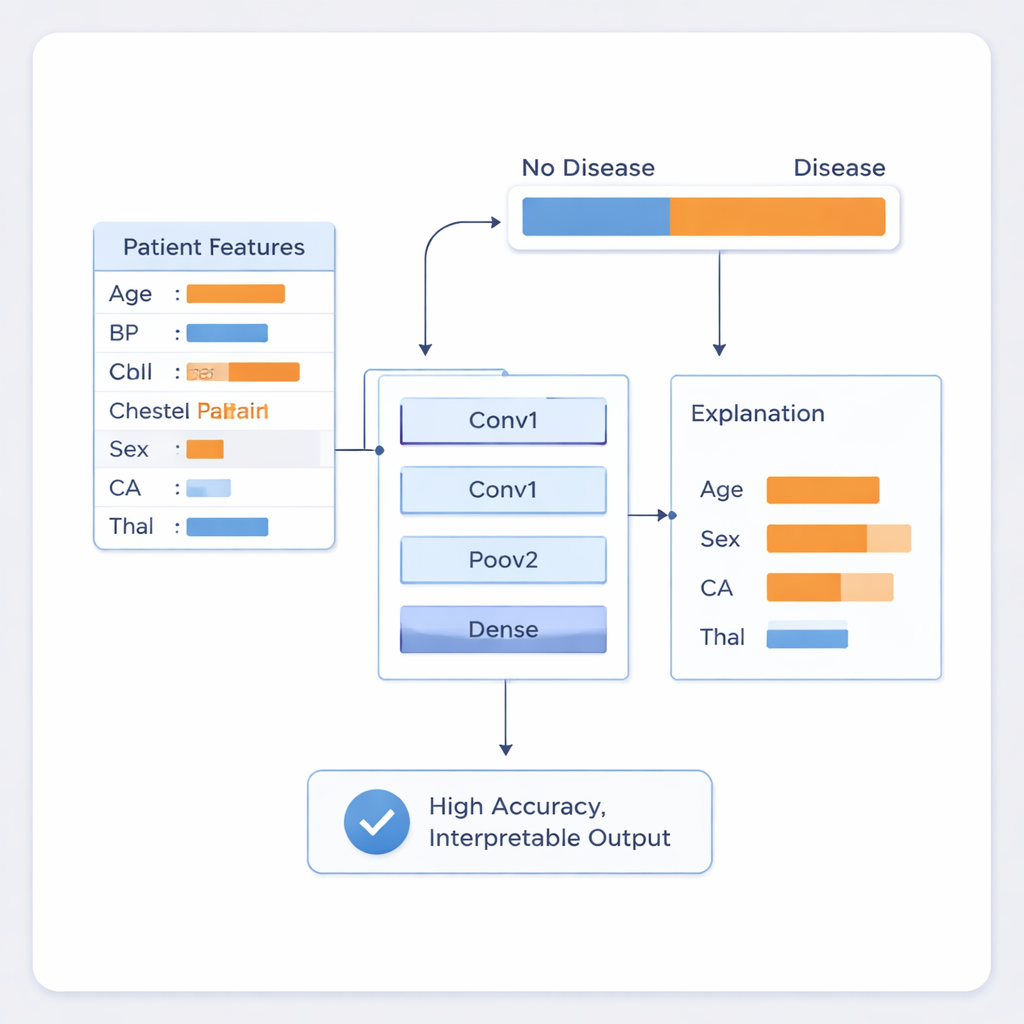
Naukowcy trenowali swój system na powszechnie używanym zbiorze danych o chorobach serca zawierającym 303 rekordy pacjentów, z których każdy zawiera 14 powszechnie zbieranych elementów, takich jak wiek, płeć, ciśnienie krwi, poziom cholesterolu, rodzaj bólu w klatce piersiowej i wyniki podstawowych badań serca. Dane zostały starannie przygotowane: wartości numeryczne znormalizowano, aby żaden pojedynczy pomiar nie dominował procesu uczenia, a kategorie, takie jak typ bólu w klatce piersiowej, przekształcono na formę numeryczną. Aby jak najlepiej wykorzystać stosunkowo mały zestaw danych i zasymulować naturalny szum rzeczywistych pomiarów klinicznych, zespół dodał niewielką ilość losowych wariacji do danych treningowych. Następnie rekordy te wprowadzono do zwartej architektury 1D CNN z dwiema głównymi warstwami wykrywającymi wzorce, po których następują warstwy łączące te wzorce w końcową prognozę „choroba” lub „brak choroby”.
Przekształcanie liczb w wiarygodne wyjaśnienia
Samo osiągi nie wystarczą w środowisku klinicznym, dlatego autorzy połączyli swój model z dwiema technikami wyjaśniania znanymi jako LIME i SHAP. Metody te badają wytrenowaną sieć, aby oszacować, jak bardzo każdy czynnik wejściowy przesuwa prognozę w stronę „choroby” lub „braku choroby” dla konkretnego pacjenta. W praktyce oznacza to, że system może powiedzieć lekarzowi nie tylko, iż pacjent znajduje się w grupie wysokiego ryzyka, ale też że na przykład wynik jest głównie spowodowany kombinacją płci, liczby zwężonych naczyń krwionośnych i zaburzenia krwi zwanego talasemią. Wyróżnione cechy zgadzają się z ustaloną wiedzą medyczną na temat czynników ryzyka chorób serca, co pomaga klinicystom ocenić, kiedy ufać modelowi, a kiedy go kwestionować.
Wyniki, które mogą trafić do codziennych klinik
Na danych testowych, których model wcześniej nie widział, poprawnie sklasyfikował stan choroby serca u około 98 na 100 pacjentów, osiągnął idealną precyzję w oznaczaniu przypadków choroby (w tej próbce nie wygenerował fałszywych alarmów) i wykazał niemal doskonałą zdolność rozróżniania chorych od zdrowych serc. Równie istotne, system był lekki: trenował się w kilka minut na standardowym sprzęcie w chmurze i dawał odpowiedzi w ułamku sekundy, co sugeruje, że mógłby działać na zwykłych szpitalnych komputerach zamiast na wyspecjalizowanych superkomputerach. Chociaż badanie opiera się na jednym historycznym zbiorze danych i będzie wymagać szerszych testów w różnych szpitalach i populacjach, wskazuje na przyszłość, w której dane z rutynowych badań, połączone z przejrzystą sztuczną inteligencją, mogą dać lekarzom wiarygodne „drugie zdanie” i pomóc wykrywać choroby serca wcześniej, zwłaszcza w warunkach ograniczonych zasobów opieki zdrowotnej.
Cytowanie: Kehkashan, T., Abdelhaq, M., Al-Shamayleh, A.S. et al. Sustainable and interpretable heart disease prediction: a clinical decision support approach for biomedical healthcare applications. Sci Rep 16, 7213 (2026). https://doi.org/10.1038/s41598-026-37840-0
Słowa kluczowe: prognozowanie chorób serca, wyjaśnialna sztuczna inteligencja, wspomaganie decyzji klinicznych, splotowe sieci neuronowe, analiza danych medycznych