Clear Sky Science · pl
Efektywne wykrywanie włamań w zbiorze danych TON-IoT przy użyciu hybrydowego podejścia do wyboru cech
Dlaczego ochrona inteligentnych urządzeń ma znaczenie
Miliardy codziennych urządzeń — od domowych kamer po czujniki fabryczne — komunikują się ze sobą przez internet, tworząc to, co nazywamy Internetem Rzeczy (IoT). Ta łączność przynosi wygodę i efektywność, ale też otwiera nowe możliwości dla hakerów. Artykuł tutaj streszczony dotyczy prostego, lecz kluczowego pytania: jak wiarygodnie wykrywać ataki w tych rozległych sieciach urządzeń, nie polegając na ciężkim, energochłonnym oprogramowaniu zabezpieczającym?
Problem wykrywania cyfrowych włamań
Aby badać ataki na systemy IoT, badacze często korzystają z dużych, publicznych zbiorów danych rejestrujących ruch sieciowy zarówno podczas normalnej pracy, jak i ataków. Jednym z najczęściej używanych jest zbiór ToN-IoT, który rejestruje rzeczywisty ruch z realistycznego stanowiska testowego przemysłowego, obejmując wiele rodzajów ataków, takich jak odmowa usługi, ransomware, łamanie haseł czy podsłuchiwanie typu man-in-the-middle. Autorzy pokazują jednak, że zbiór ten ma ukrytą pułapkę: wiele ataków prowadzono z ustalonych zakresów adresów IP i numerów portów. Oznacza to, że model może „oszukiwać”, ucząc się, kto jest atakującym, zamiast rozpoznawać prawdziwe złośliwe zachowanie. Takie modele mogą uzyskiwać bardzo wysokie wyniki w laboratorium, lecz zawodzić, gdy atakujący pojawi się z nowego adresu.
Z obszernego zestawu danych do skondensowanego obrazu zachowania
Oryginalne dane sieciowe ToN-IoT zawierają 44 różne miary dla każdego połączenia, od informacji o IP po detale ruchu webowego i szyfrowanego. Przetwarzanie wszystkich zwiększa czas obliczeń i zapotrzebowanie na pamięć, co stanowi problem dla małych bramek IoT i urządzeń brzegowych. Autorzy najpierw, korzystając ze zrozumienia mechaniki ataków, eliminują cechy, które są stronnicze (takie jak adresy IP i numery portów) lub mało pomocne w rozróżnianiu ataków. Twierdzą, że większość zagrożeń IoT ostatecznie objawia się jako nietypowe wzorce w liczbie wysyłanych i odbieranych pakietów i bajtów oraz w czasie trwania połączeń — bez względu na to, kto z kim się komunikuje. Ten pierwszy etap redukuje zbiór cech z 44 do siedmiu kluczowych statystyk ruchu związanych z woluminem i czasem trwania.
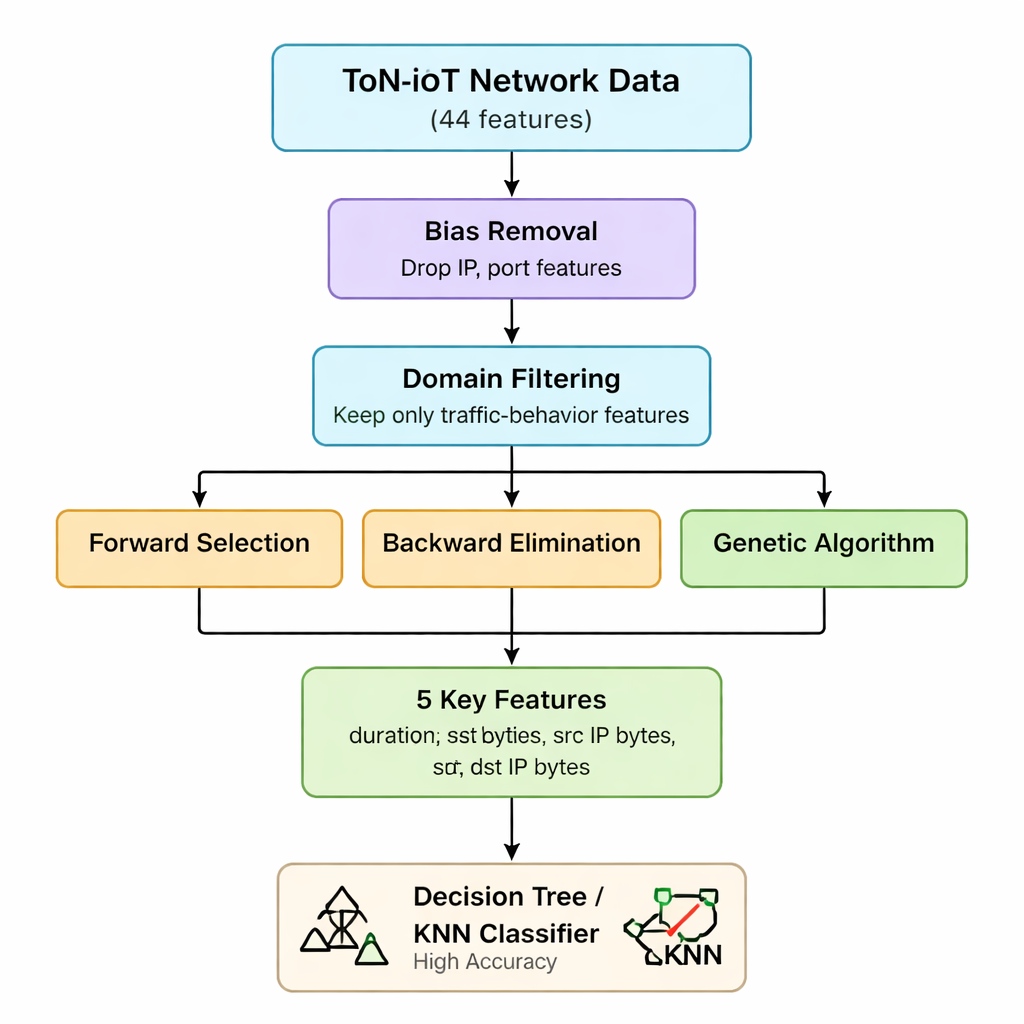
Hybrydowy wybór cech: trzy spojrzenia na te same dane
Następnie zespół stosuje trzy różne metody typu „wrapper”, które wielokrotnie trenują model, dodając, usuwając lub łącząc cechy, aby sprawdzić, który podzbiór ma największe znaczenie. Selekcja przyrostowa zaczyna od pustego zbioru i utrzymuje cechę tylko wtedy, gdy poprawia dokładność. Eliminacja wsteczna zaczyna od wszystkich siedmiu i usuwa cechy, których brak nie pogarsza dokładności. Algorytm genetyczny eksploruje wiele kombinacji równolegle, ewoluując lepsze podzbiory przez kolejne pokolenia. Wszystkie trzy metody testowane są za pomocą prostego klasyfikatora drzewa decyzyjnego, z dokładnością jako miarą oceny. Przecięcie wyników daje stabilne jądro pięciu cech: czas trwania połączenia, bajty wysłane, bajty odebrane oraz odpowiadające im liczniki bajtów na poziomie IP. Te pięć zmiennych efektywnie uchwytuje nietypowe skoki lub nierównowagi w ruchu, które sygnalizują wiele różnych typów ataków.
Lekki model, który dalej działa dobrze
Dzięki odchudzonemu, skoncentrowanemu na zachowaniu zestawowi danych badacze oceniają, jak dobrze proste modele uczenia maszynowego potrafią odróżnić ruch bezpieczny od ataków. Korzystając tylko z wybranych pięciu cech, drzewo decyzyjne osiąga 98,6% dokładności w klasyfikacji „atak vs normalny” oraz 97,2% dokładności przy rozróżnianiu między wieloma kategoriami ataków. Model k-najbliższych sąsiadów radzi sobie podobnie, a bardziej złożone metody zespołowe, takie jak lasy losowe czy gradient boosting, przynoszą tylko niewielkie poprawki kosztem większych wymagań obliczeniowych i pamięciowych. Co istotne, autorzy potwierdzają testami statystycznymi, że wybrane cechy są rzeczywiście informatywne, a nie artefaktami sposobu zbierania danych. Zauważają jednak, że subtelne ataki typu man-in-the-middle — zaprojektowane tak, by wtapiać się w normalne strumienie — pozostają trudniejsze do wykrycia, co sugeruje, że przyszłe prace mogą wymagać bogatszych wskazówek protokołowych lub czasowych dla takich przypadków.
Co to oznacza dla bezpieczeństwa w praktyce
Dla osób nietechnicznych główny wniosek jest taki, że nie zawsze potrzebne są masywne modele czy dziesiątki pomiarów technicznych, by chronić systemy IoT. Eliminując wskazówki działające tylko w jednej konfiguracji laboratoryjnej i skupiając się zamiast tego na garstce zachowań ruchu, autorzy pokazują, że proste, szybkie algorytmy mogą nadal wykrywać większość ataków z wysoką niezawodnością. Ich pięciocechowa wersja zbioru ToN-IoT jest łatwiejsza do przetwarzania na urządzeniach o ograniczonych zasobach na krawędzi sieci, co czyni ją praktyczną dla routerów, bramek i małych koncentratorów, które muszą reagować na zagrożenia w czasie rzeczywistym. Krótko mówiąc, badanie wskazuje drogę do bardziej godnego zaufania i łatwiejszego do wdrożenia wykrywania włamań dla codziennych inteligentnych urządzeń, które nas otaczają.
Cytowanie: Dharini, N., Janani, V.S. & Katiravan, J. Efficient detection of intrusions in TON-IoT dataset using hybrid feature selection approach. Sci Rep 16, 7763 (2026). https://doi.org/10.1038/s41598-026-37834-y
Słowa kluczowe: bezpieczeństwo IoT, wykrywanie włamań, uczenie maszynowe, wybór cech, ruch sieciowy