Clear Sky Science · pl
Modelowanie i zastosowanie predykcji złożonych cech choroby Alzheimera w oparciu o uczenie wielozadaniowe
Dlaczego te badania są ważne dla rodzin i pacjentów
Choroba Alzheimera to jedno z najbardziej obawianych rozpoznań naszych czasów, a lekarzom wciąż trudno przewidzieć, kto będzie szybko się pogarszał, kto pozostanie stabilny przez lata i które wczesne objawy naprawdę mają znaczenie. W tym badaniu postawiono proste, lecz mocne pytanie: jeśli spojrzymy jednocześnie na kilka wyników testów i skanów mózgu związanych z Alzheimerem i połączymy je z informacją genetyczną danej osoby, czy nowoczesna sztuczna inteligencja potrafi odnaleźć wzorce, które pomogą dokładniej prognozować przebieg choroby?
Wiele obliczy tej samej choroby
Alzheimer to nie tylko utrata pamięci. Pacjenci różnią się wynikami w testach poznawczych, zdolnością do radzenia sobie w codziennych czynnościach oraz obrazami w badaniach mózgu. Różne pomiary — takie jak powszechne skale pamięci i funkcji poznawczych, ankiety dotyczące funkcjonowania w życiu codziennym oraz skany PET pokazujące metabolizm mózgu czy nagromadzenie amyloidu — są częściowo zależne od genów. Co istotne, dzielą też pewne wspólne genetyczne podłoże. Tradycyjne metody predykcji zwykle skupiają się na jednym mierniku na raz, tracąc przy tym użyteczny fakt, że te cechy są powiązane. Autorzy argumentują, że podobnie jak lekarz widzący pełny obraz zamiast pojedynczego testu, modele powinny uczyć się z kilku cech jednocześnie.
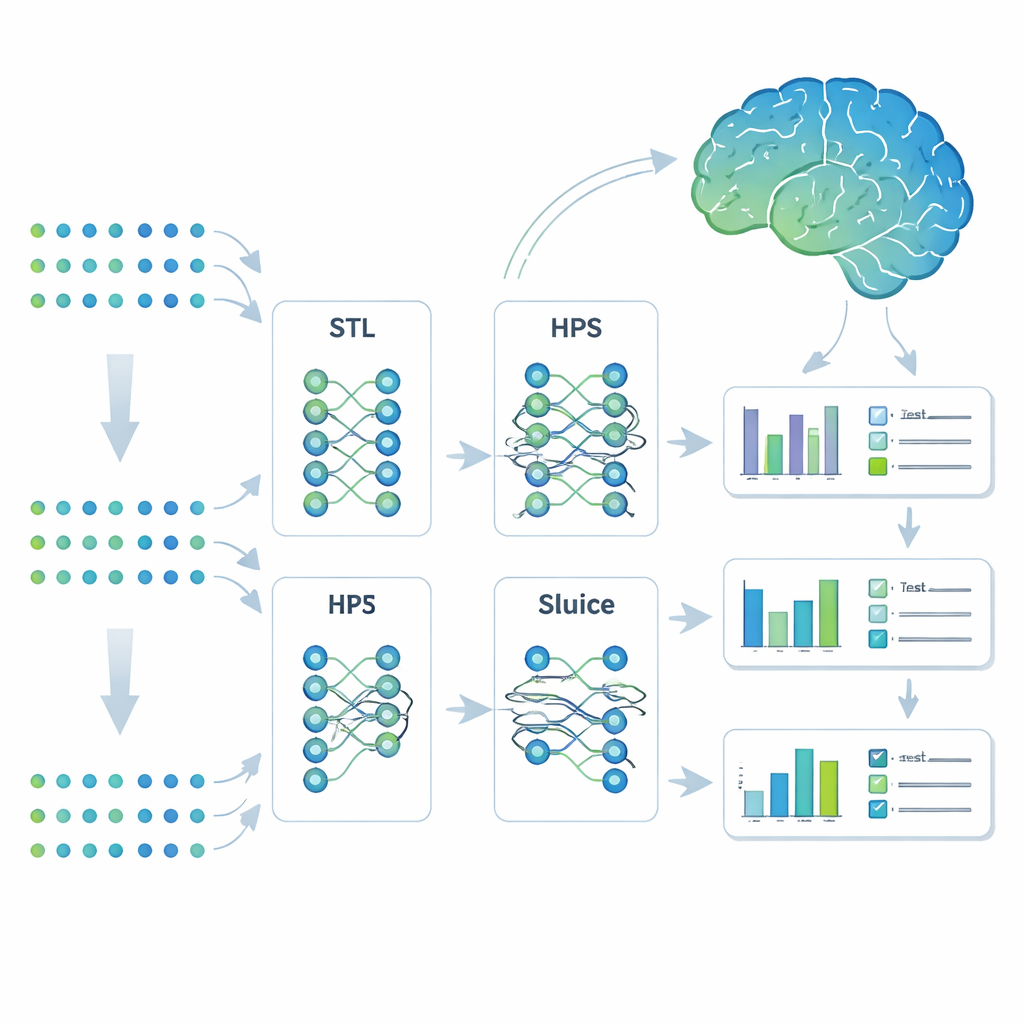
Nauczanie jednego modelu wielu powiązanych zadań
Naukowcy sięgnęli po strategię uczenia maszynowego zwaną uczeniem wielozadaniowym. Zamiast budować oddzielne modele dla każdego wyniku, wytrenowali jeden system do jednoczesnego przewidywania siedmiu cech związanych z Alzheimerem. Porównali cztery podejścia: całkowicie oddzielne modele (uczenie jednowarunkowe), prosty wspólny model rozdzielający tylko na końcu (hard parameter sharing), bardziej elastyczny projekt rozgałęziający, który może dzielić zadania na podgrupy, oraz wysoce adaptacyjny układ zwany Sluice Network, pozwalający dopasować, ile informacji jest współdzielone na każdej warstwie sieci. Wszystkie cztery modele otrzymywały te same dane genetyczne; różnica polegała na sposobie, w jaki dzieliły się tym, czego się nauczyły między poszczególne cechy.
Testowanie pomysłów na symulowanych genomach
Zanim zaufano któremukolwiek modelowi na prawdziwych pacjentach, zespół zbudował szczegółowe symulacje wykorzystując rzeczywiste wzorce genetyczne pochodzące z Alzheimer’s Disease Neuroimaging Initiative (ADNI), ale z wynikami, które mogli w pełni kontrolować. Stworzyli scenariusze, w których wszystkie cechy miały te same genetyczne przyczyny, w których cechy tworzyły nakładające się grupy oraz w których każda cecha miała odrębne przyczyny. Zmieniali też siłę sygnałów genetycznych i ilość dodanego szumu, naśladując chaotyczną rzeczywistość danych ludzkich. W niemal wszystkich warunkach Sluice Network dostarczał najdokładniejszych predykcji i pozostawał stabilny nawet wtedy, gdy cechy były słabo powiązane. Prostsze wspólne modele sprawdzały się dobrze, gdy cechy miały wiele wspólnych czynników genetycznych, ale słabły przy niskim poziomie współdzielenia, podczas gdy całkowicie oddzielne modele były stabilne, lecz ogólnie mniej dokładne.
Dane rzeczywiste i siła grupowania genów
Następnie autorzy zastosowali te modele do rzeczywistych danych ADNI z 463 osób, używając blisko 3800 znaczników genetycznych pochodzących z 56 genów wcześniej powiązanych z Alzheimerem. Tutaj wprowadzili biologicznie inspirowany zwrot: zamiast podawać tysiące pojedynczych znaczników genetycznych, najpierw pogrupowali markery według genów i pozwolili sieci nauczyć się zwartego „podsumowującego” sygnału dla każdego genu, zanim przewidzą siedem wyników. Agregacja na poziomie genów poprawiła wydajność większości modeli, a zwłaszcza Sluice Network, który mniej więcej podwoił przeciętną korelację z rzeczywistymi wynikami. Najwyraźniejsze korzyści zaobserwowano dla miar z obrazowania PET oraz niektórych wyników poznawczych i funkcjonalnych, co sugeruje, że subtelne efekty genetyczne stają się bardziej wykrywalne, gdy łączy się je na poziomie genów zamiast traktować jako izolowane markery.
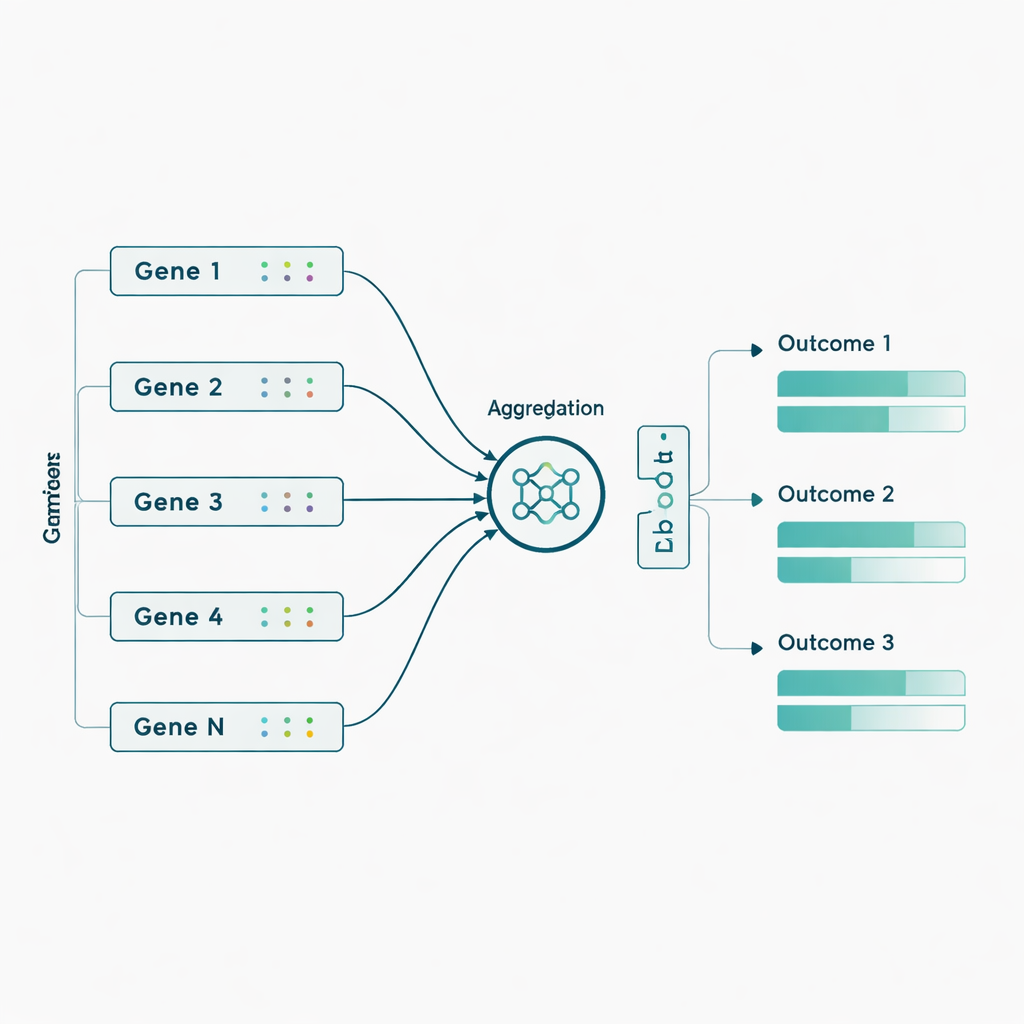
Co to oznacza dla przyszłej predykcji i opieki
Dla laika przekaz jest taki, że inteligentniejsze, bardziej elastyczne modele AI potrafią wydobyć więcej informacji z tych samych danych genetycznych i klinicznych, ucząc się z kilku powiązanych wyników jednocześnie i respektując biologiczną organizację w geny. Choć obecne zyski są umiarkowane i daleko do testu klinicznego, podejście wskazuje drogę do bardziej wiarygodnych narzędzi do szacowania profilu ryzyka osoby, śledzenia prawdopodobnego przebiegu choroby i być może dopasowywania monitoringu lub interwencji. W złożonych chorobach, takich jak Alzheimer, gdzie wiele niewielkich efektów genetycznych wchodzi ze sobą w interakcje, metody współdzielenia informacji między cechami i agregowania słabych sygnałów mogą dawać jaśniejszy, bardziej informacyjny obraz niż tradycyjne oceny jedna-cecha-na-raz.
Cytowanie: Zhou, W., Xue, Z., Liang, J. et al. Modeling and application of alzheimer’s disease complex trait prediction based on multi-task learning. Sci Rep 16, 7749 (2026). https://doi.org/10.1038/s41598-026-37820-4
Słowa kluczowe: Genetyka choroby Alzheimera, uczenie wielozadaniowe, predykcja głębokiego uczenia, biomarkery neuroobrazowe, agregacja na poziomie genów